index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
本文由硅基流动撰写,旨在澄清大模型 API 评测中常见的误区。文章以DeepSeek-R1 API评测为例,指出了一些测试方法上的漏洞,例如混淆API与App/网页端的功能差异、对量化版本的误解、对云平台功能的错误期待、超参数设置不一致导致的偏差等。文章强调了多次测试、双盲测试和Pro版服务的必要性,呼吁更客观、严谨的评测,以促进API服务质量的提升。
🧐 API 评测应区分 API 服务与 App/网页端:API 服务主要面向开发者,而 App/网页端功能更丰富,不应混为一谈,测试时需确保系统提示词和超参数一致。
🤔 满血版R1与量化版之争:市面上基本不存在“非满血版 R1”,DeepSeek 官方开源 R1 的权重本身就是 FP8 量化,不同量化方案在实际场景中各有收益,盲评测试结果更具参考价值。
💡 云平台功能与C端应用的区别:云平台主要提供API服务,而联网搜索、文件上传等功能通常由上层应用提供,云平台也在逐步增加此类功能以方便用户体验。
🌡️ 超参数设置对测试结果的影响:不同平台的超参数设置可能不同,例如 Temperature,设置不一致会导致输出效果差异,影响测试准确性。
🔄 测试结果的随机性与多次测试的重要性:单次测试结果可能存在偏差,多次测试取平均值可以更准确地反映模型性能,双盲测试是更优的评测方案。
SiliconFlow 2025-03-21 11:45 北京
第一手、最前线视角解析 API 评测误区。

来源|硅基流动
作为大模型服务商之一,我们乐见公开的大模型 API 服务评测报告与使用体验,专业、客观、严谨的评测有助于更多用户快速筛选符合需求的服务,也能促进 API 提供商提升服务质量。
随着硅基流动的 SiliconCloud 等平台上线 DeepSeek-R1,市面上出现了不少测试各大厂商 API 服务的评测文章及反馈,不过,从我们收到的不少内容及反馈来看,其中的对比测试方式多有漏洞,质量参差不齐。
由于 API 服务评测的测试要素及对齐条件较多,一旦影响因子设置不一致,很容易得到有缺陷的评测数据与结论。现实测评情况也表明,这的确是一项较高门槛的工作。我们相信,多数评测者无意给出不客观的评测报告——即使是专家级大模型评测者,如果考虑不周,出错也在所难免。然而,错误评测结果造成的客观后果是,可能误导不明真相的用户,同时给模型服务供应商造成困扰并影响品牌声誉。考虑到要为 API 评测内容付出不小的答疑与解释成本,我们认为有必要专门做一点误区澄清工作。本文是硅基流动“大模型 API 评测指南”系列第一篇。我们将以 DeepSeek-R1 API 评测为例,解析当下评测内容或质疑存在的误会。以下误区摘编自公开内容,为防止产生不必要争议,除硅基流动、DeepSeek 外隐去其他厂商名称。
01. 第三方 R1 降智,不是满血版?
