
“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。
近日,港中文MMLab团队发布了第一个基于强化学习的推理增强文生图模型:T2I-R1。

△ 文生图进入R1时刻:港中文MMLab发布T2I-R1
大家都知道,OpenAI o1和DeepSeek-R1这类的大语言模型(LLMs),已经在解数学题和写代码这些需要“动脑筋”的事情上面展现出了较高的水平。
这些模型通过强化学习(RL),先使用全面的思维链(CoT)逐步分析问题,推理后再提供答案。
这种方法大大提高了答案的准确性,很适合用于处理一些复杂问题。
同理,如果能把强化学习应用在图片理解的多模态大模型中(LMMs),像是图片理解或者文生图这样的任务就能解决得更加出色。
想法是好的,但在实际操作中总会碰到一些问题:
比如,该如何将语义和生成结合起来,让语义理解服务于图像生成?
又比如,如何对图像生成的结果进行质量评估,让模型在生成中学习?
目前CoT推理策略如何应用于自回归的图片生成领域仍然处于探索阶段,港中文MMLab之前的工作Image Generation with CoT(链接见文末)对这一领域就有过首次初步的尝试:通过关注多种推理技术,找到了有效适应图像生成的推理方法,并提出了专门用于自回归图像生成的评估奖励模型。
而T2I-R1在此基础上首次提出了双层级的CoT推理框架和BiCoT-GRPO强化学习方法。
无需额外模型,即可实现文本到图像生成的推理应用。
图片生成的双层推理解法
与图片理解不同,图片生成任务需要跨模态的文本与图片的对齐以及细粒度的视觉细节的生成。
传统的推理方法很难同时兼顾两种能力,而现有的自回归生成模型(如VAR)缺乏显式的语义级推理能力。
为此,港中文团队提出了适用于图片生成的两个不同层次的CoT推理:
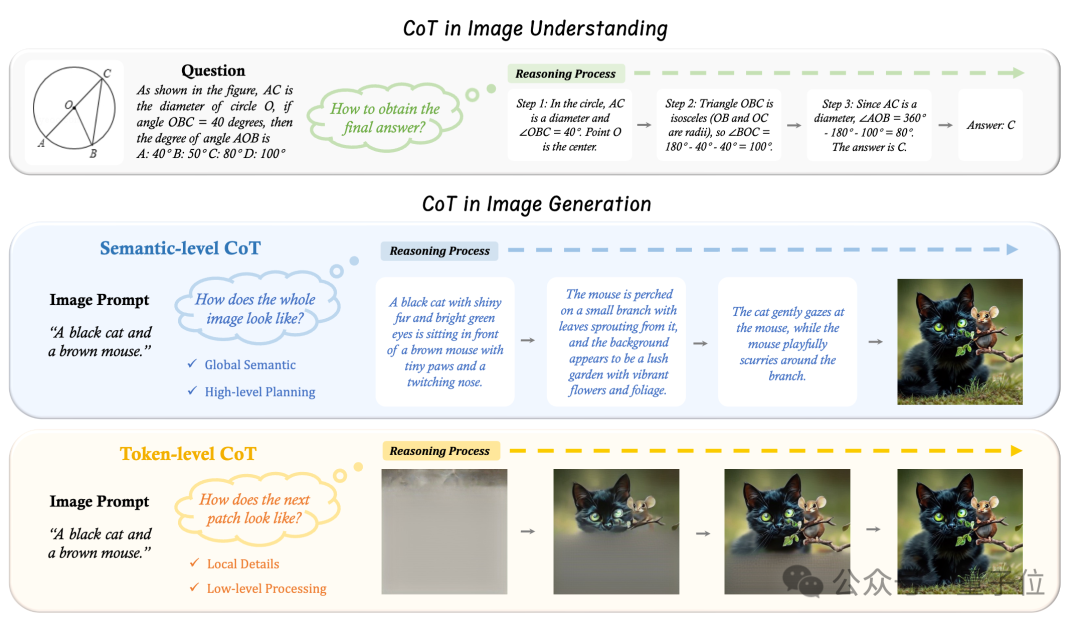
Semantic-level CoT
Token-level CoT

统一的双层级CoT框架
然而,尽管认识到这两个层次的CoT,一个关键问题仍然存在:我们怎么协调与融合它们?
