index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
文章讲述了DeepSeek一体机在面对市场挑战后,通过更换“昆仑芯P800”实现性能飞跃的故事。从单机到集群,再到昆仑芯超节点的演变,详细介绍了其在不同应用场景下的解决方案,以及如何通过百度百舸·AI异构计算平台的协同,实现大模型训推的优化和性能提升,最终成为ToB产品圈的“网红”。
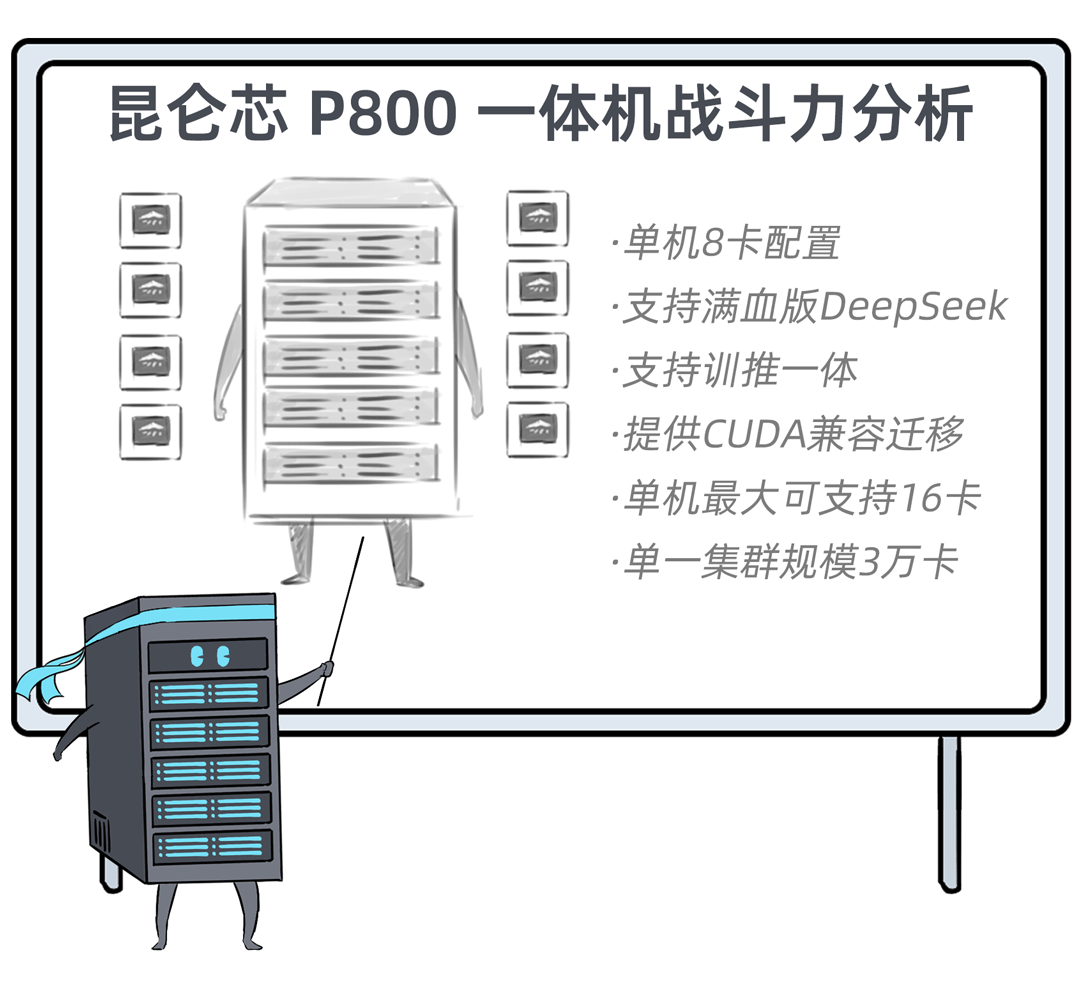
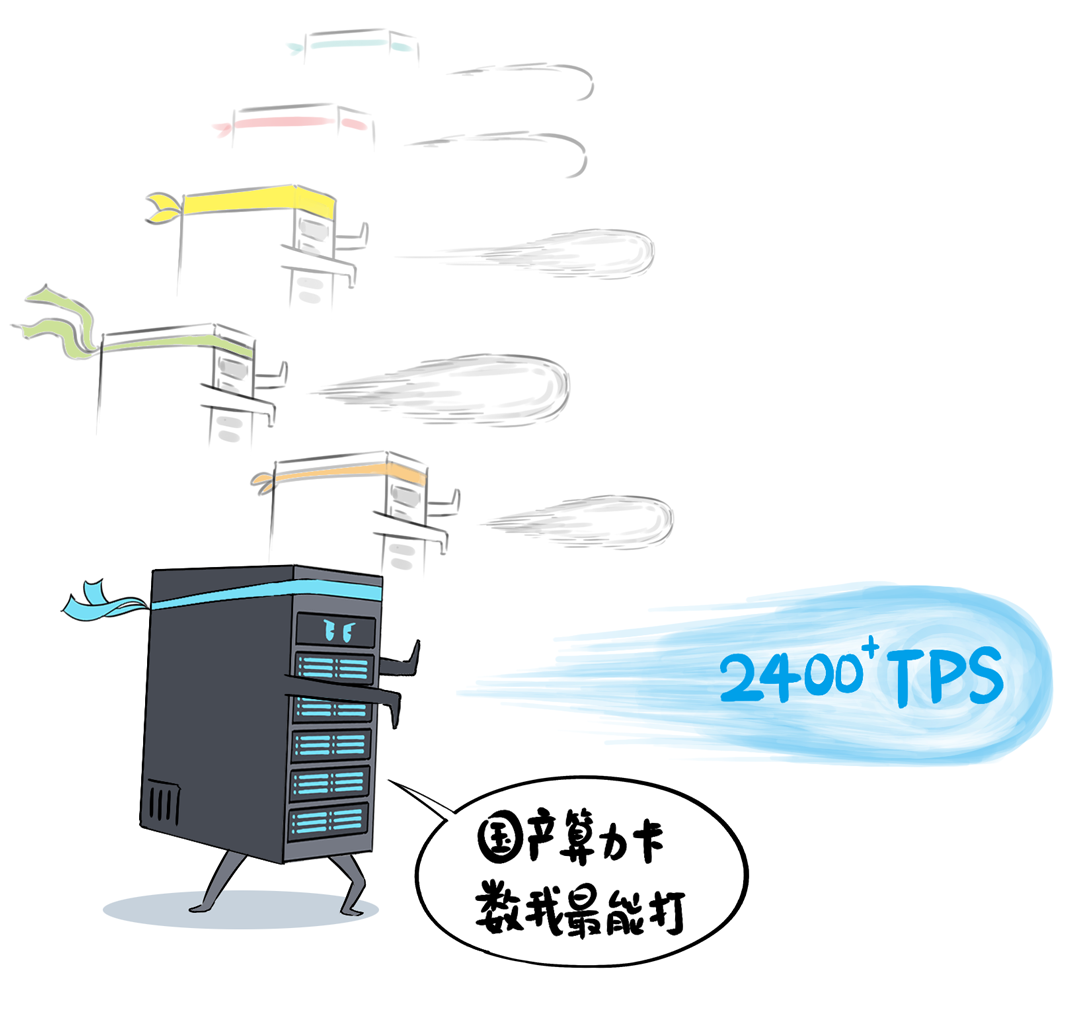
🚀 DeepSeek一体机通过更换昆仑芯P800,实现了从“战五渣”到“战神”的转变,性能大幅提升,支持满血版DeepSeek V3/R1,推理吞吐量可达2400+ Tokens每秒,并支持训推一体,方便模型微调。
