小米MiMo研究团队开源了MiMo-7B系列模型,该模型通过优化预训练策略和强化学习训练,显著提升了小模型在数学和代码推理任务上的性能,甚至超越了32B模型。MiMo-7B系列模型包括基础模型、SFT模型以及RL模型,为开发强大的推理LLM提供了新的思路和实践。研究团队提供了详细的模型评估、推理、部署和微调方法,方便社区使用和进一步研究。
💡 MiMo-7B系列模型是小米MiMo研究团队开发的,专注于提升小模型在数学和代码推理任务上的性能。
🔑 为了提升模型推理能力,研究团队针对推理任务定制预训练策略,包括优化数据预处理流程、增强文本提取工具包和应用多维度数据过滤等。
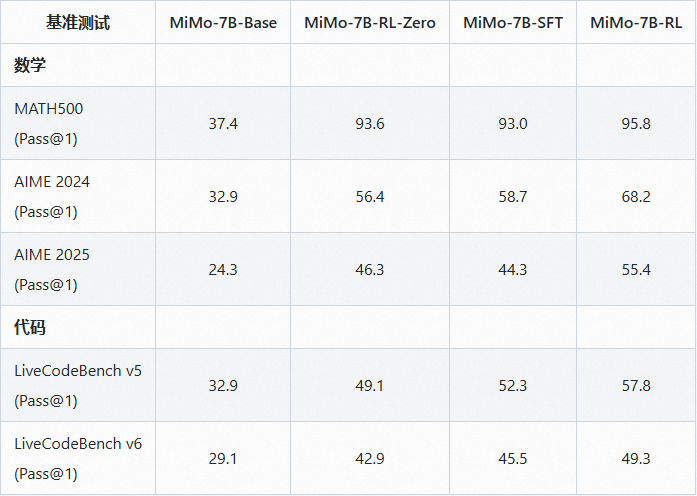
🚀 MiMo-7B-Base模型在约25万亿个token上进行预训练,并采用了三阶段的数据混合策略。通过强化学习,MiMo-7B-RL模型在数学推理和代码生成能力上得到了提升,性能可与OpenAI o1-mini模型媲美。
🛠️ 研究团队开源了MiMo-7B系列模型,包括基础模型、SFT模型以及RL模型,并提供了模型推理、部署和微调的详细说明,方便社区使用和进一步研究。
2025-05-12 19:04 浙江
小米MiMo研究团队开源了MiMo-7B系列模型,通过优化预训练策略和强化学习训练,显著提升了小模型在数学和代码推理任务上的性能,甚至超过32B模型,为开发强大推理LLM提供了新思路。

目前,大多数成功的 强化学习 工作,包括开源研究,都依赖于相对较大的基础模型,例如 32B 模型,特别是在增强代码推理能力方面。业内普遍认为在一个小模型中同时提升数学和代码能力是具有挑战性的。然而,小米MiMo研究团队认为RL训练的推理模型的有效性取决于基础模型固有的推理潜力。为了完全解锁语言模型的推理潜力,不仅需要关注后训练,还需要针对推理定制预训练策略。
MiMo-7B是一系列从零开始训练并为推理任务而生的模型。MiMo-7B-Base 的RL实验表明,MiMo-7B模型具有非凡的推理潜力,甚至超过了更大的 32B 模型。此外,研究团队在冷启动的 SFT 模型上进行了 RL 训练,生成了 MiMo-7B-RL,旨在通过强化学习(RL)提升数学推理和代码生成能力。模型的设计目标是解决复杂任务,特别是在长上下文理解和多步推理方面表现出色,与 OpenAI o1-mini 的性能相匹配。
研究团队开源了 MiMo-7B 系列模型,包括基础模型、SFT 模型、从基础模型训练的 RL 模型以及从 SFT 模型训练的 RL 模型的Checkpoint。 研究团队相信这份报告及这些模型将为开发强大的推理 LLM 提供有价值的见解,从而造福更广泛的社区。
模型亮点
研究团队精心挑选了 130K 个数学和代码问题作为强化学习训练数据,这些问题可以通过基于规则的验证器进行验证。每个问题都经过仔细清理和难度评估,以确保质量。仅使用基于规则的准确性奖励来避免潜在的奖励漏洞。
研究团队开发了一个Seamless Rollout引擎,以加速强化学习训练和验证。集成了连续rollout、异步奖励计算和提前终止,以最小化 GPU 空闲时间,实现了 2.29倍的训练速度和1.96倍的验证速度。
模型结构
MiMo-7B 的 MTP 层在预训练和 SFT 期间进行调优,并在强化学习期间冻结。使用一层 MTP 进行推测解码时,接受率约为 90%。
模型链接:
https://modelscope.cn/collections/MiMo-7edb0ab729c744
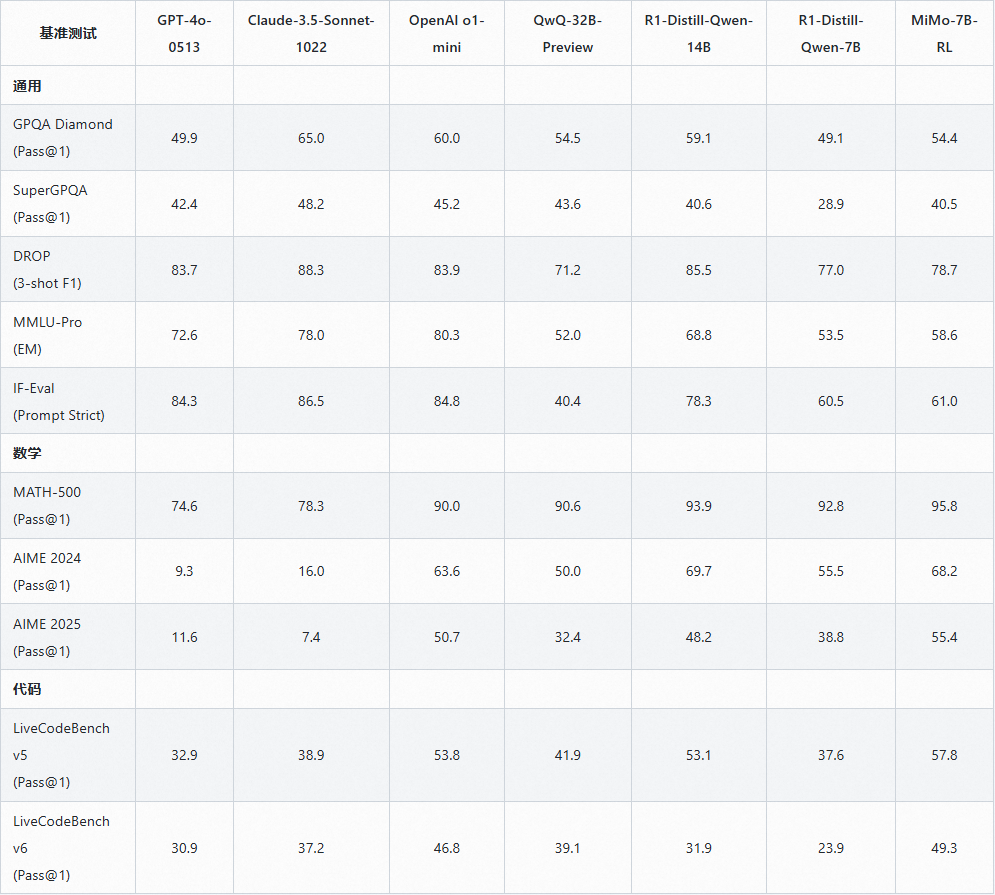
模型评估
MiMo-7B 系列
注:
评估是在 temperature=0.6 的条件下进行的。
AIME24 和 AIME25 是基于 32 次重复的平均得分。LiveCodeBench v5 (20240801-20250201),LiveCodeBench v6 (20250201-20250501),GPQA-Diamond 和 IF-Eval 是基于 8 次重复的平均得分。MATH500 和 SuperGPQA 是单次运行的结果。
模型推理
使用transformers推理
