WebThinker是一个由推理模型驱动的开源深度研究框架,旨在增强大型推理模型(LRMs)在复杂研究任务中的能力。它使LRMs能够自主进行网络搜索、网页导航和报告写作,从而提升其在复杂真实场景下的可靠性。WebThinker通过深度网页探索、自主的“思考-搜索-写作”策略以及基于强化学习的训练,实现了在解决复杂问题和生成全面研究报告方面的显著提升,为构建更强大的深度研究系统奠定了基础。
🌐 **深度网页探索:** WebThinker的核心在于其“深度网页探索器”,使模型能够超越传统搜索的限制,自主决定搜索查询,并通过网页导航深入挖掘信息,直至收集到足够信息并返回精炼总结。
✍️ **自主“思考-搜索-写作”策略:** WebThinker将报告撰写与模型的思考和搜索过程深度融合,模型可以实时写作、修改报告内容,而不是在所有搜索完成后一次性生成。配备专门的工具集(写作、检查当前报告、编辑内容),确保报告的连贯性并能适应新发现。
🚀 **基于强化学习的训练策略:** 通过迭代式的在线直接偏好优化(DPO)训练,提升LRM对研究工具的利用效率。构建偏好数据集,优先选择能得出正确答案/高质量报告且工具使用更高效的推理路径。
📊 **实验效果显著:** WebThinker在多个高难度基准上表现出色,例如在GPQA、GAIA、WebWalkerQA和Humanity's Last Exam等任务中,WebThinker(基于QwQ-32B)显著超越了仅依赖内部知识的直接推理模型,以及各种RAG基线方法。
💡 **未来发展方向:** WebThinker计划扩展多模态深度搜索与报告生成、开发更全面的工具、基于GUI的网页探索以及知识图谱构建与推理,旨在打造更全面、智能、实用的深度研究助手。
2025-05-08 11:48 湖北

摘要
