index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
DeepSeek发布全新推理模型R1-Lite预览版,用户可在官方网页体验。该模型使用强化学习训练,具备超长思维链,在数学、代码和复杂逻辑推理任务上表现出色,媲美o1-preview,并公开完整思考过程。R1-Lite在AIME和codeforces等评测中超越GPT-4o。其推理过程包含大量反思和验证,数学竞赛得分与思考长度正相关。用户可在chat.deepseek.com选择“深度思考”模式体验。正式版DeepSeek-R1将完全开源,并提供API服务。
🚀 DeepSeek R1-Lite预览版模型正式上线,用户可在官方网页体验其强大的推理对话功能,该模型采用强化学习训练,具备数万字的超长思维链。
💡 R1-Lite在数学(AMC)和编程(codeforces)等权威评测中表现卓越,大幅超越GPT-4o等知名模型,展现了全面提升的推理性能。
🤔 模型推理过程包含大量反思和验证,其在数学竞赛中的得分与测试所允许的思考长度呈正相关,表明更长的思维链能带来更高的效率。
💻 “深度思考”模式专为数学、代码等复杂逻辑推理问题设计,提供全面、清晰、严谨的解答,充分展现长思维链的优势。
原创 深度求索 2024-11-20 19:59 北京
推理性能媲美 o1-preview,公开完整思维链

今天,DeepSeek 全新研发的推理模型 DeepSeek-R1-Lite 预览版正式上线。所有用户均可登录官方网页 (chat.deepseek.com),一键开启与 R1-Lite 预览版模型的超强推理对话体验。DeepSeek R1 系列模型使用强化学习训练,推理过程包含大量反思和验证,思维链长度可达数万字。该系列模型在数学、代码以及各种复杂逻辑推理任务上,取得了媲美 o1-preview 的推理效果,并为用户展现了 o1 没有公开的完整思考过程。全面提升的推理性能
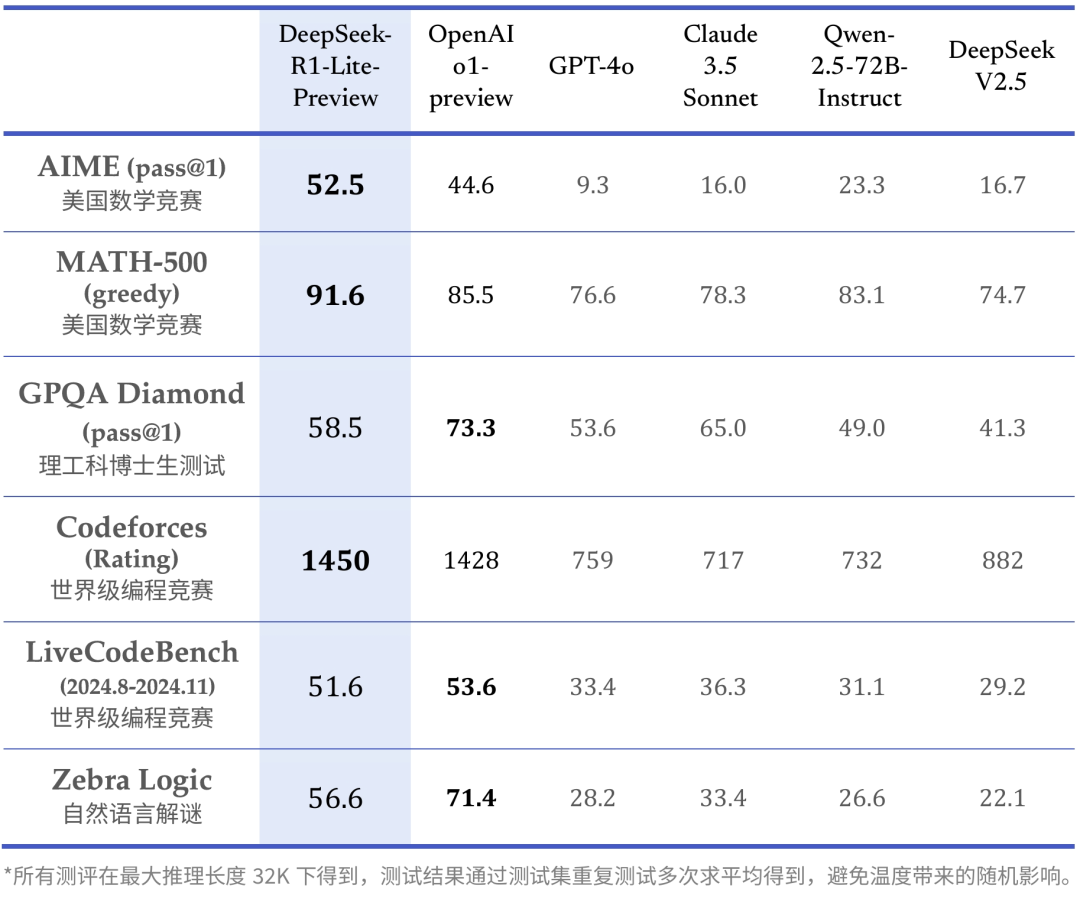
DeepSeek-R1-Lite 预览版模型在美国数学竞赛(AMC)中难度等级最高的 AIME 以及全球顶级编程竞赛(codeforces)等权威评测中,均取得了卓越的成绩,大幅超越了 GPT-4o 等知名模型。
下表为 DeepSeek-R1-Lite 在各项相关评测中的得分结果:

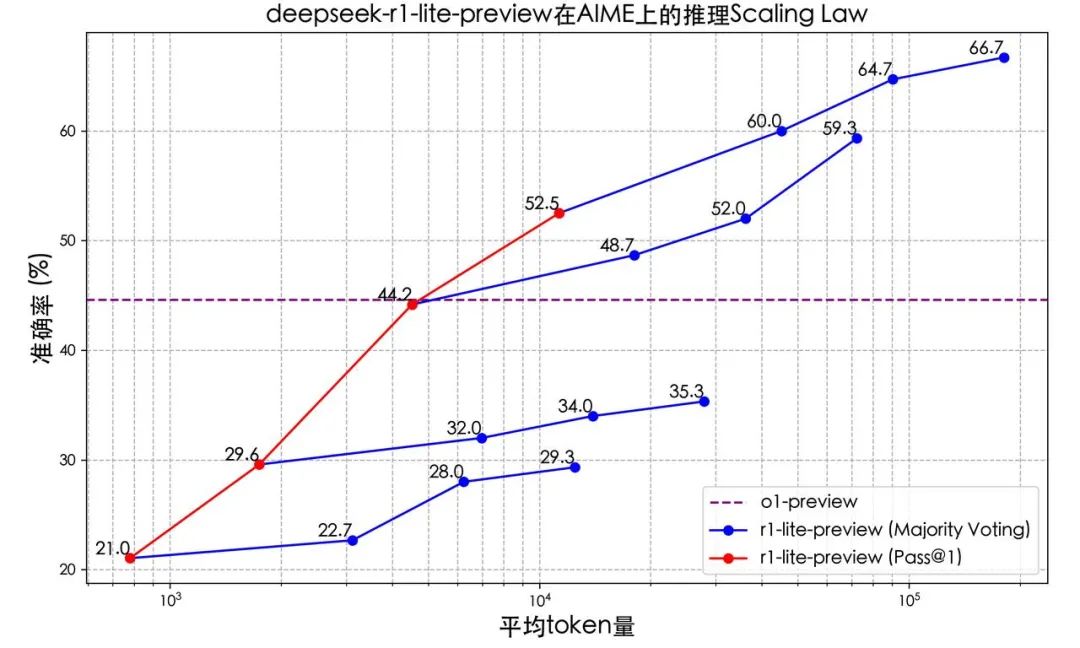
深度思考的效果与潜力
DeepSeek-R1-Lite 的推理过程长,并且包含了大量的反思和验证。下图展示了模型在数学竞赛上的得分与测试所允许思考的长度紧密相关。全面上线,尝鲜体验
登录 chat.deepseek.com,在输入框中选择“深度思考”模式,即可开启与 DeepSeek-R1-Lite 预览版的对话。“深度思考” 模式专门针对数学、代码等各类复杂逻辑推理问题而设计,相比于普通的简单问题,能够提供更加全面、清晰、思路严谨的优质解答,充分展现出较长思维链的更多优势。
新的开始,敬请期待
DeepSeek-R1-Lite 目前仍处于迭代开发阶段,仅支持网页使用,暂不支持 API 调用。DeepSeek-R1-Lite 所使用的也是一个较小的基座模型,无法完全释放长思维链的潜力。当前,我们正在持续迭代推理系列模型。之后,正式版 DeepSeek-R1 模型将完全开源,我们将公开技术报告,并部署 API 服务。




阅读原文
跳转微信打开