from modelscope import AutoModel, AutoModelForCausalLM, AutoTokenizermodel_id = "XiaomiMiMo/MiMo-7B-Base"model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)tokenizer = AutoTokenizer.from_pretrained(model_id)inputs = tokenizer(["Today is"], return_tensors='pt')output = model.generate(**inputs, max_new_tokens = 100)print(tokenizer.decode(output.tolist()[0]))
模型部署
SGLang 推理部署
感谢 SGLang 团队的贡献(https://github.com/sgl-project/sglang/pull/5921),研究团队在 24 小时内支持了 SGLang 主流中的 MiMo,MTP 即将到来。
示例脚本
python3 -m uv pip install "sglang[all] @ git+https://github.com/sgl-project/sglang.git/@main#egg=sglang&subdirectory=python"SGLANG_USE_MODELSCOPE=true python3 -m sglang.launch_server --model-path XiaomiMiMo/MiMo-7B-RL --host 0.0.0.0 --trust-remote-code
模型微调
ms-swift已经支持了MiMo-7B系列模型的微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。ms-swift开源地址:https://github.com/modelscope/ms-swift
我们将展示可运行的微调demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
自定义数据集格式如下,指定--dataset <dataset-path>即可开始训练:
# 通用格式{"messages": [ {"role": "system", "content": "<system-prompt>"}, {"role": "user", "content": "<query1>"}, {"role": "assistant", "content": "<response1>"}]}# 思考数据集格式{"messages": [ {"role": "user", "content": "浙江的省会在哪"}, {"role": "assistant", "content": "<think>\n...\n</think>\n\n浙江的省会在杭州。"}]}
以 XiaomiMiMo/MiMo-7B-RL 模型为例,使用自我认知数据集进行训练。由于自我认知数据集不含思考链路,可以通过在训练时指定--loss_scale ignore_empty_think忽略<think>\n\n</think>\n\n的损失计算,缓解模型推理能力的下降。
CUDA_VISIBLE_DEVICES=0 \swift sft \ 'swift/self-cognition:empty_think#500' \
训练显存占用:
训练效果展示:
训练完成后,使用以下命令对训练后的权重进行推理,这里的`--adapters`需要替换成训练生成的last checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 \swift infer \
推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \swift export \ --adapters output/vx-xxx/checkpoint-xxx \ --push_to_hub true \ --hub_model_id '<your-model-id>' \ --hub_token '<your-sdk-token>'
点击阅读原文,即可跳转模型~


阅读原文
跳转微信打开