🏢 DeepSeek一体机提供多种扩展方案,满足不同规模企业的需求:从单机八卡,到多机负载均衡,再到引入RDMA网络构建并行推理集群,以及采用PD分离模式扩展成更大集群,以适应大规模企业级应用。
🤝 DeepSeek一体机通过百度百舸·AI异构计算平台,实现超大规模集群的构建。百度百舸平台提供高性能网络、深度优化的PD分离部署方案、多芯异构支持和弹性调度等能力,提升集群的整体性能和效率。
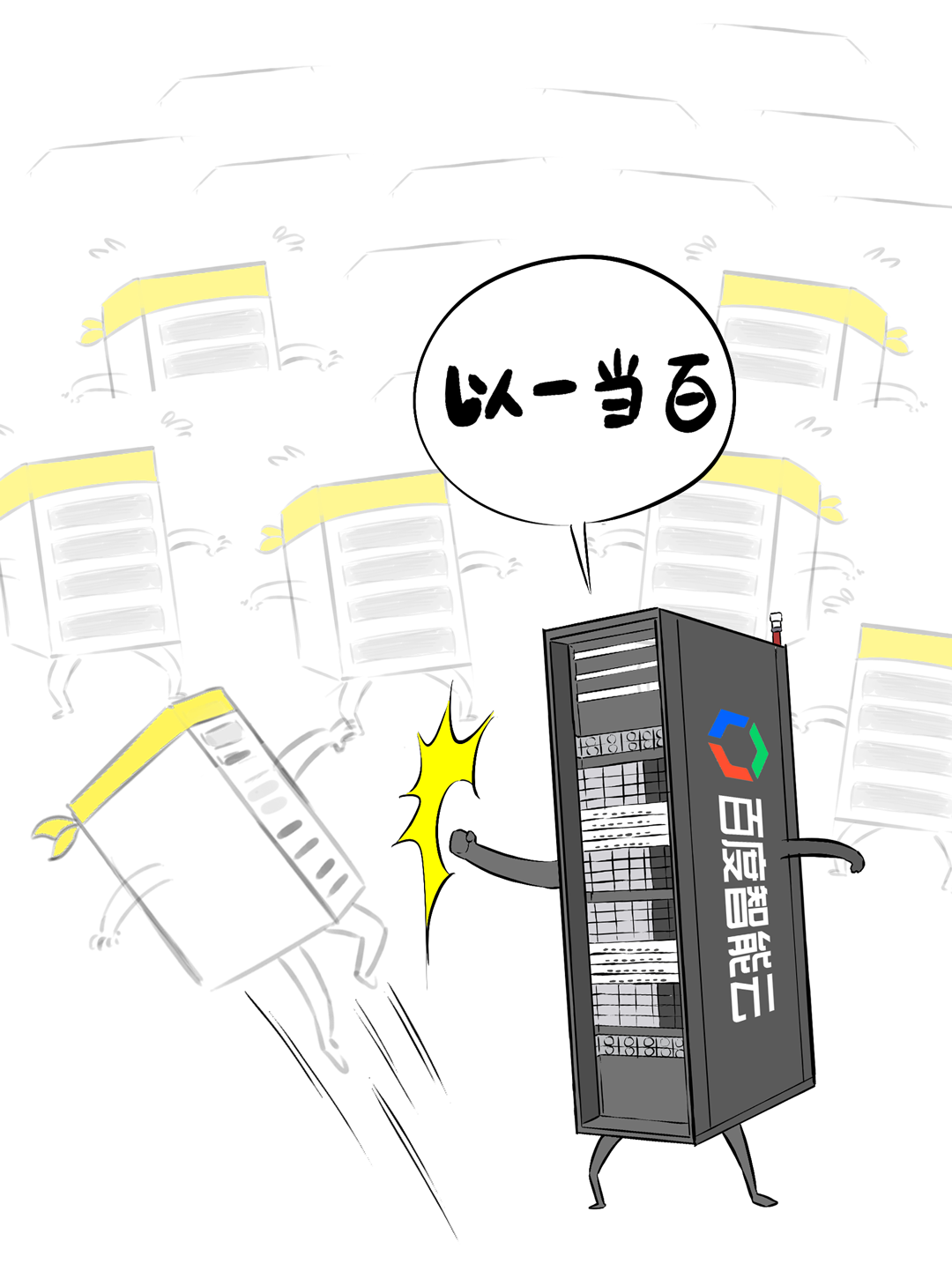
💡 昆仑芯超节点的发布是DeepSeek一体机的又一次升级。昆仑芯超节点具有高密机柜、高带宽互联等特性,单节点训练性能提升10倍,单卡推理性能提升13倍,实现了“以一当百”的效果。
原创 小黑羊 2025-04-25 12:20 北京
.

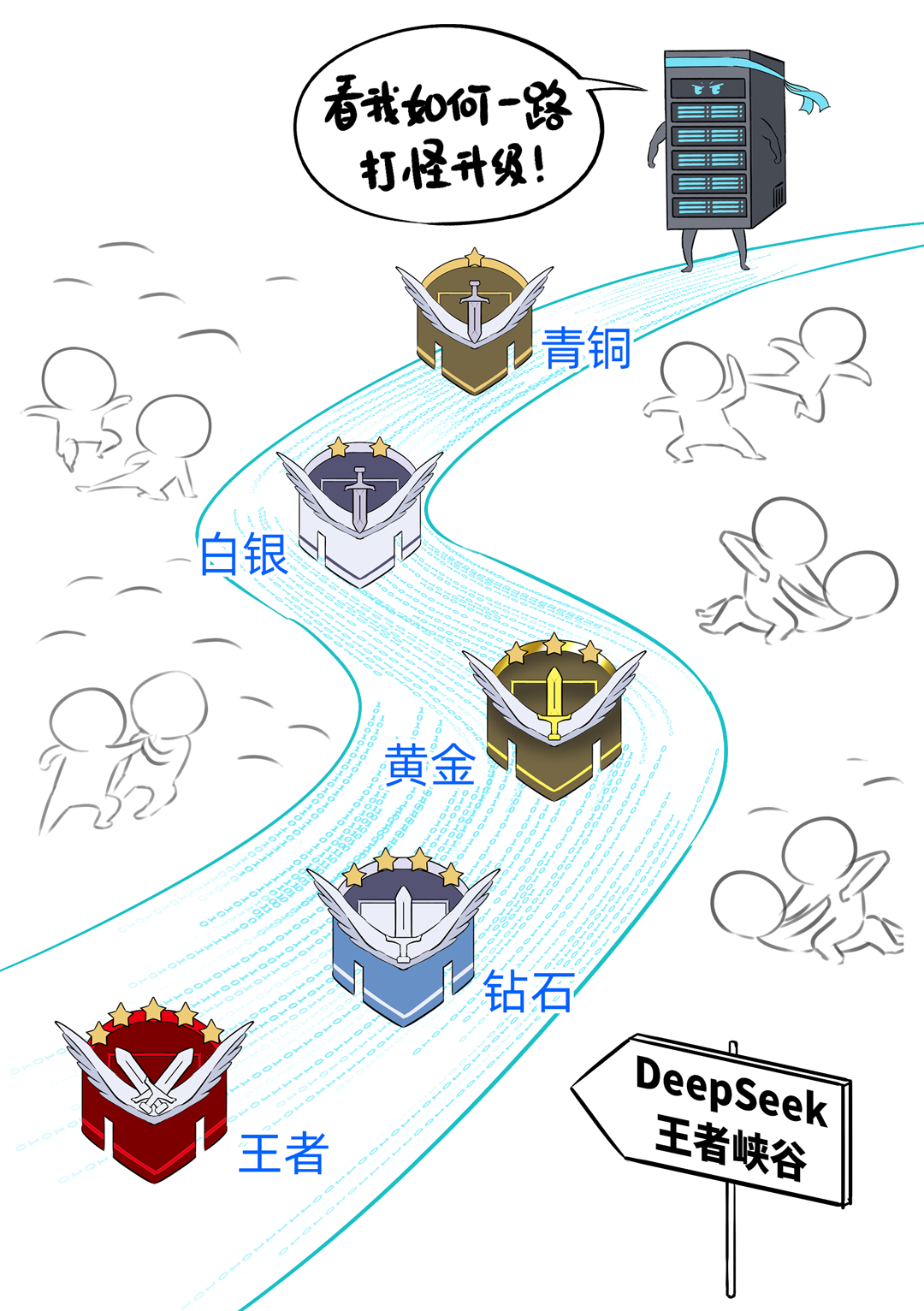