近年来,大型推理模型(LRMs)如OpenAI-o1等在长链推理方面展现了强大能力。然而,它们依赖静态的内部知识,在面对复杂、知识密集型任务以及需要综合多样网络信息生成全面研究报告时常显不足。为应对此挑战,来自中国人民大学、北京智源人工智能研究院(BAAI)、华为泊松实验室等机构的研究者提出了 WebThinker——一个深度研究智能体。WebThinker能够赋能LRM在推理过程中自主进行网络搜索、网页导航和研究报告的写作,显著提升其在复杂真实场景下的可靠性与应用性,为构建更强大、更通用的深度研究系统奠定了基础。
Paper: https://arxiv.org/abs/2504.21776
GitHub: https://github.com/RUC-NLPIR/WebThinker
Demo:
2025年我能投稿哪些AI顶会?
OpenAI有哪些模型?它们有什么区别?
研究动机:解锁LRM的深度研究潜力
大型推理模型(LRMs)通过长思维链的方式,在数学、编码和科学等复杂领域展现出逐步推理的能力,这种"慢思考"模式增强了推理的逻辑性和可解释性。然而,这些模型的一大局限在于其知识的静态性。当面对需要广泛、动态的外部知识才能解决的复杂研究问题时,它们难以进行深入的网络信息探索,也难以自主生成内容详实、论据充分的研究报告。现有的开源深度搜索智能体通常采用预定义工作流,这限制了LRM深层探索网络信息的潜力,也阻碍了LRM与搜索引擎之间的紧密互动。
在真实世界的研究场景中,用户不仅需要问题答案,更常常需要一份完整的、定制化的研究报告。传统模型和标准检索增强生成(RAG)方法难以满足这种深度和广度的需求。因此,学术界和工业界都迫切需要一个通用、灵活的开源深度研究框架,能够让LRM在推理的同时自主探索网络、挖掘信息、并实时撰写和调整报告内容。
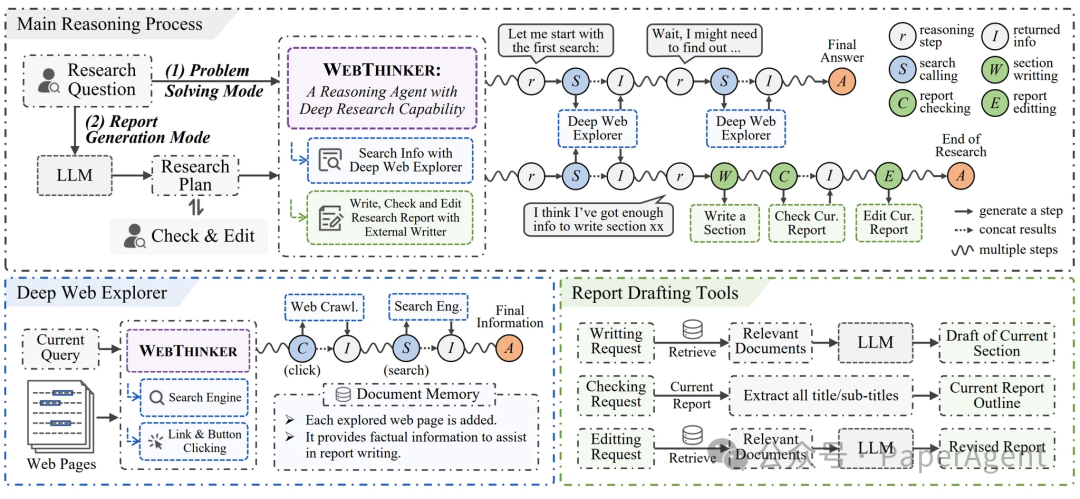
WebThinker:自主的深度搜索与报告写作
针对上述挑战,我们引入了 WebThinker,一个完全由推理模型驱动的开源深度研究框架。它使LRM能够:
自主决策LRM在推理过程中自主判断何时需要外部知识,何时需要更新报告。深度探索当需要信息时,调用"深度网页探索器"进行多步搜索和页面导航。动态撰写收集到足够信息后,LRM指示助手LLM(负责具体文本操作)使用"写作"、"编辑"等工具撰写或修改报告的特定章节。所有探索到的网页内容会存入文档记忆库,供报告撰写时参考。LRM持续思考、探索新信息、并优化报告,直至任务完成。