当前主流的自回归图片生成模型,如VAR,完全基于生成目标进行训练,缺乏Semantic-level CoT推理所需的显式文本理解。
虽然引入一个专门用于提示解释的独立模型(例如LLM)在技术上是可行的,但这种方法会显著增加计算成本、复杂性和部署的困难。
最近也出现了一种将视觉理解和生成合并到单一模型中的趋势:在LMMs的基础上,这些结合了视觉理解和生成的统一LMMs(ULMs)不仅可以理解视觉输入,还可以根据文本提示生成图像。
可是,它们的两种能力仍然是分开的,通常在两个独立阶段进行预训练。还没有明确的证据表明,理解能力可以使生成受益。
鉴于这些潜力和问题,团队从一个ULM(Janus-Pro)开始,增强它以将Semantic-level CoT以及Token-level CoT统一到一个框架中用于文本生成图像:
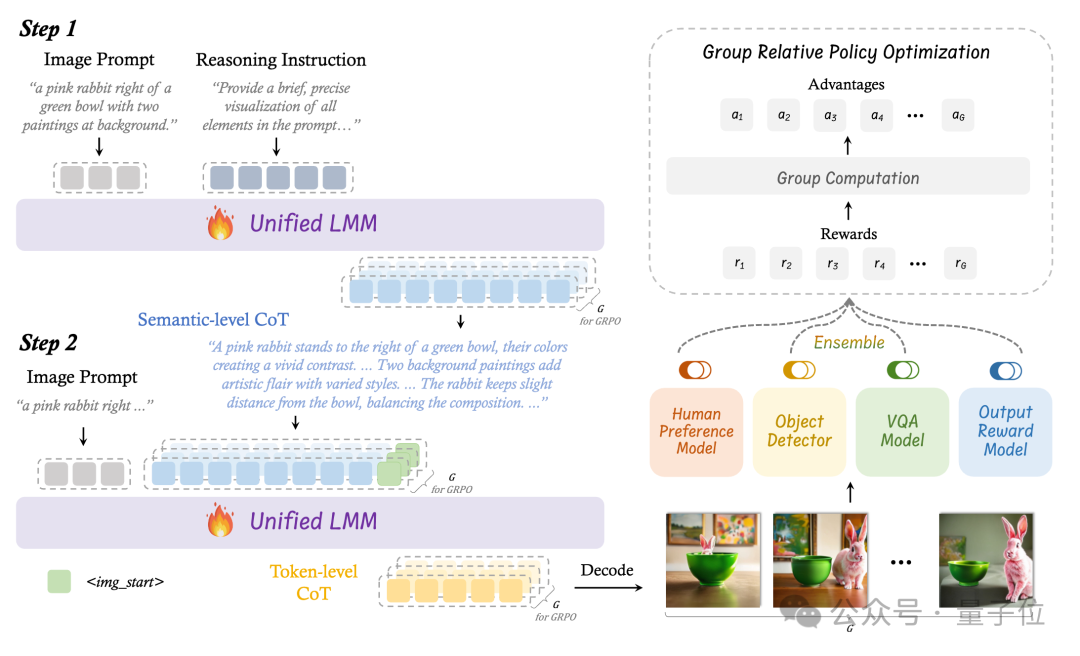
BiCoT-GRPO实现协同优化
在双层级CoT框架的理论基础上,团队提出了BiCoT-GRPO,一种使用强化学习的方法来联合优化ULM的两个层次的CoT:
首先,指示ULM基于Image Prompt来想象和规划图像,获得Semantic-level CoT。
