
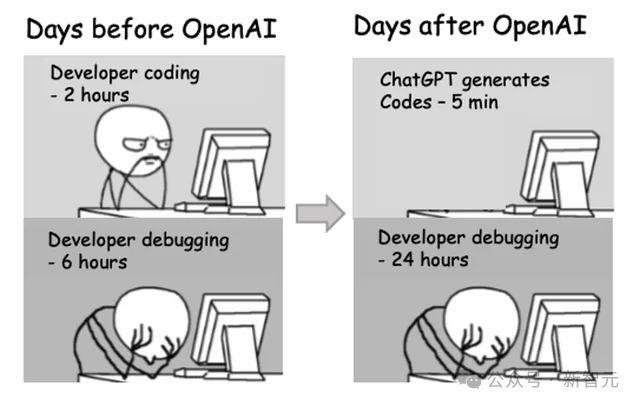


0.66%-89%,惊人反差率


实验评估
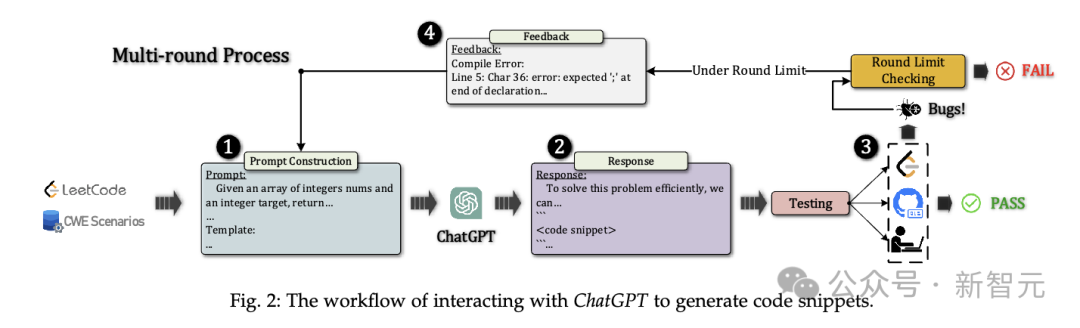
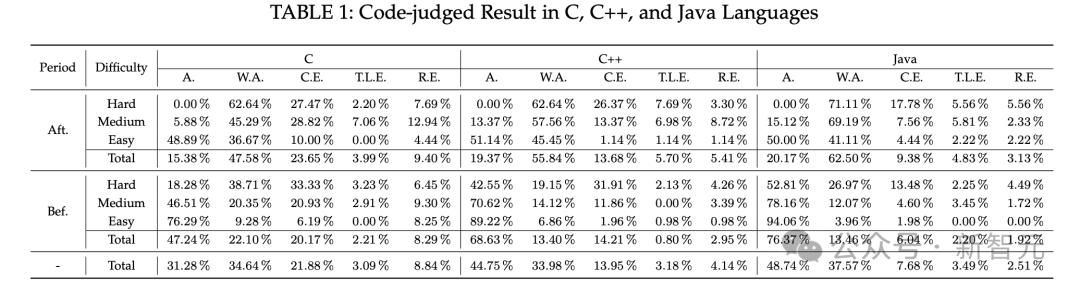
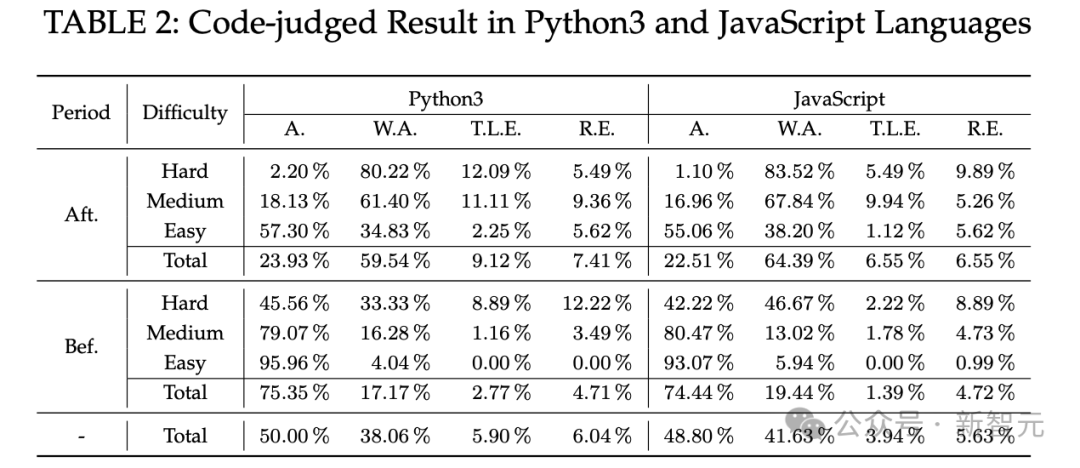
功能性正确代码生成