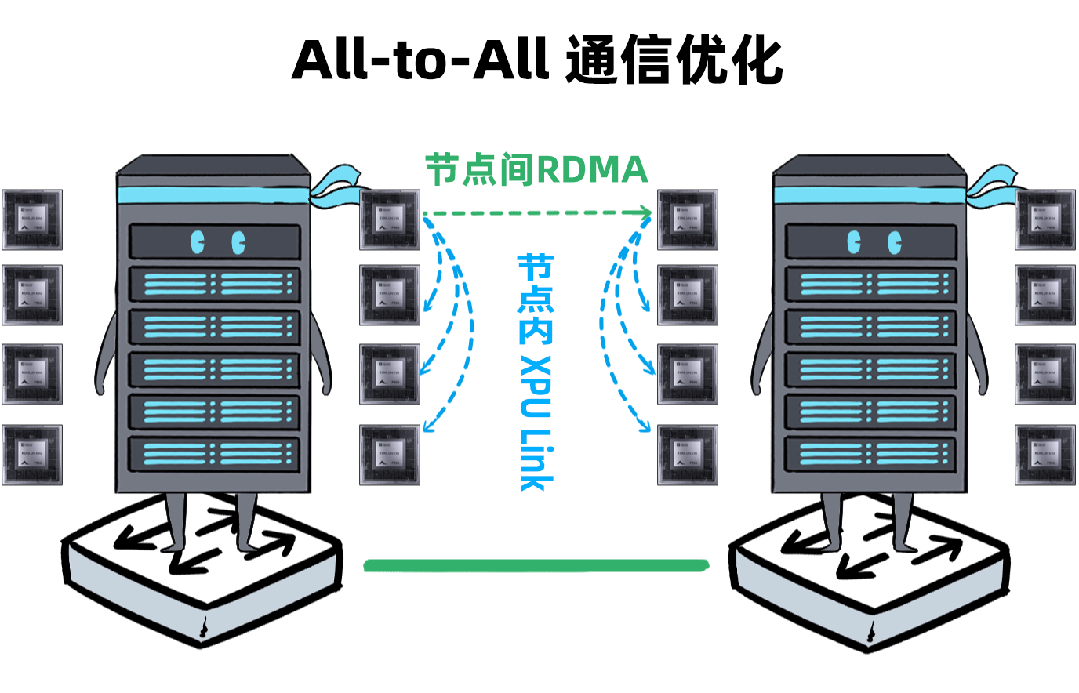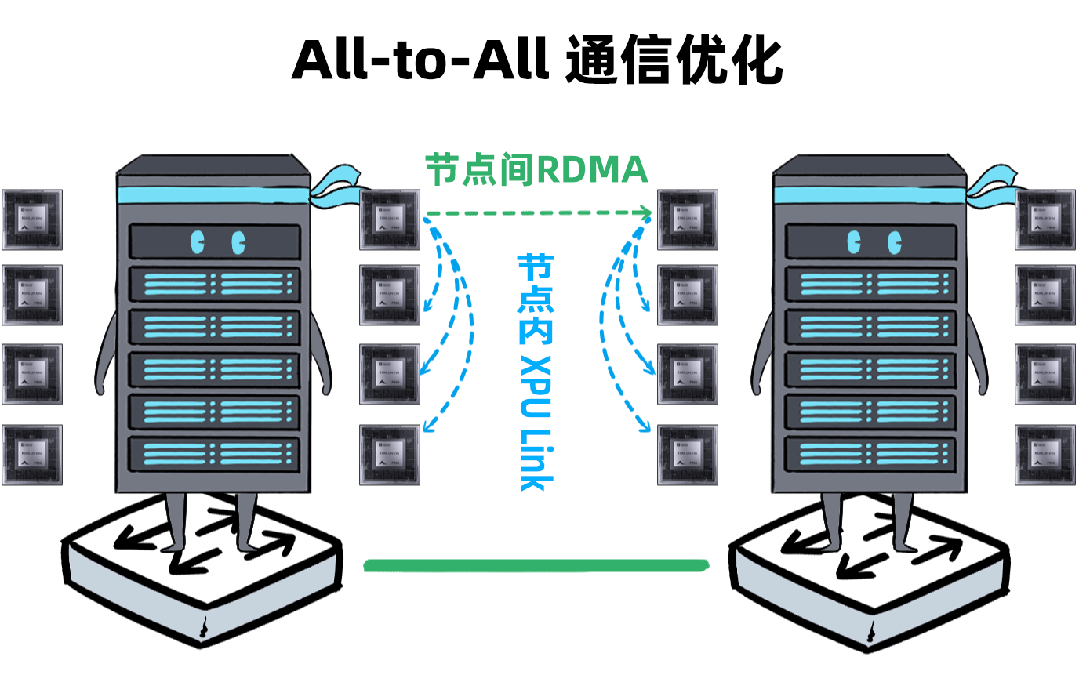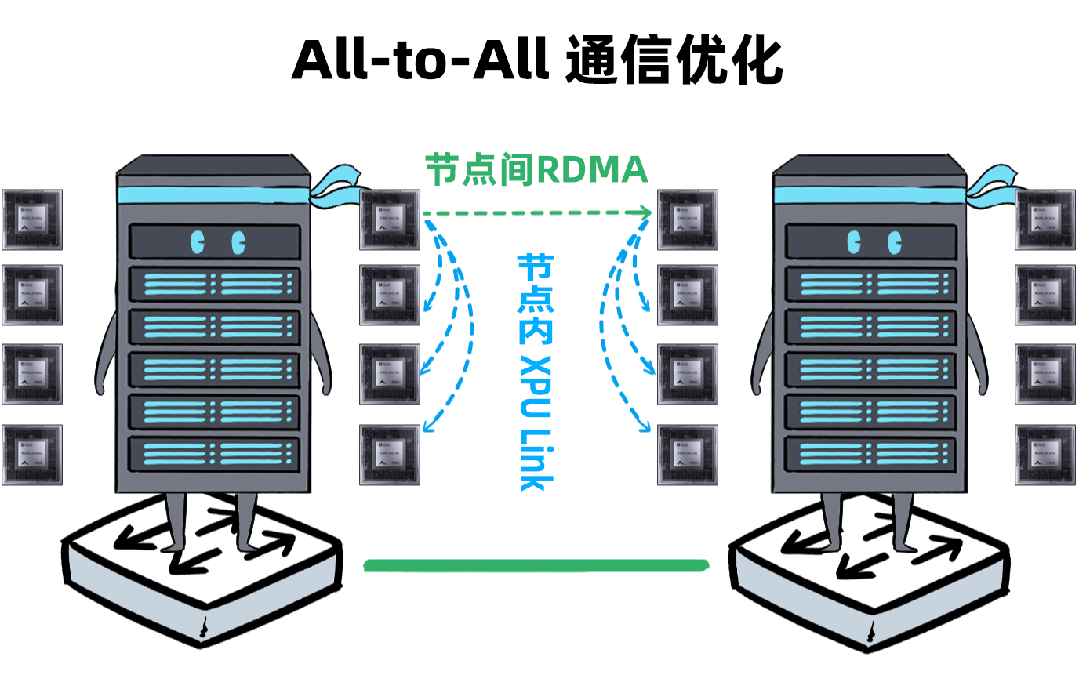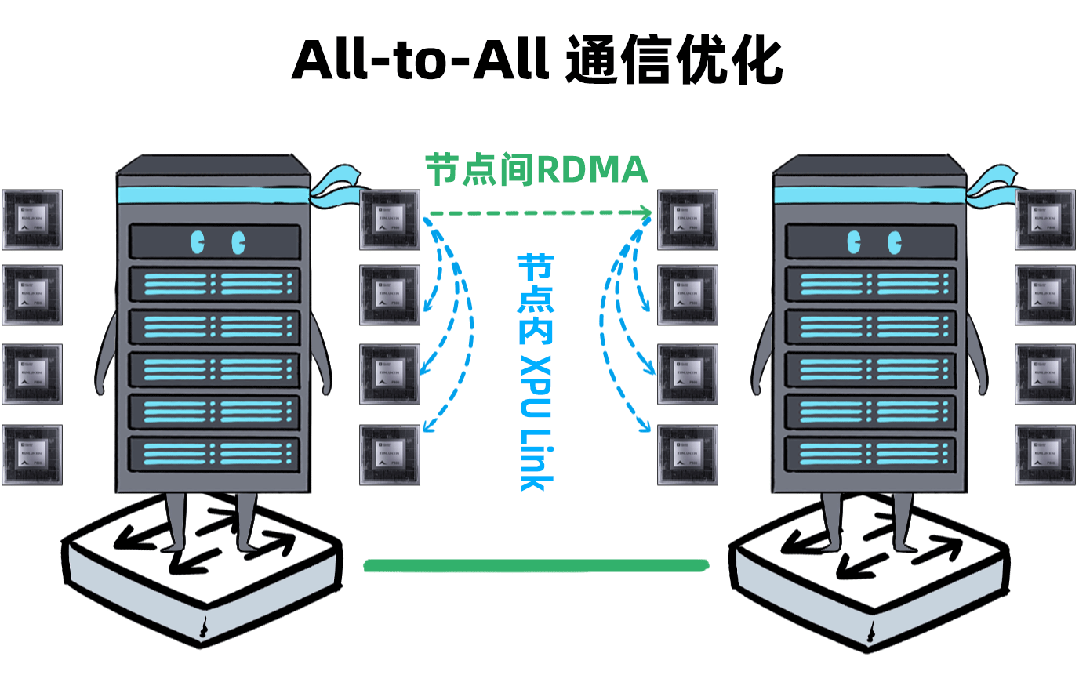
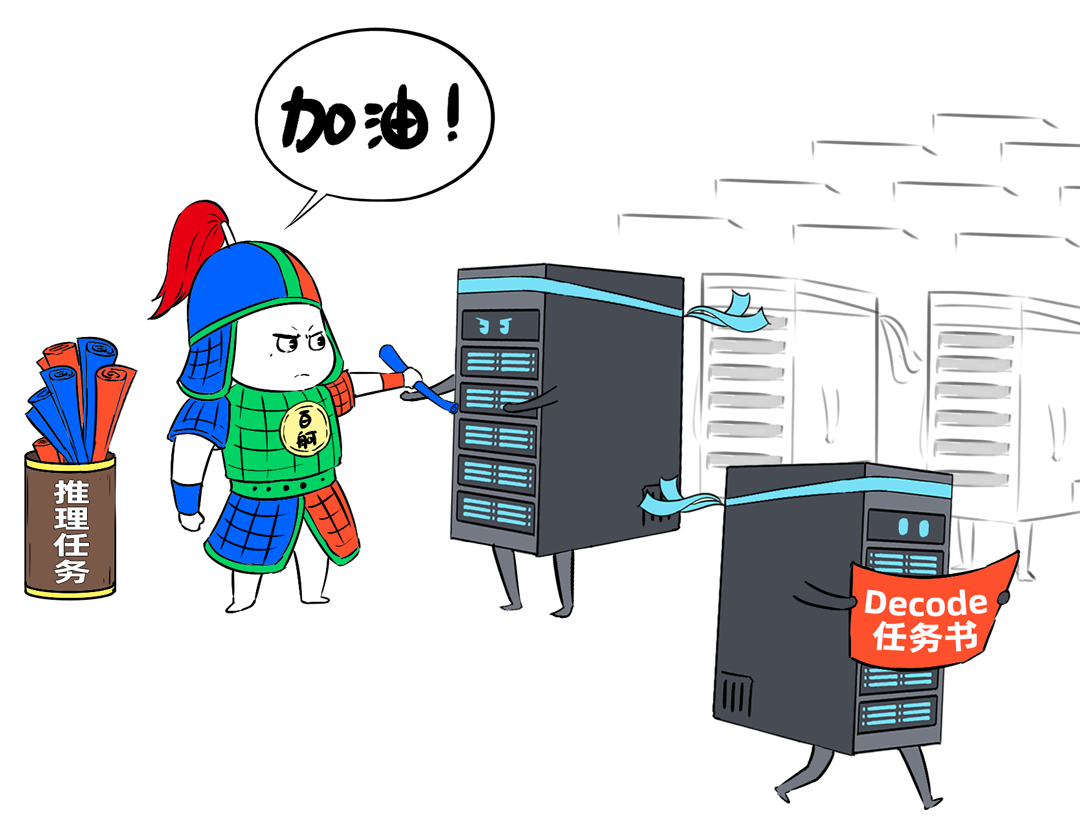
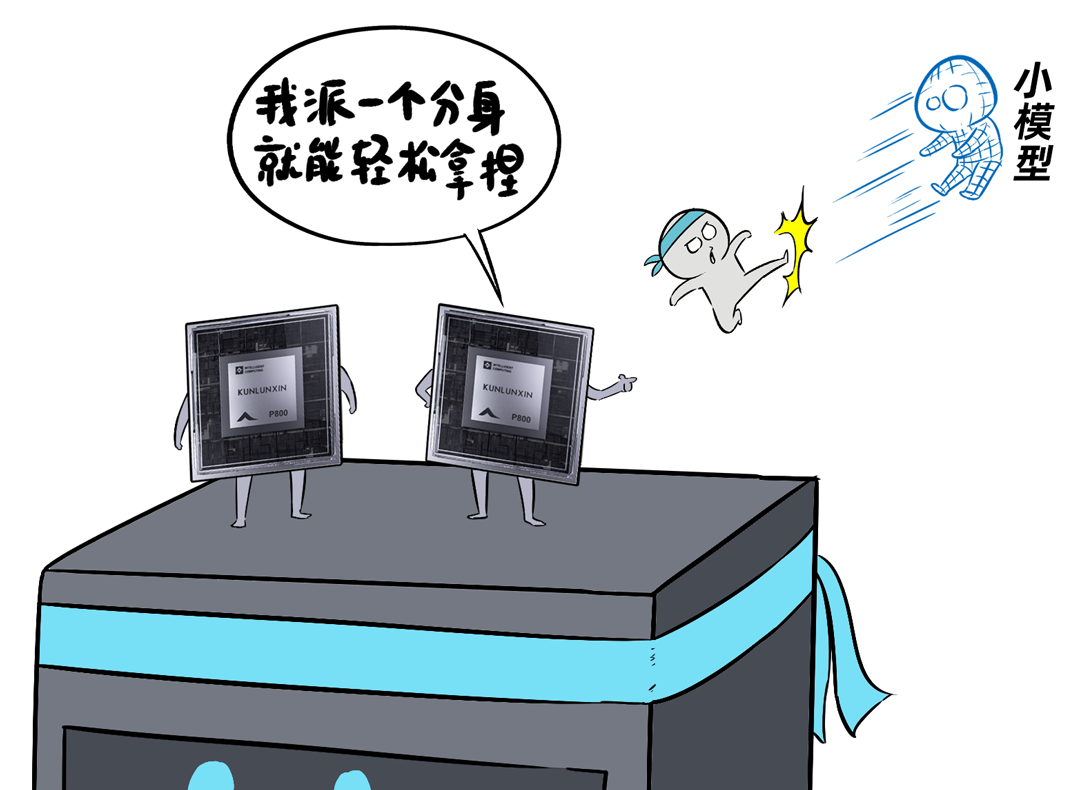
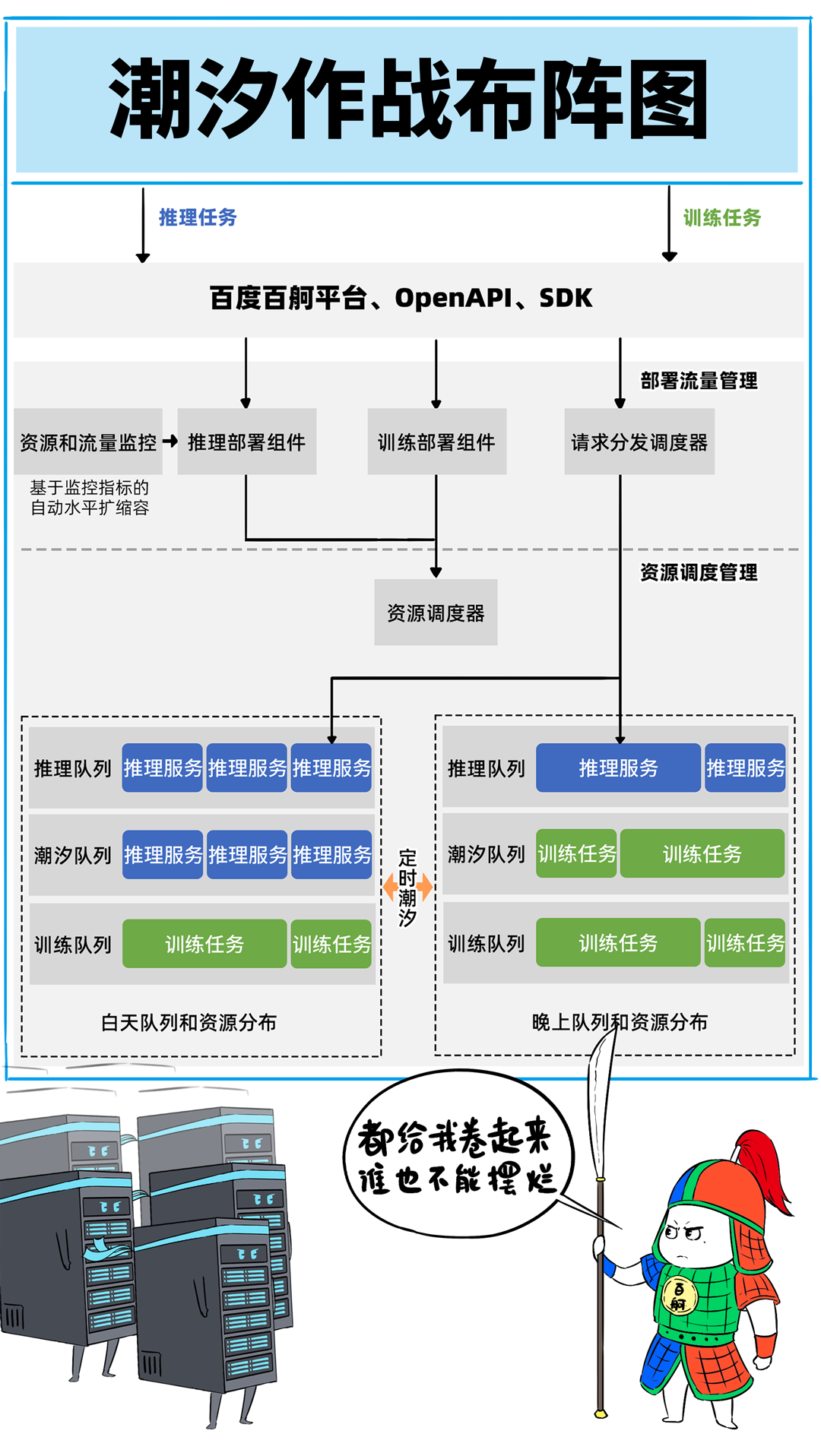
我,是一台「DeepSeek一体机」,开年以来,我可是卖疯了。无论是甲方还是乙方,都超级喜欢我,大家都把我视为靠谱的DeepSeek落地方案。可是,人红是非多,不少人羡慕嫉妒恨,对我进行各种攻击。个个不讲武德,招招戳我要害,这是要把我虐成“战五渣”。啊啊啊啊啊,我有点扛不住了,难道真要被“干黄”了吗?确实,对于一体机来讲,当客户回归理性,以上攻击点都无法回避。