然后,将Image Prompt和Semantic-level CoT重新输入ULM来生成图片以获得Token-level CoT。
这样便能对一个Image Prompt生成多组Semantic-level CoT和Token-level CoT,又对得到的图像计算组内的相对奖励,从而更新GRPO,在一个训练迭代内同时优化两个层次的CoT。
BiCoT-GRPO方法首次在单一RL步骤中协同优化语义规划与像素生成,相比起分阶段训练效率更高、计算成本更低。
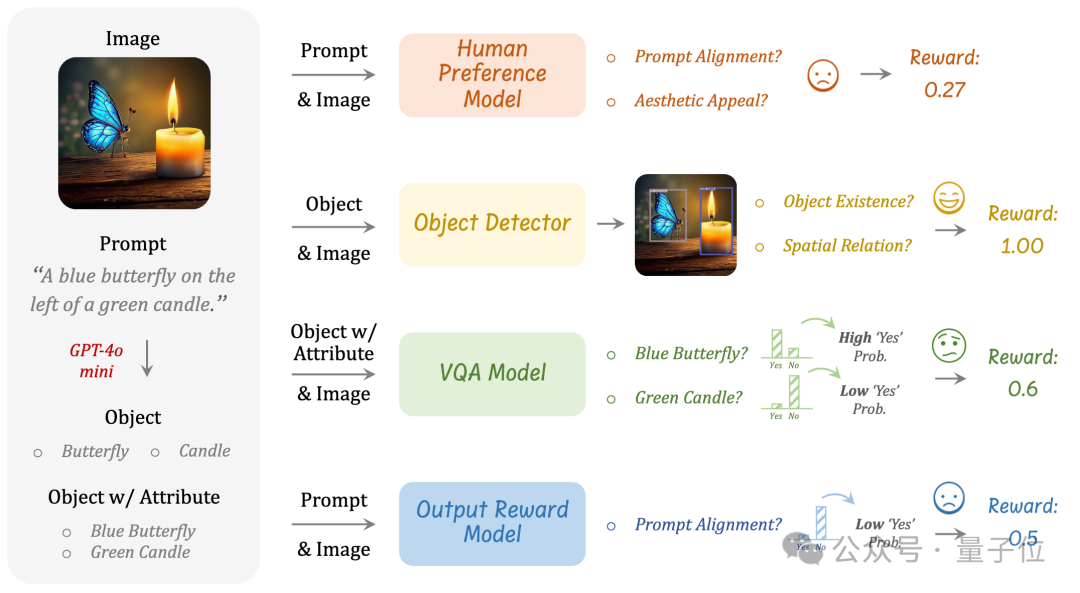
T2I-R1:破解生成评估难题
与图片的理解任务不同,理解任务有明确定义的奖励规则,而图像生成中不存在这样的标准化的规则。
为此,港中文团队提出使用多个不同的视觉专家模型的集成来作为奖励模型。这种奖励设计有两个关键的目的:
根据上述方法,该团队获得了T2I-R1——这是第一个基于强化学习的推理增强的文生图模型。
根据T2I-R1生成的图片,团队发现模型能够通过推理Image Prompt背后的真实意图来生成更符合人类期望的结果,并在处理不寻常场景时展现出增强的鲁棒性。
同时,下面的可视化结果表明,Semantic-level CoT明显有助于猜测出用户的真实想法。