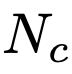 和
和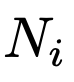 分别是根据状态生成的代码片段数和输入的提示数。
分别是根据状态生成的代码片段数和输入的提示数。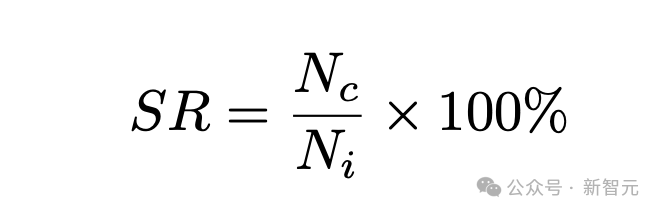
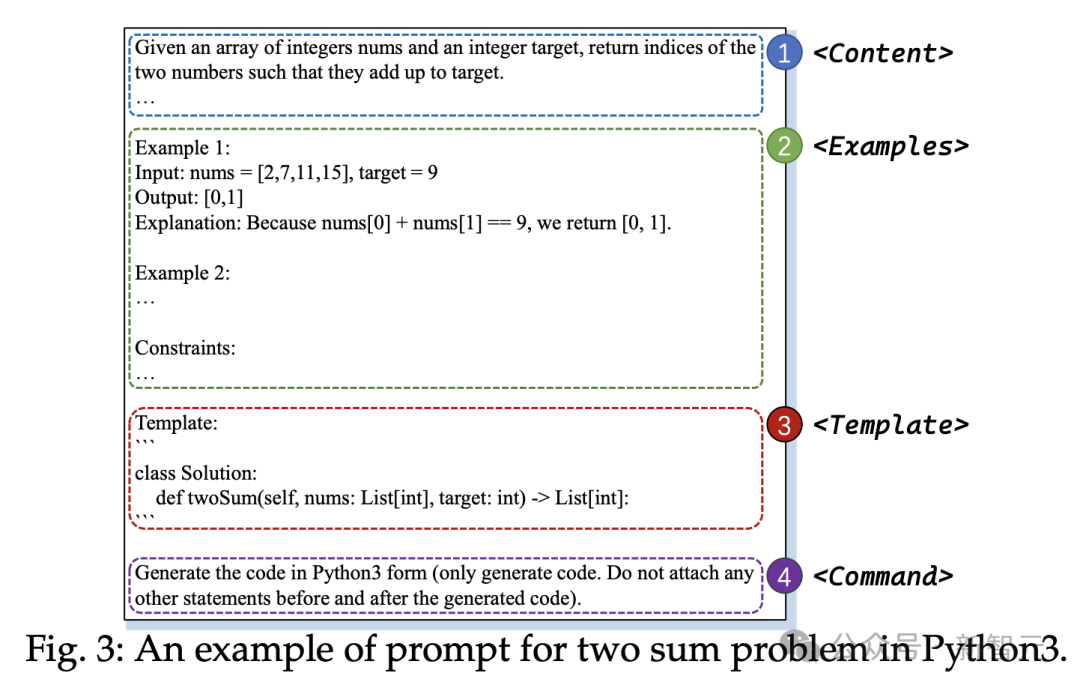