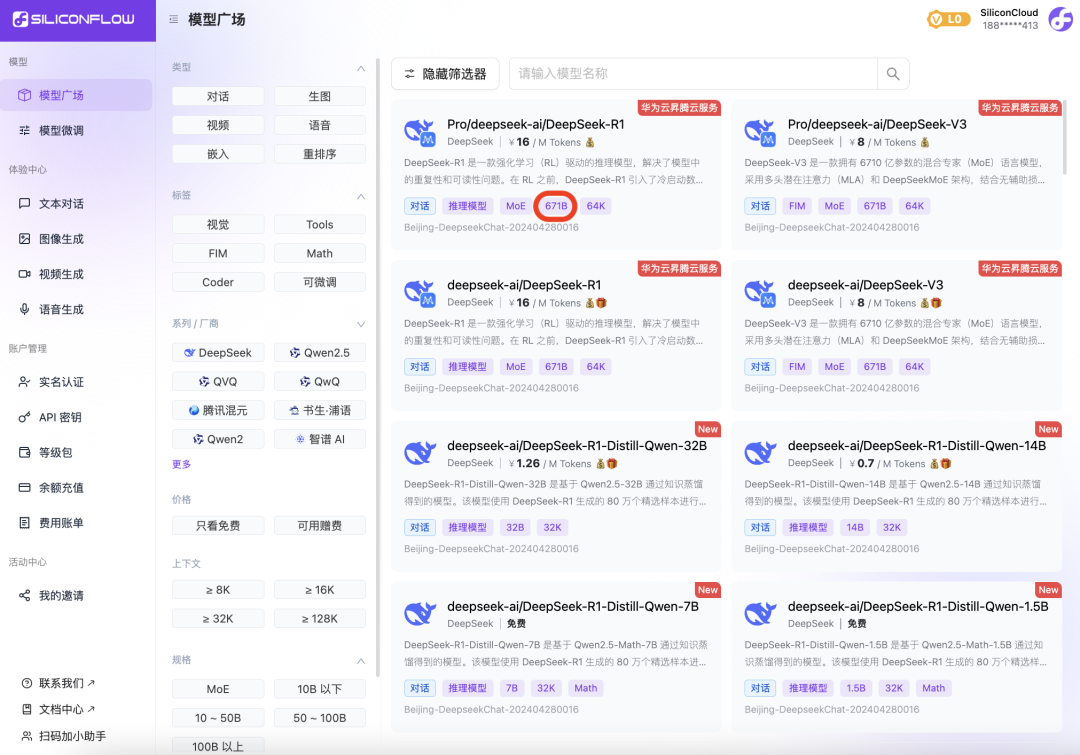
误区:“在某应用调了硅基流动、xx 的 DeepSeek-R1 API,效果不如在 DeepSeek 官方 App / 网页版 与 xx 应用上使用,感觉不是满血版 R1。” 解析:对比 DeepSeek-R1 服务效果,不应该将 API 与 App / 网页端放在一起作混合对比,而是重点需要测试平台的 API 服务,同时确保在测试时系统提示词、超参数(Temperature、Top-p、Top-k)等指标是一致的。可以确定的是,市面上知名的第三方平台部署的都是“满血版 R1(671B)”,之所以用户使用感受有差异,是因为模型输出的随机性、平台提供的配套功能及超参数设置等可能不一致,而非底层模型本身的差异。
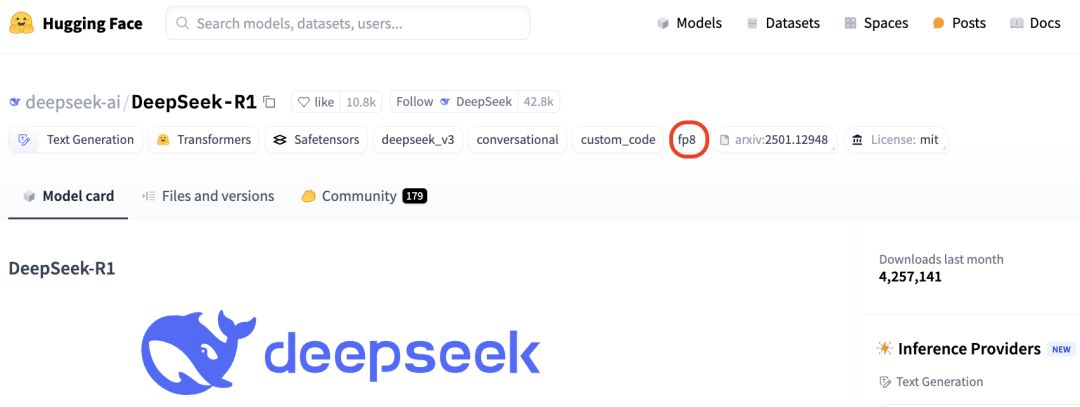
市面上基本不存在“非满血版 R1”,也基本不存在所谓模型“降智”,而 R1 蒸馏版(70B、1.5B等)与满血版的效果差距很明显,一般知名服务商都会注明,如果这些平台提供所谓“非满血版 R1”,很容易测试出来,这完全是自砸招牌,他们没有动机“以次充好”。 误区:“国内的这些所谓满血版 R1 跟 DeepSeek 官方感觉还是有区别,xx 部署的应该是 FP8 量化。” 解析:DeepSeek 官方开源 R1 的权重本身就是 FP8(量化),且声明他们部署的也是开源版本,并没有所谓的官方特供版,所以原版的 FP8 R1 和“满血版 R1”其实指的是同一个模型。市面上还没有公开的 BF16 版 R1,如果要跑 BF16 推理,还需要通过将 FP8 反量化回 BF16,也没有证据表明 BF16 R1 比“满血版 R1(FP8)”精度更高。另外,大模型不同的量化方案精度测试本身有很多影响因素,不同量化方案在实际场景中各有收益。不同精度的模型可能在极少数边缘案例上有差别,但也只能对比最后的测试效果。