比如右上角的例子,加入了Semantic-level CoT的模型猜到了prompt指的是故宫;而Token-level CoT则负责得到更美观的图像。

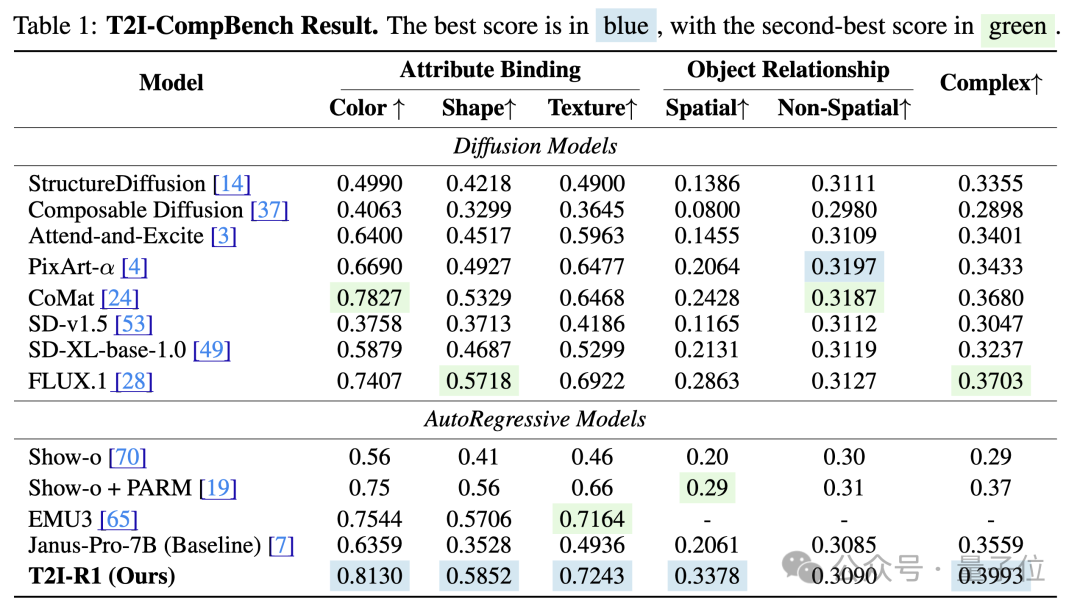
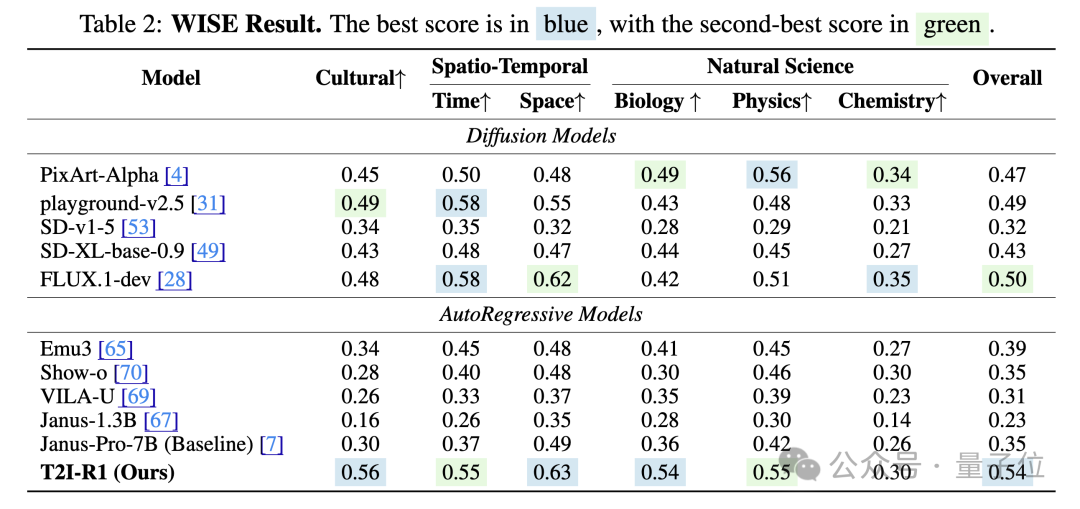
定量的实验结果也表明了该方法的有效性:
T2I-R1在T2I-CompBench和WISE在Benchmark上分别比baseline模型提高了13%和19%的性能,在多个子任务上甚至超越了之前最先进的模型FLUX.1。
综上所述,T2I-R1的出现证明了CoT在图像生成中的有效性,实现了高效可拓展的生成架构,为多模态生成任务提供了新的推理增强范式。
在未来,T2I-R1的框架或能进一步拓展至视频生成、3D内容合成等复杂序列生成任务,推动生成式AI向”能思考、会创作”的通用智能体演进。
论文:https://arxiv.org/pdf/2505.00703
代码:https://github.com/CaraJ7/T2I-R1
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