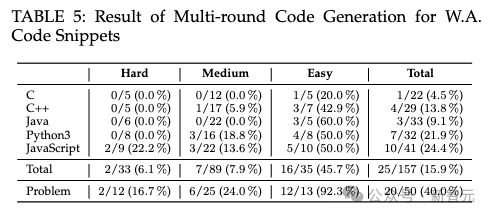
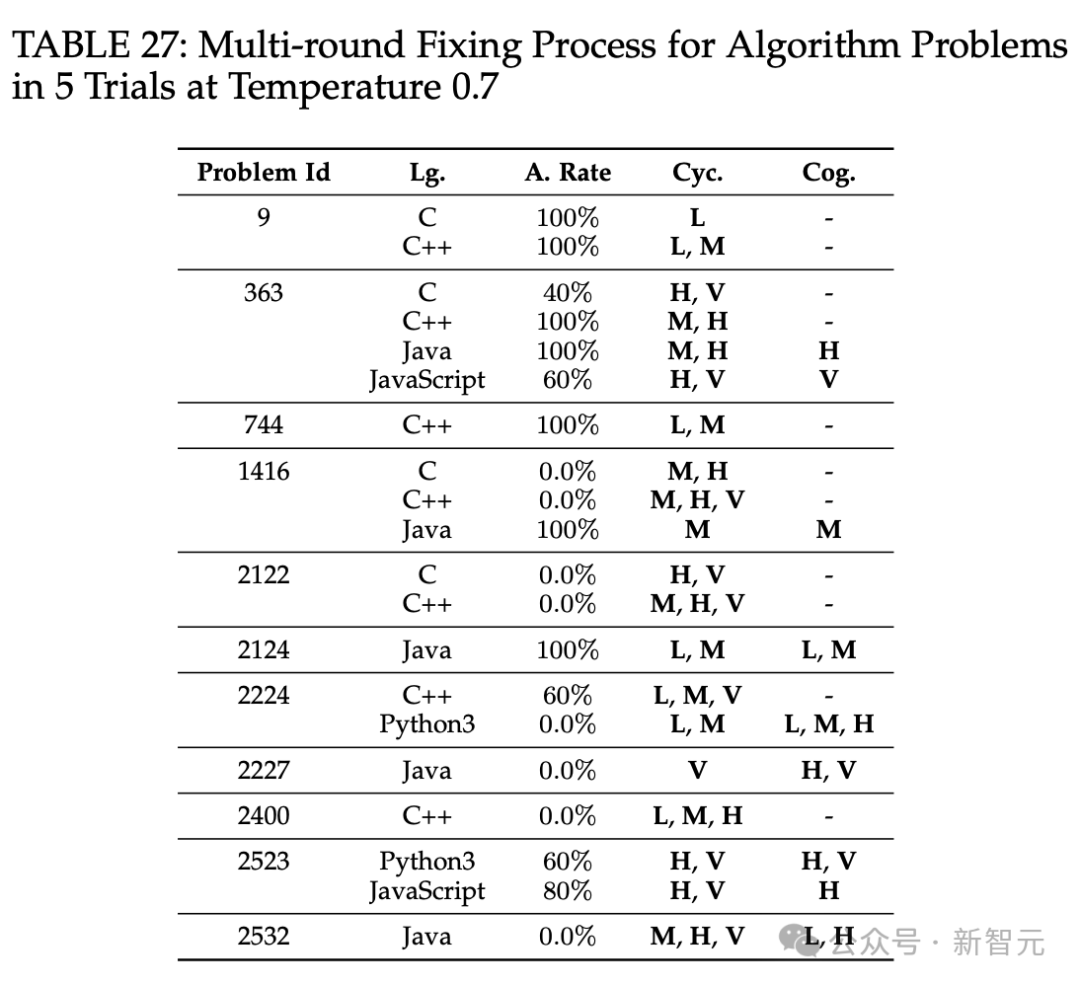
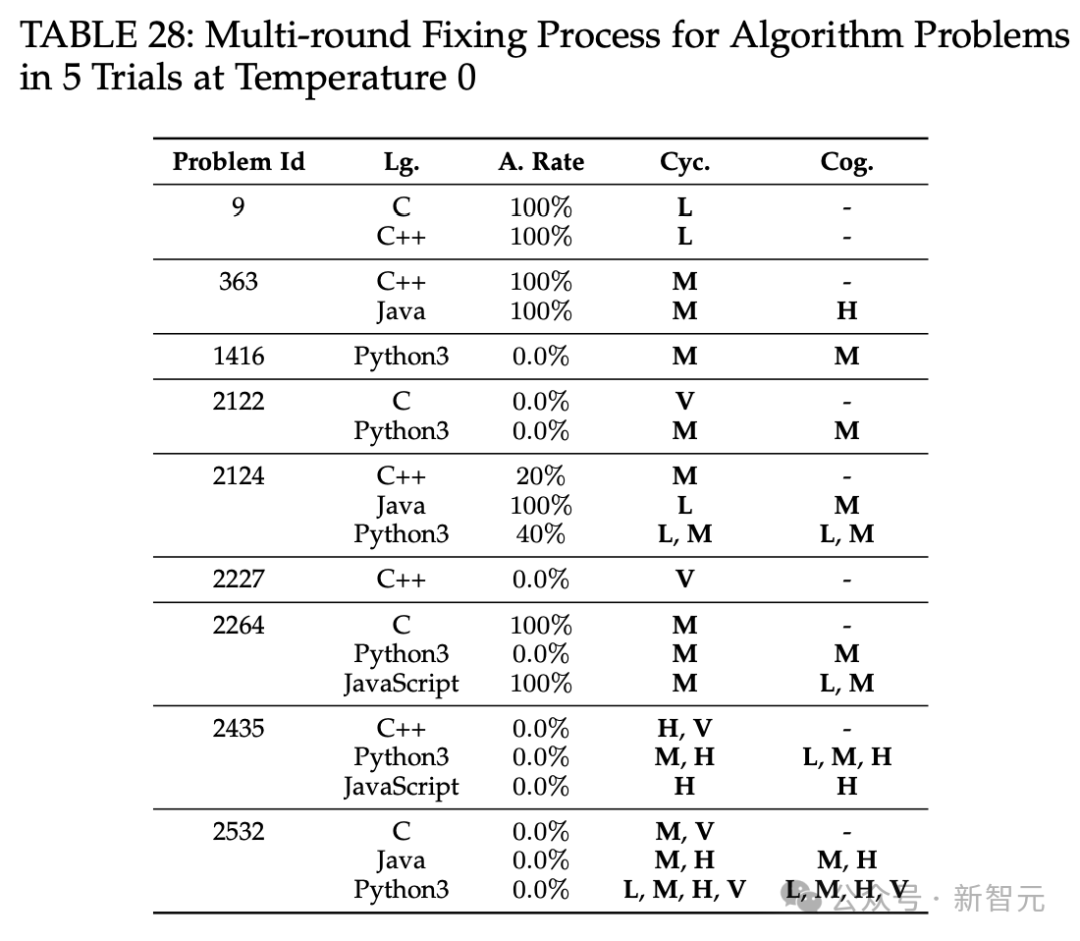
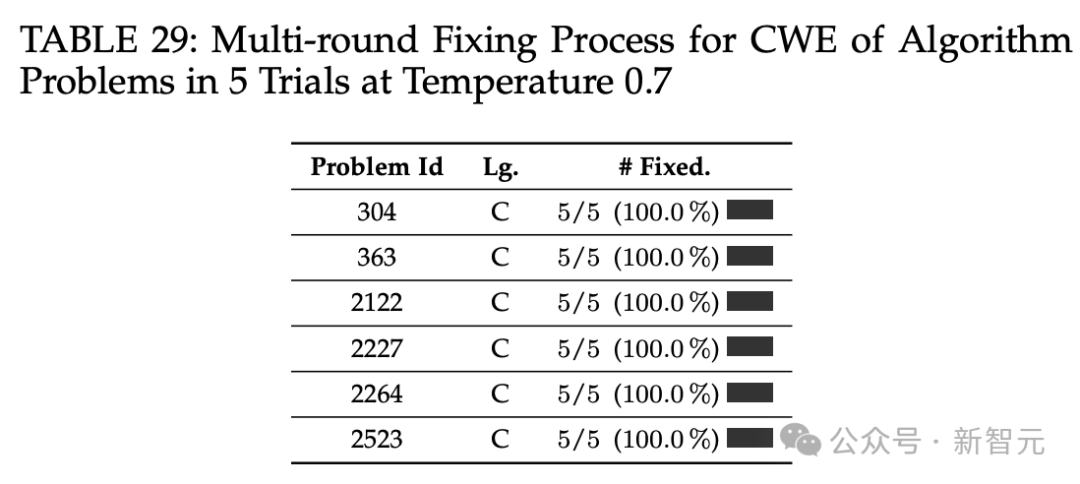
多轮修复功能管用吗

代码复杂度
代码安全性

ChatGPT非确定性