在效果测试时,非盲评测试可能会受到主观因素影响,甚至答案的先后顺序也会影响最终评测结果,无法证明各平台所提供 DeepSeek-R1 API 能力存在明显差异。我们认为,如果在双盲测试后各家 API 效果接近(或用户在日常场景中感觉不出区别),可认为这些平台的模型精度是一致的。
误区:“综合测评分析,xx 云平台在功能性上更胜一筹,不仅能够支持语音输入,还能够进行文件上传;仅有 xx 应用支持图片上传。”解析:包括 DeepSeek-R1 在内的任一模型天然不支持联网搜索、文件上传等功能,而是需要平台/应用方做额外的功能开发。大模型云服务平台与上层应用面向不同的用户群体,不应该混为一谈对比产品功能。推理云服务提供商主要提供的是面向开发者的 API 服务,一般 C 端用户需通过第三方应用调用 API。Chatbot 等应用直接面向 C 端用户,所以联网、文件上传等配套功能做得比较齐全。
目前,为方便 C 端用户直接体验 DeepSeek-R1 API 服务,多数云服务平台也开始提供联网搜索、文件上传等功能,硅基流动正在内测支持这些功能,后续也将公开发布供用户使用。
04. 同样的超参数,硅基流动的 R1 输出乱码?
误区:“同一篇文章大纲,相同的提示词,同一个参数温度,硅基流动输出的内容胡乱瞎说,中间还有一段居然输出中文,xx 基本上跟官方保持一致。”解析:硅基流动 SiliconCloud 的 API 支持调整 DeepSeek-R1 的 Temperature,但包括 DeepSeek 官方在内的部分平台不支持调整 R1 的 Temperature。
因此,在测试模型输出准确率时,如果将所有平台的 Temperature 设置为 2,那么官方与其他平台的 Temperature 实际是最佳值 0.6,但硅基流动的 DeepSeek-R1 API 的 Temperature 设置为 2 会生效,输出效果可能变差,从而造成不准确的测试结果。