有人给我换了“芯”,换“芯”后,我竟然无敌了!!!从此,无论面对青铜段位还是王者段位的挑战,我全部宛如“开挂”,所向披靡。这么说吧,我可以根据客户的业务发展,逐步扩展,共同成长。新手上路,选我这样单台一体机,单机八卡跑满血DeepSeek,开箱即用,超高性价比。而有些同行,可能需要两台联手才能扛得动这样的大活儿。2、白银段位,此时企业使用大模型已经过了新手期,开始尝试更多的场景了。一台不够用怎么办?可以再添置几台,多台负载均衡,各司其职,满足不同业务需求。(每台都独立运行满血大模型,分别处理不同业务)3、黄金段位,到了这个段位的企业,已经渐入佳境,他们希望更高效率的使用大模型。莫慌,我还有妙招:引入RDMA网络,多台一体机可以瞬间变阵,组成并行推理集群,MoE专家并行,模型吞吐量飙升。4、钻石段位,此时,企业已经是大模型深度应用的老司机了,他们可能要挖掘大模型的所有潜力。没问题,我可以继续变阵,扩展成更大集群,并采用PD分离模式,以更高的性能满足大规模企业级应用。不过,走到这一步,大家可能就犯嘀咕:以前这货“战五渣”,为啥现在轻松“五连杀”?SO,我现在是内置8张P800加速卡的DeepSeek一体机。目前,单机八卡的我,就可以支持满血版DeepSeek V3/R1,推理吞吐量可以达到2400+ Tokens每秒。而且,跟市面上绝大多数一体机不同,我不光支持推理,还支持训练。我是真正的「训推一体」,给模型做个后训练或者微调对齐,让它在落地场景更加游刃有余。同时,我还提供CUDA兼容技术,让原来依赖于N家CUDA的模型,可以轻松迁移过来。在单机的战斗力方面,我正在修炼“16卡心法”,出关之日,单机性能又可以大幅攀升。单一集群可以支持30000卡,所以,你丝毫不用担心扩展性。老司机都懂的,要想攀上王者巅峰,不能光靠单打独斗,必须要团队配合。接下来,我就给大家展示下,我是如何通过“团战”,拿下王者局的。想干更大业务,就要组更大集群,大家完全不需要担心我的扩展能力(单集群30000卡)。