DeepSeek-VL2视觉模型正式开源,它采用了DeepSeek-MoE架构配合动态切图,实现了视觉能力的全面升级。该模型在视觉定位、梗图解析、OCR和故事生成等多个方面均有出色表现。DeepSeek-VL2 拥有3B、16B和27B三种规格,其训练数据量是一代DeepSeek-VL的两倍,并引入了梗图理解、视觉定位和视觉故事生成等新功能。模型通过切图策略支持动态分辨率图像,语言部分则采用MoE架构,实现了低成本高性能的训练。模型和论文均已发布,可在Hugging Face和GitHub上下载。
🚀 DeepSeek-VL2模型采用DeepSeek-MoE架构,配合动态切图,大幅提升了视觉能力,并在视觉定位、梗图解析、OCR和故事生成等任务中表现出色。
🖼️ DeepSeek-VL2支持动态分辨率图像,最高可达1152x1152,并能处理1:9或9:1的极端长宽比,这得益于其采用的切图策略,将图像分割为多张子图和一张全局缩略图。
💡 DeepSeek-VL2具备强大的图表理解能力,能够解析各种科研图表,甚至可以根据图表生成代码,辅助用户进行逆向绘图。
🐳 DeepSeek-VL2通过大规模训练数据,具备了识别和解析各种梗图的能力,甚至比用户更了解梗图的含义。
👁️ DeepSeek-VL2还支持Zero-shot grounding和In-context grounding,能够根据自然语言描述或示例在图像中定位物体,并具备视觉语义对话能力和视觉故事生成能力。
原创 深度求索 2024-12-13 20:14 北京
视觉模型迈入 MoE 时代

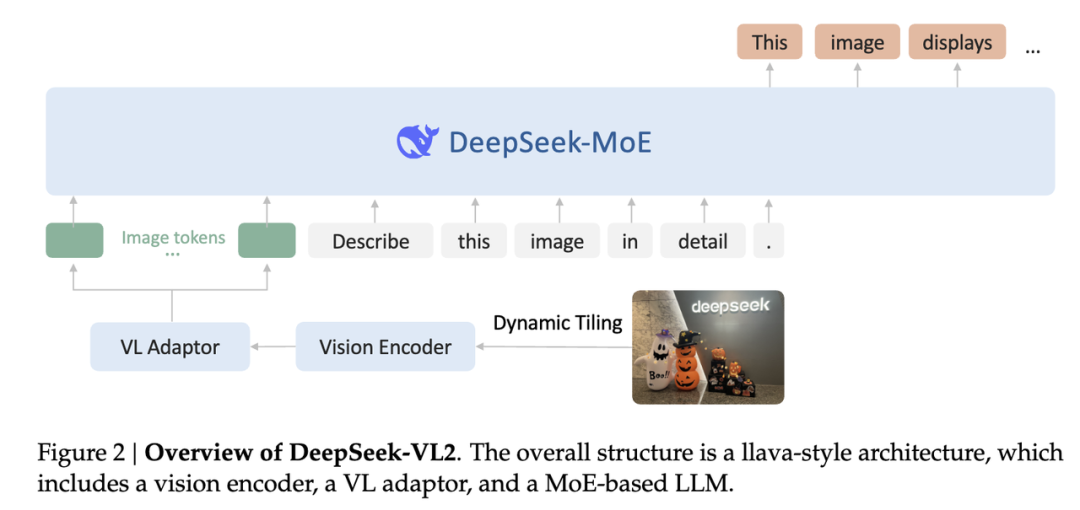
阔别九月,大家期待的 DeepSeek-VL2 终于来了!DeepSeek-MoE 架构配合动态切图,视觉能力再升级。从视觉定位到梗图解析,从 OCR 到故事生成,从 3B、16B 再到 27B,DeepSeek-VL2 正式开源。模型亮点
数据:比一代 DeepSeek-VL 多一倍优质训练数据,引入梗图理解、视觉定位、视觉故事生成等新能力架构:视觉部分使用切图策略支持动态分辨率图像,语言部分采用 MoE 架构低成本高性能训练:继承 DeepSeek-VL 的三阶段训练流程,同时通过负载均衡适配图像切片数量不定的困难,对图像和文本数据使用不同流水并行策略,对 MoE 语言模型引入专家并行,实现高效训练