WebThinker主要通过两种模式运行:
问题解决模式 (Problem-Solving Mode)为LRM配备"深度网页探索器",使其能够深入探索网络以解决复杂问题。报告生成模式 (Report Generation Mode)进一步赋予LRM写作、检查和编辑能力,使其能够在思考和搜索的同时,迭代式地撰写全面的研究报告。
核心组件
深度网页探索 (Deep Web Explorer):
模型可以自主决定搜索查询,并通过点击链接、按钮等交互元素在网页间导航,深入挖掘信息。
自主"思考-搜索-写作"策略 (Autonomous Think-Search-and-Draft Strategy):
模型可以实时写作、修改报告内容,而不是在所有搜索完成后一次性生成。配备专门的工具集(写作、检查当前报告、编辑内容),确保报告的连贯性并能适应新发现。
基于强化学习的训练策略 (RL-based Training Strategies):
通过迭代式的在线直接偏好优化(DPO)训练,提升LRM对研究工具(包括搜索、导航、报告撰写工具)的利用效率。构建偏好数据集,优先选择能得出正确答案/高质量报告且工具使用更高效的推理路径。
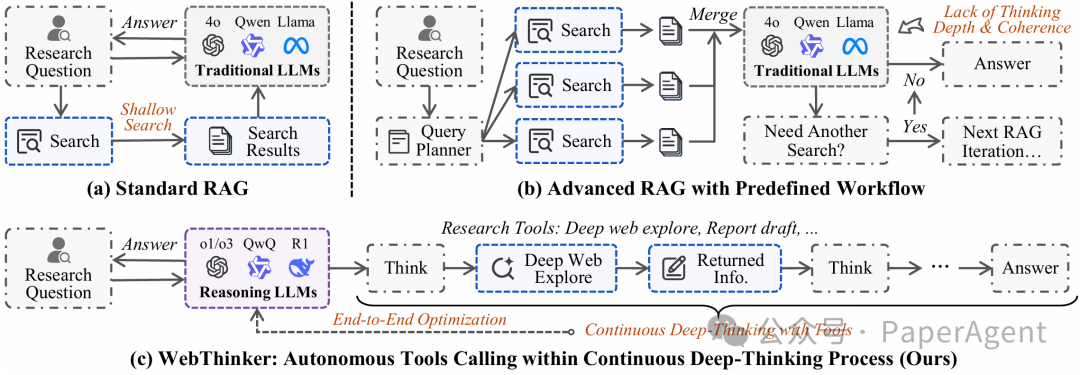
与传统RAG框架的对比
WebThinker与传统的检索增强生成(RAG)框架有着本质区别。下图展示了三种不同范式的对
标准RAG工作流遵循固定的"检索-生成"流程,模型无法自主决定何时需要信息,也无法深入探索网页内容。迭代式RAG工作流允许多轮检索,但仍然按照预定义的流程运行,缺乏真正的自主性。WebThinker完全由推理模型驱动,在单次生成中实现端到端任务执行。模型可以在思考过程中自主决定何时搜索、如何导航网页、何时撰写报告内容,真正实现了思考、探索和撰写的一体化。
实验效果
我们在多个高难度基准上对WebThinker进行了全面评估:
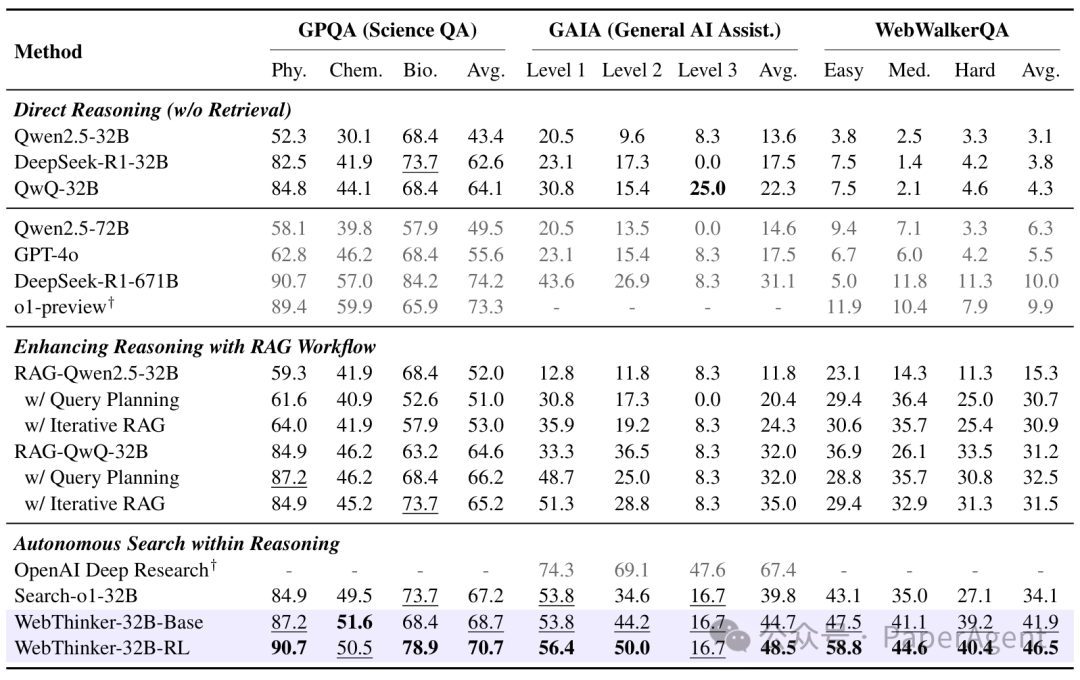
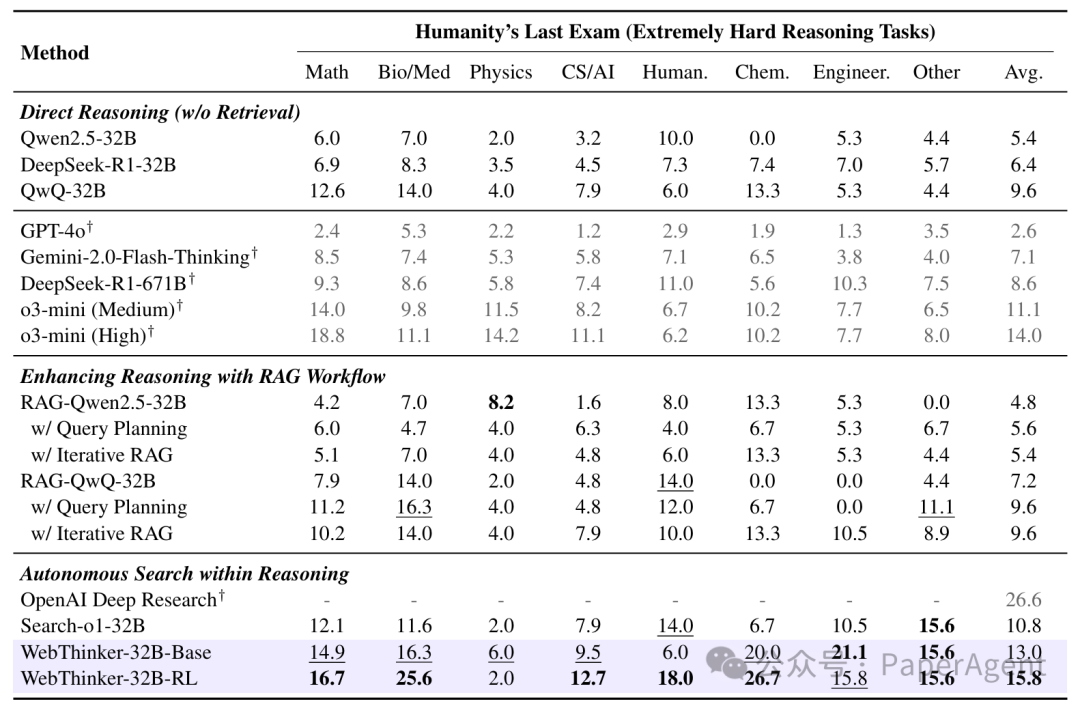
1. 真实世界的复杂推理任务:
在包括GPQA(博士级科学问答)、GAIA(通用AI助手)、WebWalkerQA(深度网络探索问答)和Humanity's Last Exam (HLE)(极高难度综合推理)等任务上:
WebThinker(基于QwQ-32B)显著超越了仅依赖内部知识的直接推理模型,以及各种RAG基线方法。相较于如Search-o1等先进的自主搜索模型,WebThinker凭借其"深度网页探索器"和更优的策略,在各项基准上均取得更佳表现。例如,在WebWalkerQA和HLE上分别平均提升约22.9%和20.4%(对比Search-o1)。经过RL优化的WebThinker-32B-RL版本在32B模型中达到了SOTA水平,甚至在HLE上超越了一些更强的专有系统。
2. 科学研究报告生成任务:
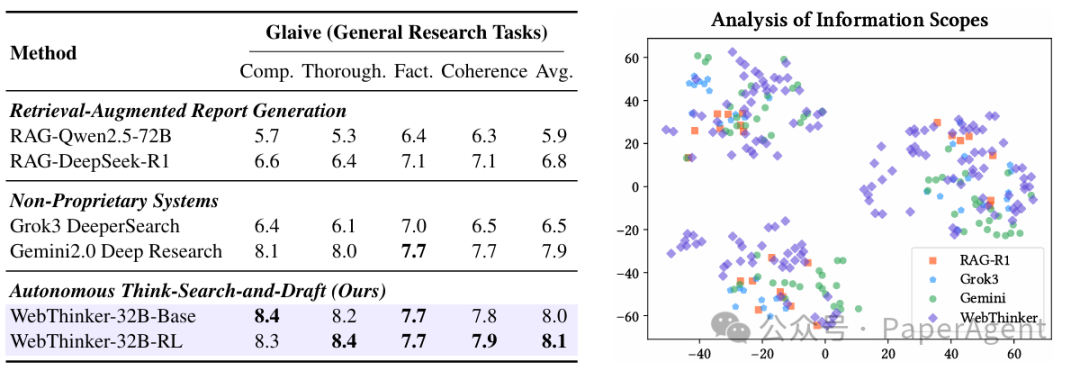
在使用Glaive数据集(开放式研究问题)评估报告生成质量时(由DeepSeek-R1-671B和GPT-4o评估完整性、彻底性、事实性和连贯性):
WebThinker生成的报告在平均分上优于强大的RAG基线和如Gemini-Deep Research等先进的深度研究系统。尤其在报告的"完整性"和"彻底性"方面表现突出,证明了其"自主思考-搜索-写作"策略能够引导模型产出更全面、深入的研究内容。t-SNE可视化分析显示,WebThinker生成的报告内容覆盖更广,探索视角更多样。
3. 基于DeepSeek-R1系列模型的适配:
WebThinker框架也成功应用于DeepSeek-R1系列模型(7B, 14B, 32B),均展现出相比直接推理和标准RAG的显著性能提升,证明了其框架的普适性和有效性。
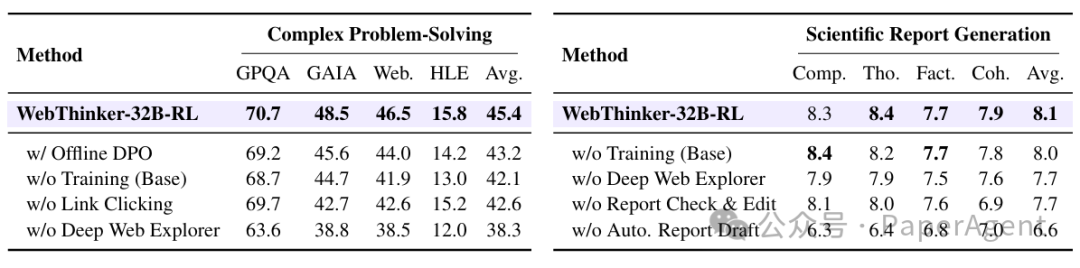
4. 消融实验:
我们通过消融实验验证了WebThinker框架中各组件的贡献。实验结果表明,深度网页探索器、自主"思考-搜索-写作"策略以及基于RL的训练策略都有效提升了整体性能。
结语:迈向更强大的深度研究系统
WebThinker通过赋予LRM自主深度探索网络和动态撰写报告的能力,有效解决了其在知识密集型复杂任务中的局限性,显著增强了LRM进行深度研究的可靠性与实用性。这项工作为开发能够应对复杂真实世界挑战的、更强大、更通用的智能系统铺平了道路。
未来展望
WebThinker虽然已经展现出强大的深度研究能力,但我们的探索才刚刚开始。未来,我们计划在以下几个关键方向进一步拓展WebThinker的能力:
多模态深度搜索与报告生成:
扩展WebThinker以理解和处理图像、视频、音频等多模态内容使模型能够分析科学图表、实验数据可视化、视频教程等非文本信息
工具学习与扩展:
开发更全面、更专业的工具,如数据分析、文献管理、引用追踪等通过持续学习使模型能够自主发现和掌握新工具的使用方法构建工具生态系统,使WebThinker能够根据任务需求灵活调用最合适的工具
基于GUI的网页探索:
增强模型对复杂网页界面的理解能力,包括表单、交互式图表、动态加载内容等实现更自然的人机交互模式,使模型能够像人类一样浏览和操作网页支持更复杂的网页导航策略,如处理登录验证、多步骤操作等
知识图谱构建与推理:
通过这些方向的持续探索,我们期望能够打造一个更加全面、智能、实用的深度研究助手,真正赋能科研工作者,推动知识创新与发现。
更多信息:《动手设计AI Agents:CrewAI版》、《高级RAG之36技》、新技术实战:中文Lazy-GraphRAG/Manus+MCP/GRPO+Agent、大模型日报/月报、最新技术热点追踪解读(GPT4-o/数字人/MCP/Gemini 2.5 Pro)https://arxiv.org/pdf/2505.03275RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。


阅读原文
跳转微信打开