但是真正打起团战来,光靠人多不行,还需要看“配合”和“微操”,更要看临阵“指挥”。此时,我会请来一位团队指挥官:百度百舸·AI异构计算平台。这位老铁身经百战,最擅长指挥“大规模兵团作战”,手段那是相当高明。第一,看行军(组网):百度百舸的高性能网络(HPN)延迟低至5μs,而且全网无阻塞。这就使得参与团战的兄弟们配合更加默契,彼此“喊话/补刀/Gunk”,绝不掉链子。在低延迟基础上,百舸还提供了机内机间互联一体化通信调度,减少跨节点通信流量,并支持对训推流量分级管理,确保推理服务低延迟。第二,看布阵(部署):百度百舸提供深度优化的「PD分离」部署方案。所谓PD分离,就是将大模型推理的Prefill阶段和Decode阶段,分别交给不同的节点或算力卡来处理。因为P阶段是并行处理,D阶段是串行处理,对算力的要求不同,掺和在一起跑影响效率。百舸支持PD任意配比,推理团战时,我和战友们根据需求灵活分工,有的兄弟领“P活”,有的兄弟领“D活”,PD搭配,干活不累。自动分好任务后,百舸通过细粒度PD调度、冗余专家编排等深度优化手段,让我们整个集群的“团战”实力完全发挥出来,人人都是“DPS”!满血版DeepSeek推理,单Token生成时长(TPOT)缩短了40%,整体吞吐(TPS)提升20倍以上。也正是这套方案,支持了DeepSeek在百度智能云千帆平台上大规模上线。第三,看领导力(多芯异构):不仅支持自家昆仑芯,还支持国内外各种主流算力卡、GPU。每个企业实战场景的「王者峡谷」都是非常复杂的,基础设施多种多样,存在不同出身的算力“英雄”(昆仑芯、英伟达、昇腾等)。没关系,英雄莫问出处,百度百舸指挥官可以把他们都纳入麾下,统一管理,一云多芯,异构训推。第四,看“配合”和“微操”(弹性调度,训推混布):让算力资源的使用更加极致,效率最大化。首先通过GPU虚拟化,细粒度切分算力,来匹配小模型的算力要求(相当于微操补刀小兵),避免浪费。接下来,百舸可以指挥同一个集群里兄弟,一部分打“推理仗”,另一部分打“训练仗”,大家互不干扰。最后,通过潮汐算力、资源超发等调度手段,实现白天推理、晚上训练,高优任务抢占资源等,动态满足不同部门、不同业务对算力的弹性需求。总之吧,让每个战斗单位都卷起来,团队战斗力才能最大化。就这样,百度百舸指挥调度得当,算力战队小伙伴们人人奋勇、个个争先,拿下王者局,自然不在话下。在今天举办的「Create2025百度AI开发者大会」上,我的超级变身来了,这就是昆仑芯超节点。昆仑芯超节点专打“高端普惠局”,高密机柜内32/64卡机内互联,卡间互联带宽是原来普通一体机的8倍,单节点训练性能提升10倍,单卡推理性能提升13倍!在推理上,一个机柜能顶过去100台机器,做到“以一当百”。变身“超节点”的我,堪称国产算力神装!不仅支持私有化交付,还不挑战场,风冷机房也能部署。来,come on baby,让我们来一场酣畅淋漓的大模型训推大战吧!




















阅读原文
跳转微信打开