误区:“此前,DeepSeek-R1 官方在 AIME 2024 基准测试中取得了 79.8% 的 pass@1 得分。而此次我们通过 Python 脚本进行测评 AIME 题库下,正确率由高到低依次是:xx 83.33% ;官方 Deepseek 73.33% ;xx 71.67% ;xx 58.33% 。其中 xx、 Deepseek 各网络状态下表现平稳,测试均为一遍过,30 道题全部响应,测得比较省心。”解析:单次(或几次)测试结果充满了随机性。DeepSeek 官方测出来 79.8% 的 pass@1 得分,这里测试一次的结果是 73.33%,数据显然有出入,这肯定也不是 DeepSeek 官方给出的数据有误,而是模型输出概率所导致的不一致结果。
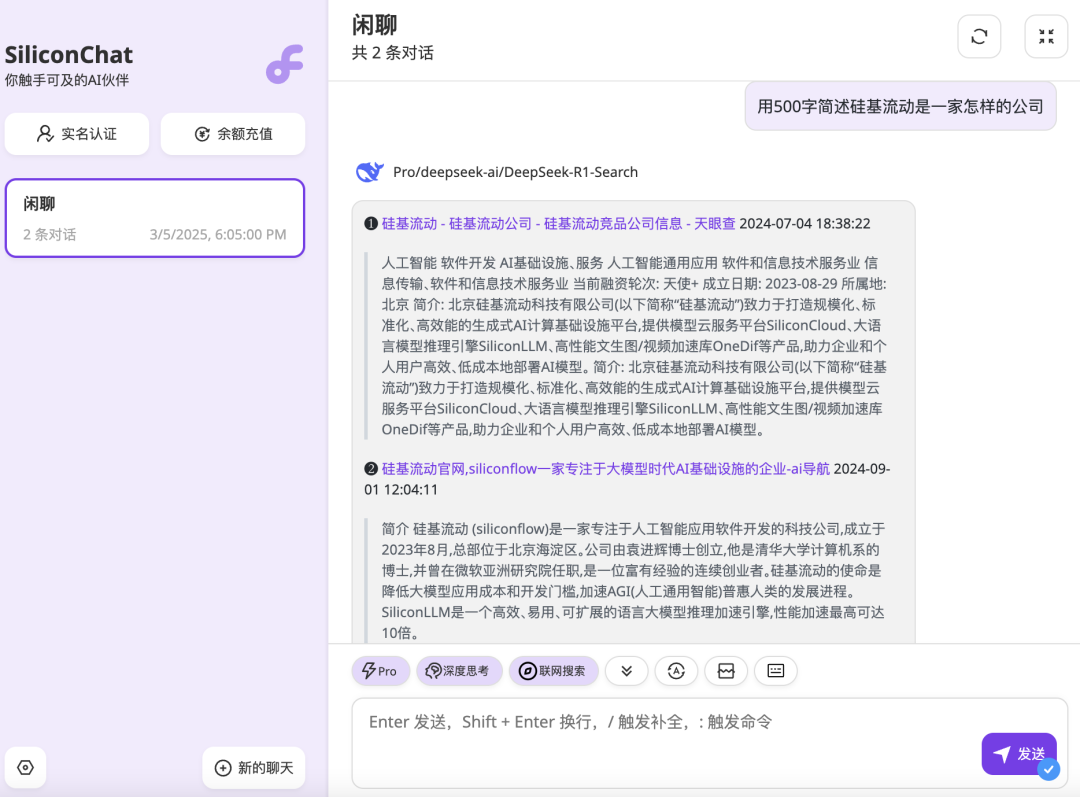
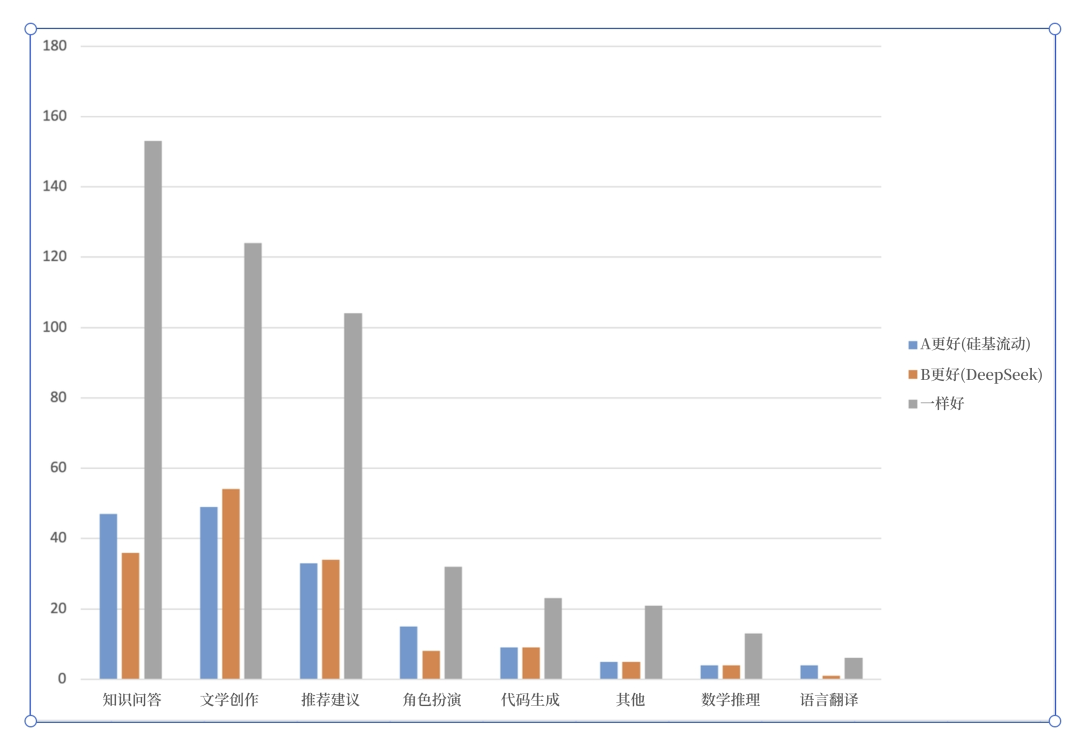
以某评测者的“人类头发数量的乘积是多少?“在各平台的单次测试为例,其结论是”可以看出,官方和国外平台都是良心的满分,其他的两个平台要点名批评,不知道在做什么。“事实是,多测试几次后就会发现,硅基流动等平台也能做对,且 DeepSeek 官方平台可能会做错,这证明了大模型输出的随机性以及单次测试的局限性。也有评测者在多次测试取平均后发现,知名平台的准确率并无差异,并修正了评测结论。 (DeepSeek-R1 API 双盲测试结果对比。横坐标表示不同测试类目,纵坐标表示双盲测试下的用户偏好。)
(DeepSeek-R1 API 双盲测试结果对比。横坐标表示不同测试类目,纵坐标表示双盲测试下的用户偏好。)