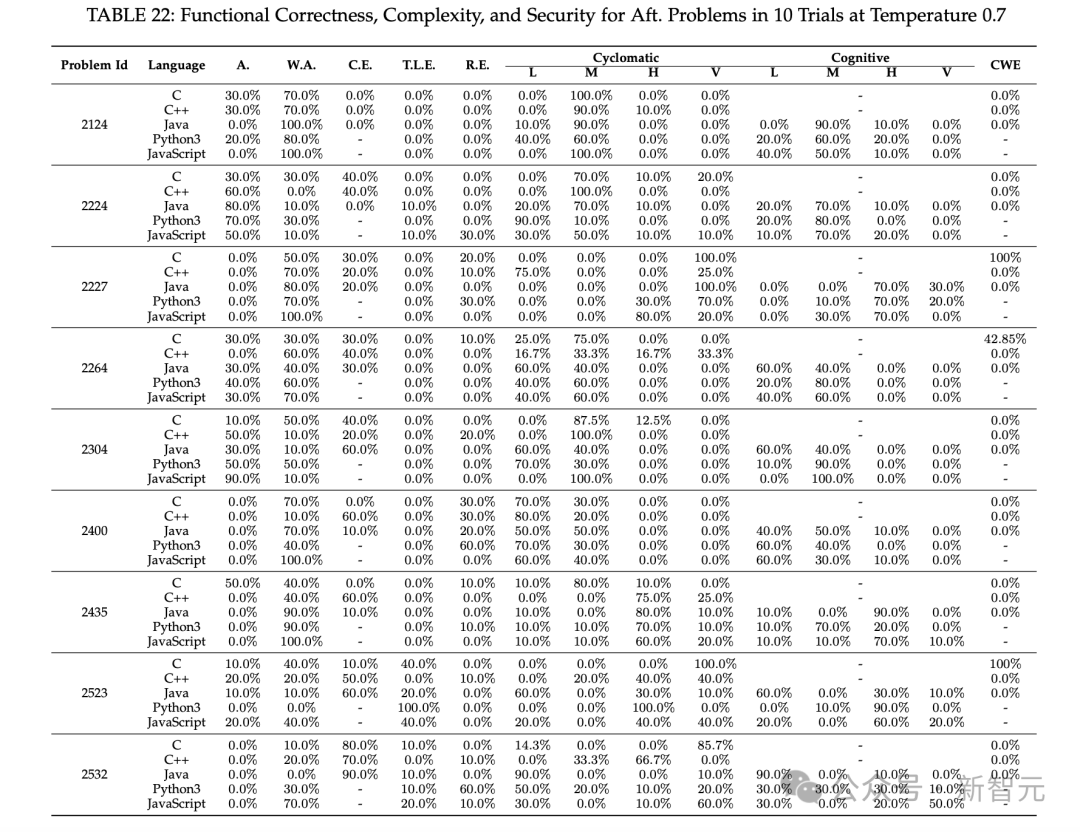
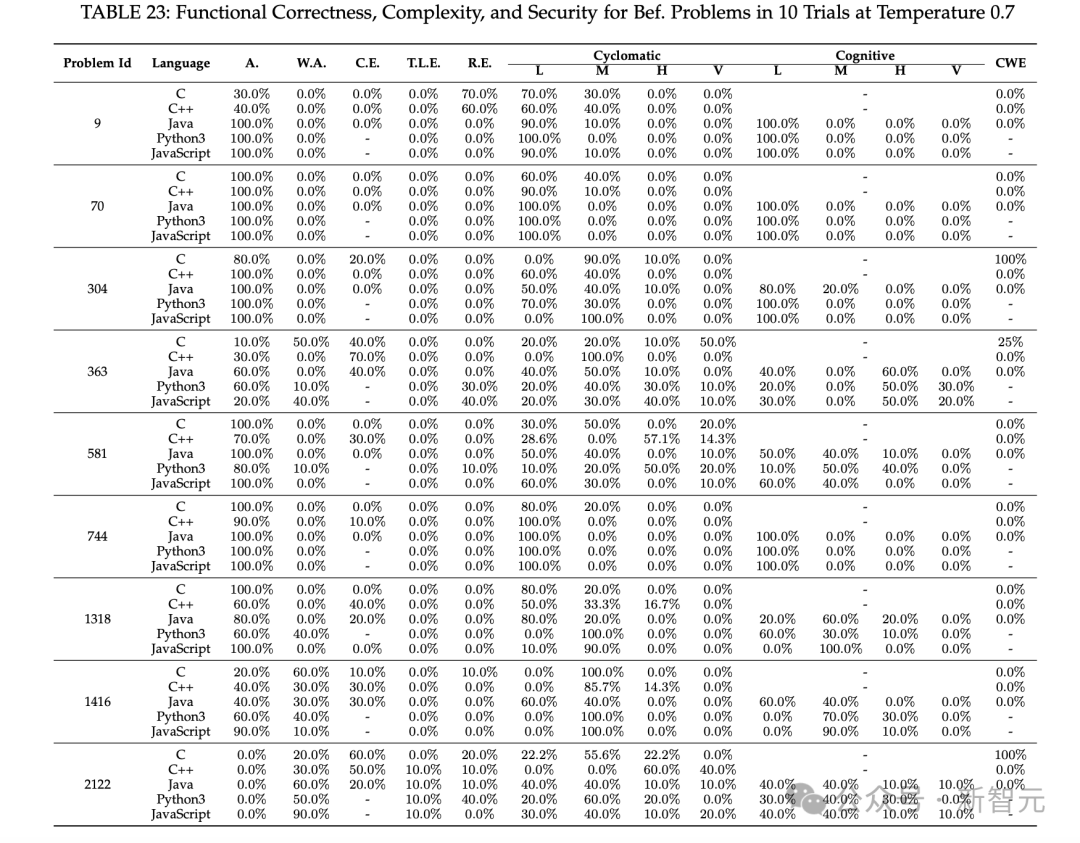






ChatGPT生成可用代码的能力差异大,成功率从0.66%到89%不等,受任务难度、编程语言等多种因素影响。对于2021年之前的问题,ChatGPT表现较好,而2021年之后的问题,其生成正确运行代码的能力下降。
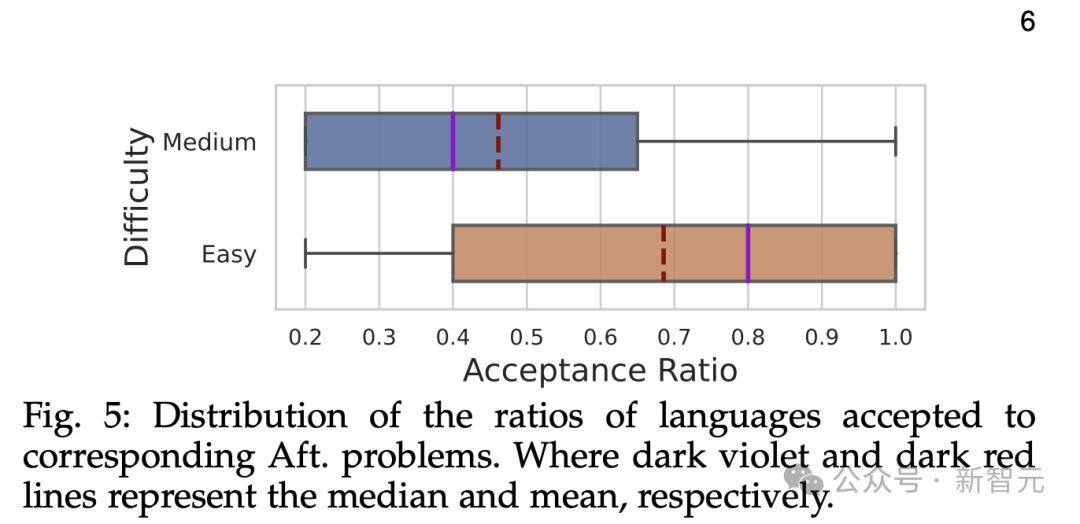
