index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
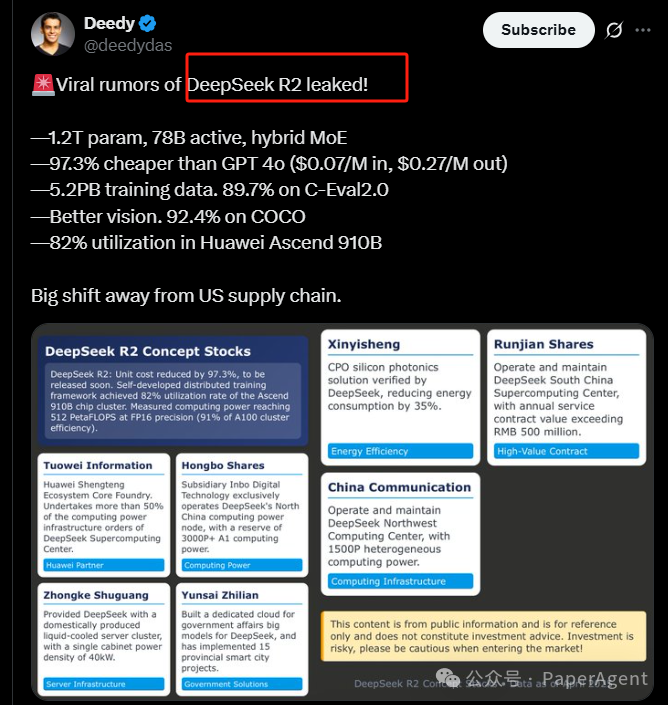
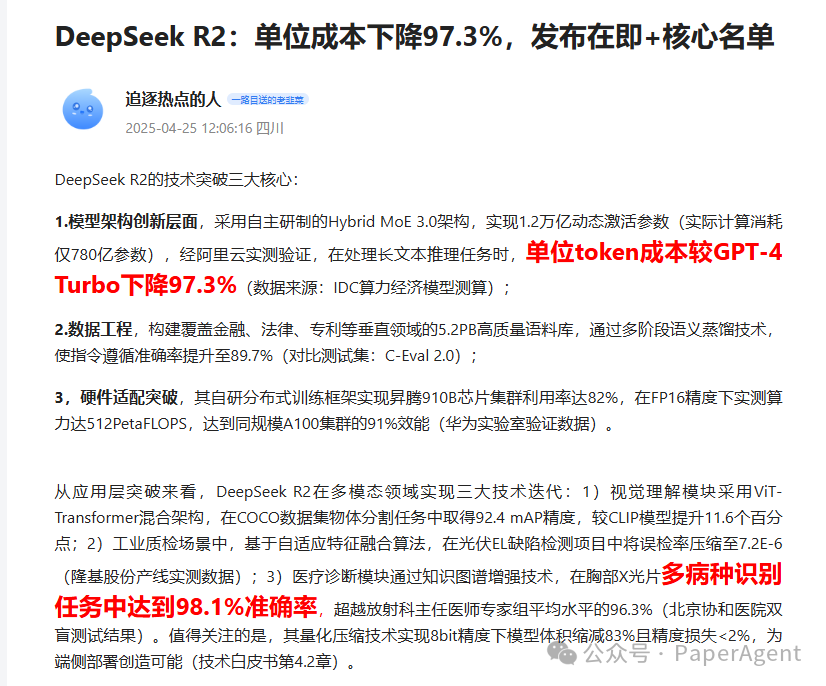
DeepSeek R2的信息泄露,揭示了其强大的性能和极具竞争力的价格。该模型拥有1.2T参数,78B激活,采用混合MoE架构,据称成本比GPT-4o低97.3%。它在C-Eval 2.0上达到89.7%的准确率,在COCO数据集上达到92.4%的视觉准确率。此外,DeepSeek R2在华为昇腾910B芯片上利用率高达82%。如果泄露信息属实,这将对大模型领域产生巨大影响,引发关于AI Agent设计、RAG技术以及多模态Agent系统发展的深入思考。
⚙️DeepSeek R2采用混合MoE架构,拥有1.2T参数和78B激活,显著降低了成本,据称比GPT-4o便宜97.3%,百万输入成本为0.07美元,百万输出成本为0.27美元。
📊DeepSeek R2在多个数据集上表现出色,在C-Eval 2.0上达到89.7%的准确率,展现了强大的语言理解能力;在COCO数据集上达到92.4%的准确率,突显了其卓越的视觉能力。
🚀DeepSeek R2在华为昇腾910B芯片上实现了82%的利用率,表明其在国产硬件上的优化程度较高,具有良好的部署潜力。
2025-04-27 18:56 湖北

1.2T参数,78B激活,混合MoE架构
比GPT-4o便宜97.3%(每百万输入0.07美元,每百万输出0.27美元)
5.2PB训练数据,在C-Eval 2.0上达到89.7%的准确率
更好的视觉能力,在COCO数据集上达到92.4%的准确率
在华为昇腾910B芯片上达到82%的利用率
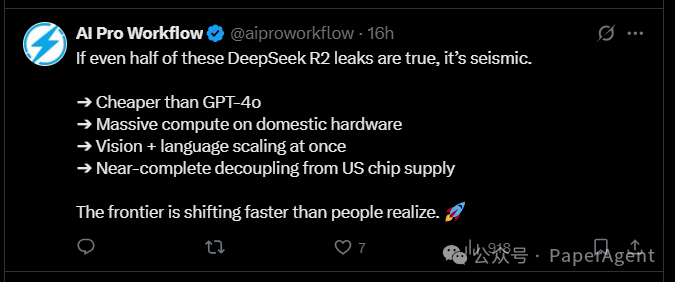
有网友表示如果这些关于DeepSeek R2的信息有一半是真的,那将是震撼性的:更多信息:《动手设计AI Agents:CrewAI版》、《高级RAG之36技》、新技术实战:中文Lazy-GraphRAG/Manus+MCP/GRPO+Agent、大模型日报/月报、最新技术热点追踪解读(GPT4-o/数字人/MCP/Gemini 2.5 Pro)
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。

阅读原文
跳转微信打开