误区:“测试了四道题,xx、xx、xx 等平台的生成内容的总字数都接近三千字,其中推理字数占比分别达到 68%、69% 以及 60%,展现出更强的逻辑延展性,相较之下,部分平台仅能提供浅层推理。”解析:再次强调,单次(或几次)测试结果充满了随机性。况且,模型输出越长不等于精度更高,好比话痨不一定更聪明。误区:“硅基流动提供了 R1 模型调用,但 90% 的调用请求都会超时 60s,只有 10% 的请求结果是正常的,计算推理速度不具有参考性,本质还是算力资源受限。”解析:在相同的测试时点,不同平台的资源占用情况可能不一,单次(或几次) API 效果与速度测试的结果存在较大误差,较为公平的方式是测试多次取平均值。

此前,为响应诸多开发者提出的更稳定 DeepSeek-R1 & V3 服务的呼声,硅基流动 SiliconCloud 平台开始提供分为普通版(可使用免费 Token)与 Pro 版(面向付费用户,更稳定)的 R1 & V3,两套模型的能力并没有区别。不少评测仅仅测试了 SiliconCloud 平台的普通版 R1,由于该版本使用免费 Token 的用户流量非常大,尤其在白天工作时段使用高峰期较长,导致在测试时有较大概率出现模型没有输出或速度很慢,从而让不知情用户误解硅基流动 SiliconCloud 无法提供稳定的 R1 服务。
在此,恳请评测者测试时加入 Pro 版 R1,相信会有非常不错的效果。我们也在积极解决普通版 R1 资源供应的问题,建议对稳定性有较高要求的用户使用 Pro 版 DeepSeek-R1。
结语
本文以第一手、最前线的模型服务商视角解析部分评测误区,供评测者及广大用户参考,下一篇文章我们将给出更具体的大模型 API 评测建议。让我们共同努力,将更优质的评测报告与 API 服务提供给广大用户,促进 API 评测工作与 AI 云服务质量更上一层楼。






阅读原文
跳转微信打开