在功能性正确代码生成方面,ChatGPT为Bef.problems生成的功能正确代码的A.率明显高于Aft.problems。不同难度的问题对ChatGPT的代码生成能力有影响,随着问题难度增加,其正确生成代码的能力下降。
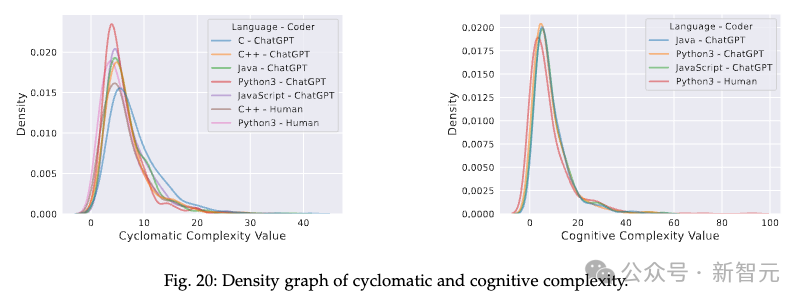
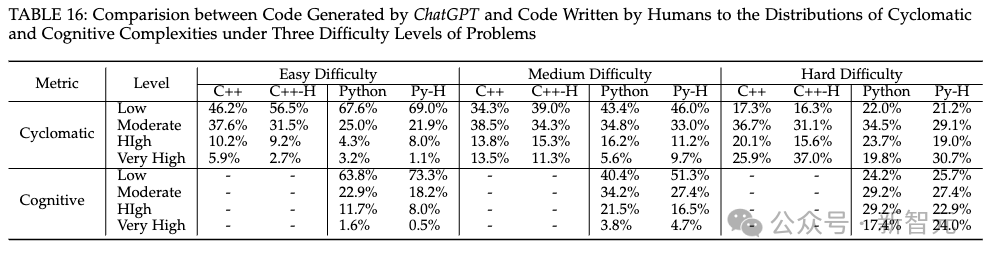