模型和论文均已发布:
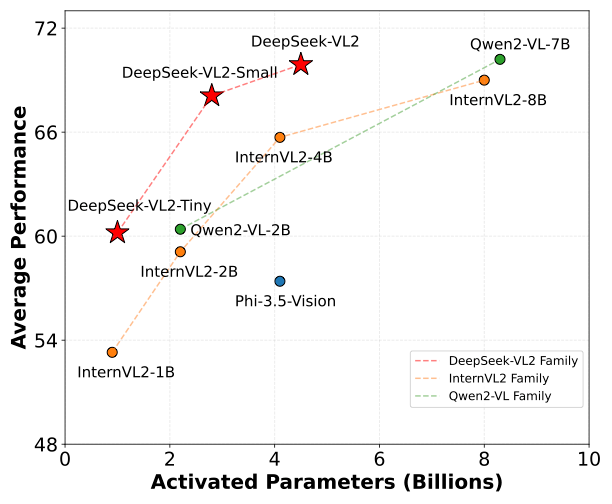
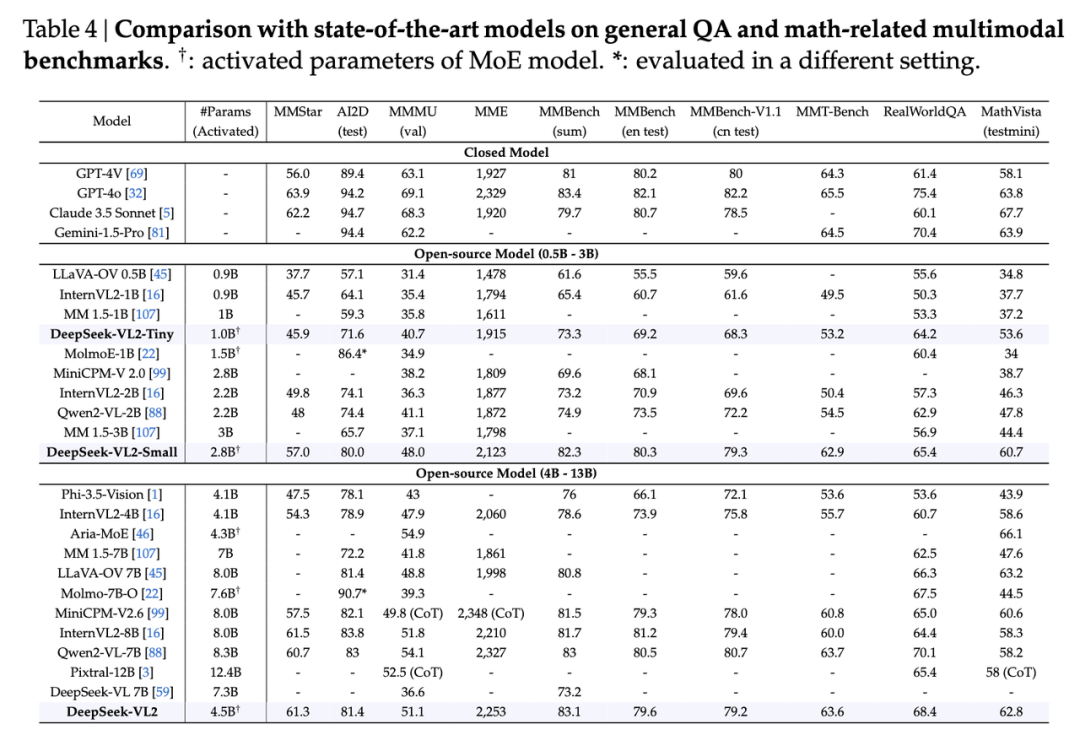
DeepSeek-VL2 模型展现出了符合我们预期的强大能力,在各项评测指标上均取得了极具优势的成绩:
案例展示
动态分辨率支持
DeepSeek-VL2 仅使用一个 SigLIP-SO400M 作为图像编码器,通过将图像切分为多张子图和一张全局缩略图来实现动态分辨率图像支持。这一策略使得 DeepSeek-VL2 最多支持 1152x1152 的分辨率和 1:9 或 9:1 的极端长宽比,适配更多应用场景。图表理解
更多科研文档数据的学习使得 DeepSeek-VL2 可以轻易理解各种科研图表。Plot2Code
DeepSeek-VL2 同时具备图像理解和代码生成的功能,可以作为你逆向画图的好帮手。
Prompt: Draw a plot similar to the image in Python.
梗图识别
更大规模的训练数据赋予了 DeepSeek-VL2 解析各种 Meme 的能力,有时它甚至懂得比你还要多。Visual Grounding
大模型的能力绝不仅限于封闭类别的物体识别。
Zero-shot grounding:你可以用任意的自然语言进行描述,然后让 DeepSeek-VL2 帮你在图像里找到符合描述的部分(注:模型本身只是输出相应物体的边界框,而不会直接在原图上绘制边界框,下同)。例如,DeepSeek-VL2 可以在下图里找到 "DeepSeek Whale" (DeepSeek 吉祥物虎鲸):
In-context grounding:你也可以给 DeepSeek-VL2 一个示例,让它有样学样:
Prompt: <|grounding|>In the first image, an object within the black ellipse is highlighted. Please locate the object of the same category in the second image. (在第一张图中有一个物体被黑色椭圆包裹住。在第二张图中找到同类别的物体。)
Grounded conversation:视觉感知+语言推理,强强联手成就模型的视觉语义对话能力。如果你拿着下图问模型 “If you feel hot, what will you do?(如果感觉热,你会怎么做?)”,它会回答:“To cool down, you can use <|ref|>the fan<|/ref|><|det|>[[166, 460, 338, 712]]<|/det|> which is sitting on the desk.(为了降温,你可以使用 [[166, 460, 338, 712]] 位置处的风扇,它放在桌子上)”Visual Storytelling
你也可以输入多张图像,让模型把它们串联起来,形成一个小小的童话故事。视觉模型的未来
视觉是人类获取外界信息的主要来源,占据所有信息量的约 80%。然而在大模型时代,视觉方面的进展却远远落后于语言模型。我们坚信,提升模型视觉能力的意义不仅在于支持更多的输入模态,更在于全方位提升模型的感知和认知能力。欢迎加入 DeepSeek,和我们一起探索 AGI 的星辰大海。








阅读原文
跳转微信打开