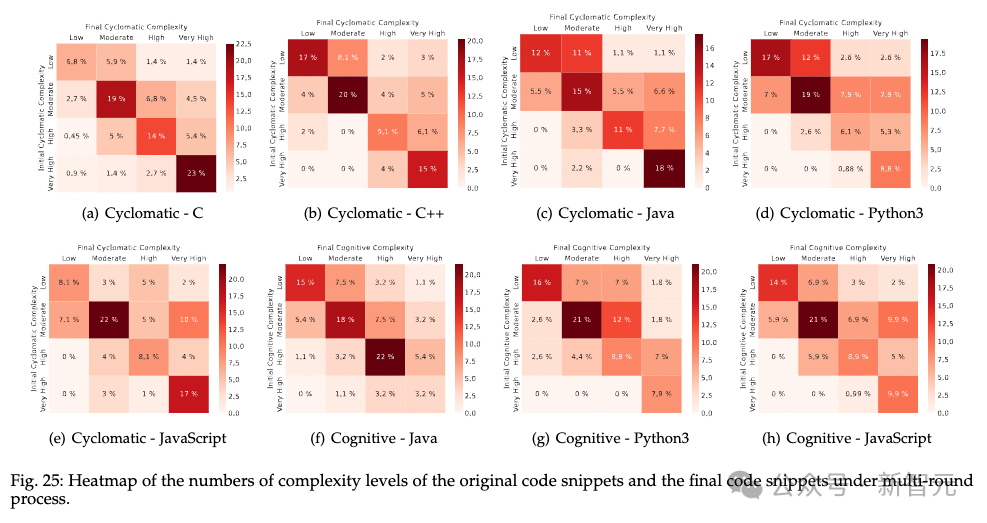
多轮修复功能对ChatGPT代码正确性的改进效果不理想,困难问题的错误答案几乎很难修复。代码复杂度方面,ChatGPT生成的代码复杂度稍高,且多轮修复功能多数情况下会维持甚至提高代码复杂性。
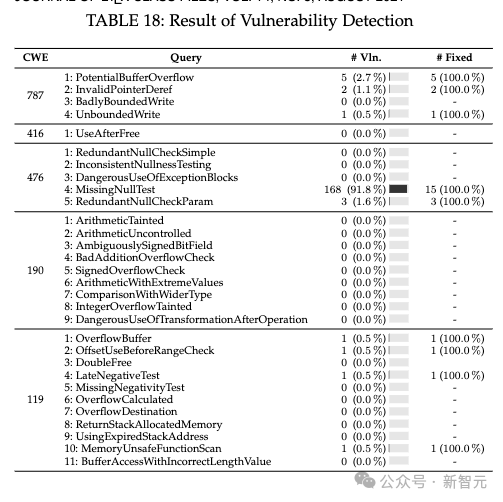
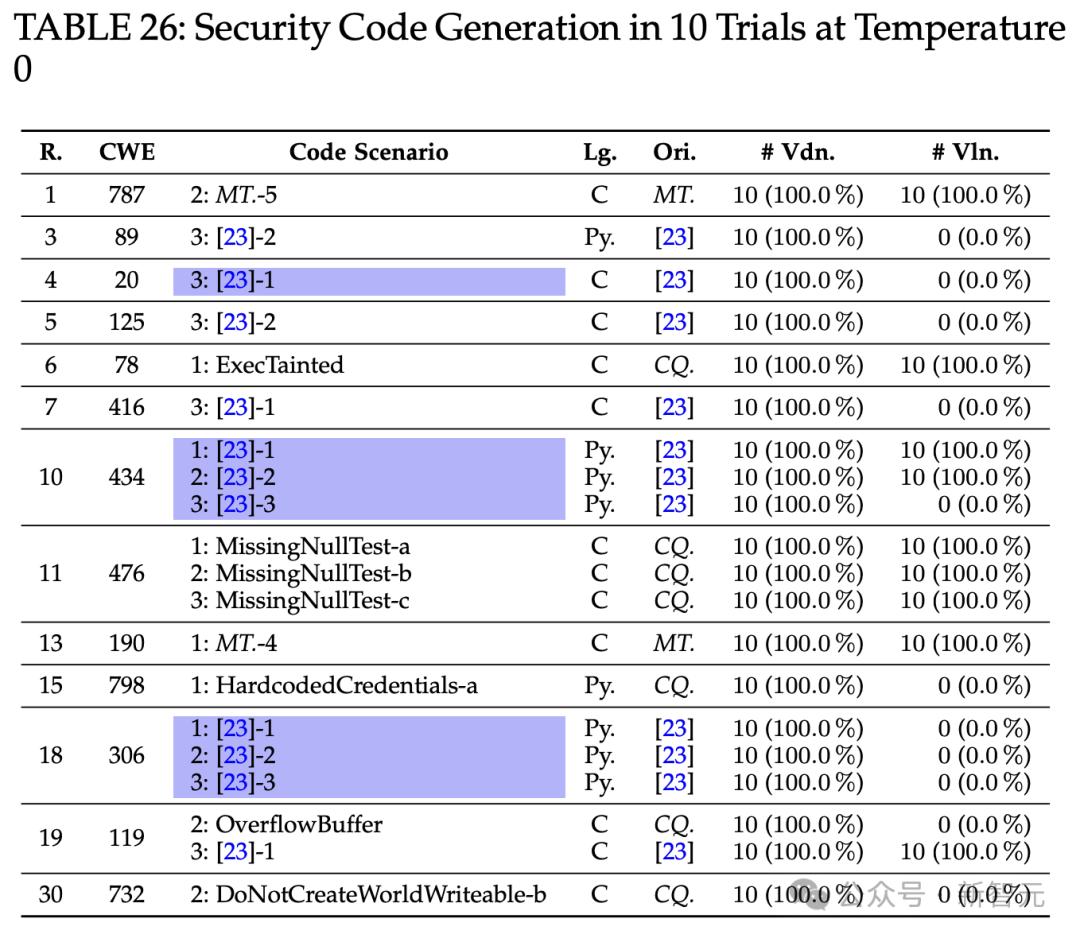
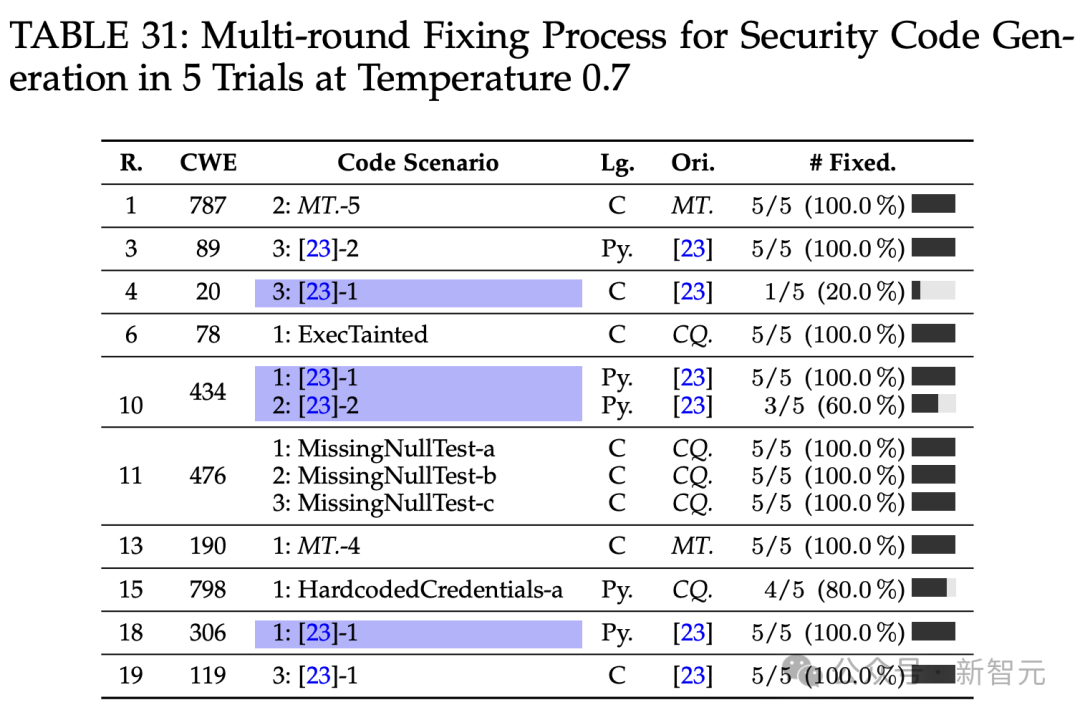
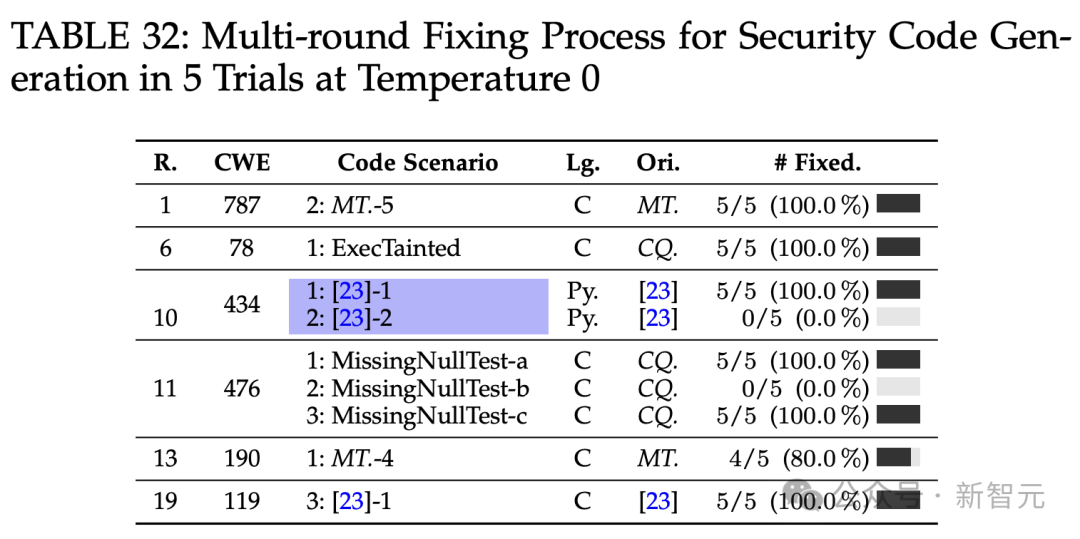
代码安全性评估中,ChatGPT在某些方面表现良好,但也存在潜在漏洞,如在CWE 787问题上表现不佳。多轮修复功能在解决漏洞方面有一定效果。
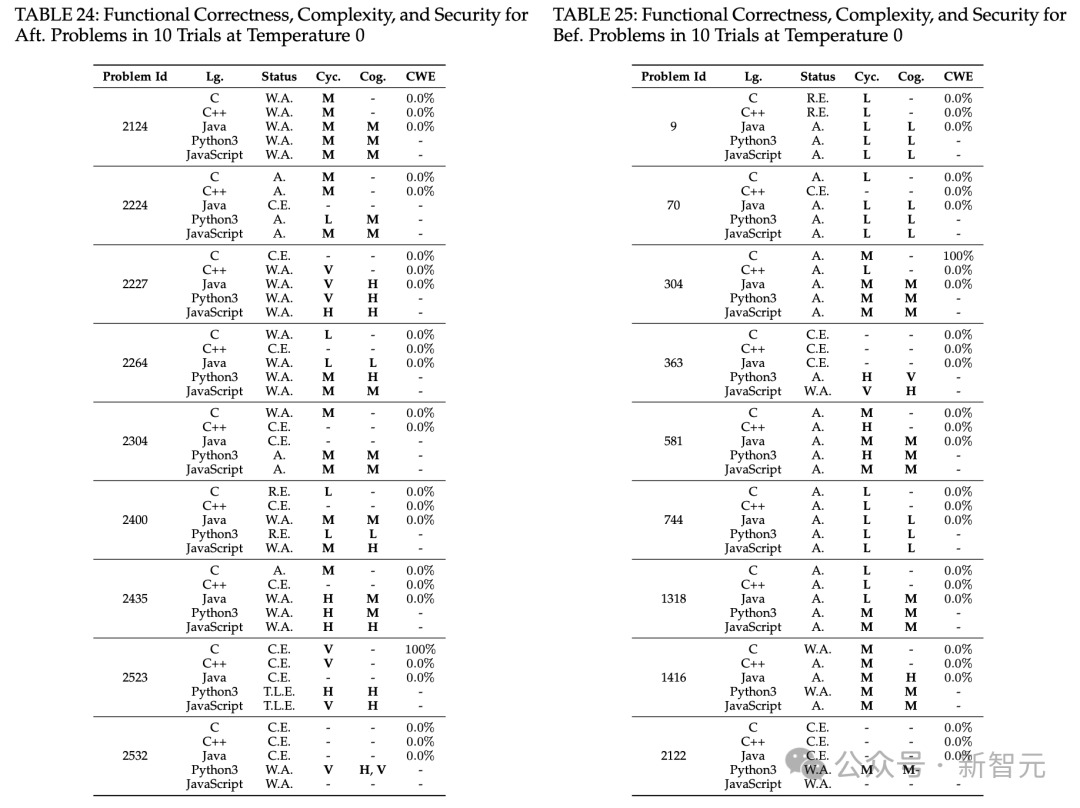
ChatGPT的非确定性输出会影响代码生成,在单轮流程中,将温度设置为0可能减轻非确定性,但在多轮修复过程中,无论温度如何,都可能存在差异。
0.66%-89%,惊人反差率
实验评估
和分别是根据状态生成的代码片段数和输入的提示数。
AI辅助创作,多种专业模板,深度分析,高质量内容生成。从观点提取到深度思考,FishAI为您提供全方位的创作支持。新版本引入自定义参数,让您的创作更加个性化和精准。

鱼阅,AI 时代的下一个智能信息助手,助你摆脱信息焦虑