
Published on May 10, 2025 3:37 AM GMT

Note: During my final review of this post I came across a whole slew of posts on LessWrong and the Effective Altruism Forum from several years ago saying many of the same things. While much of this may be rehashing existing arguments, I think the fact that it’s still not part of many mainstream discussions means it’s worth bringing up again. Full list of similar articles at the end of the post, and I'm always interested in major things I'm getting wrong or key sources I'm missing.
After a 12-week course on AI Safety, I can't shake a nagging thought: there's an obvious (though not easy) solution to the existential risks of AGI.
It's treated as axiomatic in certain circles that Artificial General Intelligence is coming. Discussions focus on when, how disruptive it'll be, and whether we can align it. The default stance is either "We'll probably build it despite the existential risk" or "We should definitely build it, because [insert utopian vision here]".
But a concerned minority (Control AI, Yudkowsky, Pause AI, FLI, etc.) is asking: "What if we just... didn't?" Or, in more detail: "Given the unprecedented stakes, what if actively not building AGI until we're far more confident in its safety is the only rational path forward?" They argue that while safe AGI might be theoretically possible, our current trajectory and understanding make the odds of getting it right the first time terrifyingly low. And since the downside isn't just "my job got automated" but potentially "humanity is no longer in charge, or even exists", perhaps the wisest move is to collectively step away from the button (at least for now). Technology isn't destiny; it's the product of human choices. We could, and I’ll argue below that we should, choose differently. The current risk-benefit calculus simply doesn't justify the gamble we're taking with humanity's future, and we should collectively choose to wait, focus on other things, and build consensus around a better path forward into the future.

Before proceeding, let's define AGI: AI matching the smartest humans across essentially all domains, possessing agency over extended periods (>1 month), running much faster than humans (5x+), easily copyable, and cheaper than human labor. This isn't just better software; it's a potential new apex intelligence on Earth. (Note: I know this doesn’t exist yet, and its possibility and timeline remain open questions. But insane amounts of time and money are being dedicated to trying to make it happen as soon as possible, so let’s think about whether that’s a good idea).
I. Why The Relentless Drive Towards The Precipice?
The history of technological progress has largely centered on reducing human labor requirements in production. We automate the tedious, the repetitive, the exhausting, freeing up human effort for more interesting or productive pursuits. Each new wave of automation tends to cause panic: jobs vanish, livelihoods teeter on the brink, entire industries suddenly seem obsolete. But every time so far, eventually new jobs spring up, new industries flourish, and humans end up creating value in ways we never previously imagined possible.
Now, enter Artificial General Intelligence. If AGI lives up to its premise, it'll eventually do everything humans do, but better, cheaper, and faster. Unlike previous technologies that automated specific domains, AGI would automate all domains. That leaves us with an uncomfortable question: if AGI truly surpasses humans at everything, what economic role remains for humanity?
Yet here we are, pouring hundreds of billions of dollars into AI research and development in 2025. Clearly, investors, entrepreneurs, and governments see enormous value in pursuing this technology, even as it potentially renders human labor obsolete. Why such a paradoxical enthusiasm? Perhaps we're betting on new and unimaginable forms of value creation emerging as they have before, or perhaps we haven’t fully grappled with the implications of what AGI might actually mean. Either way, the race is on, driven primarily by the following systemic forces:

- Competition: Both evolution and capitalism ruthlessly select for competitive advantage. When a company develops a method to perform valuable work at lower cost and higher quality, competitors who fail to adapt simply perish. If a new human species emerged that never aged, thought 30% faster each year, and could instantly create adult offspring for a small fee, they would eventually dominate the labor force and ultimately the entire planet.Money: The economic incentives here aren’t subtle. Companies like OpenAI, Anthropic, and DeepMind see trillions in potential value. Pausing for careful alignment research looks like economic suicide, and even diverting resources to safety efforts that could instead be spent on capabilities is increasingly not the norm. Capitalism, great for optimizing quarterly returns, seems structurally incapable of prioritizing the survival of our species over short-term profits.Military Supremacy: Nation‑states notice when technology moves the “win a war” slider. Autonomous weapons, cyber capabilities, intelligence analysis – the applications are endless and potentially world-altering. The fear that "the other side" will get there first creates immense pressure to accelerate, safety protocols be damned. This dynamic resembles Cold War brinkmanship, but with potentially more catastrophic consequences and harder-to-verify constraints.Inertia & Narrative: Beyond strategic and economic drivers, there's the sheer intellectual allure – the "can we build God?" impulse. There's also a deeply ingrained cultural narrative that technological progress is linear, inevitable, and fundamentally good. Questioning AGI development can feel like challenging progress itself, which is a position few wish to adopt in innovation-worshipping cultures.
This confluence of factors creates a powerful coordination problem. Everyone might privately agree that racing headlong into AGI without robust safety guarantees is madness, but nobody wants to be the one who urges caution while others surge ahead.
II. Surveying The Utopian Blueprints (And Noticing The Cracks)
Many intelligent people have envisioned futures transformed by AGI, often painting pictures of abundance and progress. However, these optimistic scenarios frequently seem to gloss over the most challenging aspects, relying on assumptions that appear questionable upon closer inspection.
- Dario Amodei's Machines of Loving Grace: The idea of globally coordinated and equitably distributed AGI genius overlooks geopolitical competition, misuse by bad actors, power concentration risks, and the core alignment problem. Amodei assumes a level of global cooperation and foresight we've rarely, if ever, achieved on issues with far lower stakes.Sam Altman's Three Observations: Altman envisions "super-exponential" value creation solving all our problems, breezily asserting that "policy matters" will handle trifles like alignment, distribution, and preventing misuse. This feels less like a plan and more like hoping a magical abundance fairy will solve everything for us.Leopold Aschenbrenner's Situational Awareness: Aschenbrenner seems pretty sure that "superalignment... is a solvable problem." While confidence is admirable, it's not quite the same as having a solution. His whole framing seems very much like a Cold War redux ("the free world must prevail!"), treating power as a zero-sum game to be won, without lingering on the possibility that maybe the prize itself is bad for everyone involved, regardless of who "wins" the race.Nick Bostrom's Deep Utopia: Explicitly ignores the alignment and control problems to explore the philosophical landscape of a post-scarcity world where AGI caters to every whim. While an interesting thought experiment (though visions like The Metamorphosis of Prime Intellect suggest such utopias might be psychologically horrifying), the necessity of sidestepping the "how do we get there safely?" question is itself revealing. Moreover, many readers (myself included) might find his utopian vision fundamentally unsatisfying rather than aspirational.
These examples highlight a pattern: optimistic visions often depend on implicitly assuming the hardest problems (alignment, control, coordination, governance) will somehow be solved along the way.
III. Why AGI Might Be Bad (Abridged Edition)
Not all visions of an AGI future are rosy. AI-2027 offers a more sobering, and frankly terrifying, scenario precisely because it takes the coordination and alignment problems seriously. Many experts have articulated in extensive detail the numerous pathways through which AGI development might lead to catastrophe. Here's a succinct overview, helpfully categorized by the Center for AI Safety (and recently echoed by Google's AGI Safety framework):
- Malicious use: Hostile actors deploying AI for mass destruction (e.g., terrorists leveraging AI to engineer devastating pathogens). This category should also encompass scenarios where those controlling AI impose decisions on humanity that significant segments would reject upon reflection (i.e., human non-alignment amplified by AI power).AI race: Competitive pressures that could drive us to deploy AIs in unsafe ways, despite this being in no one’s best interest. For instance, nations increasingly delegating military decision-making to AI systems to maintain strategic parity, reducing human oversight in situations where, historically, human judgment prevented catastrophe (consider the Cuban Missile Crisis). These pressures might also accelerate the replacement of human labor across domains, resulting in gradual disempowerment.Organizational risks: Accidents stemming from AI complexity and organizational limitations. Even industries with robust safety cultures experience occasional disasters (e.g., aviation and nuclear power). The AI industry involves less-understood technology and demonstrably lacks the safety culture and regulatory frameworks present in other high-risk domains. With AGI embedded throughout critical infrastructure, such seemingly inevitable mistakes could prove catastrophic.Rogue AIs: Goal alignment represents a recognized challenge with current AI systems. As AI becomes more powerful and embedded in crucial systems like economies and militaries, these problems could exponentially worsen, potentially leading to uncontrollable AI behavior. Alignment remains fundamentally unsolved, and I've argued elsewhere that conceptualizing it as a solvable technical problem may constitute a category error.
Particularly revealing are statements from leaders of top AI laboratories who have, at various points, acknowledged that what they're actively building could pose existential threats:

- Sam Altman (CEO OpenAI): “The bad case — and I think this is important to say — is like lights out for all of us.” - Jan 2023Dario Amodei (CEO Anthropic): “My chance that something goes really quite catastrophically wrong on the scale of human civilization might be somewhere between 10% and 25%.” - Oct 2023Elon Musk (CEO xAI): “What are the biggest risks to the future of civilization? It is AI - it’s both positive and negative, it has great promise, great capability, but also with that comes great danger.” - Feb 2023Demis Hassabis (CEO Google DeepMind): “We must take the risks of AI as seriously as other major global challenges, like climate change [...] It took the international community too long to coordinate an effective global response to this, and we’re living with the consequences of that now. We can’t afford the same delay with AI.” - Oct 2023
These are not the anxieties of distant observers or fringe commentators; they are sober warnings issued by those intimately familiar with the technology's capabilities and trajectory. The list of concerned researchers, ethicists, policymakers, and other prominent figures who echo these sentiments is extensive. When individuals working at the forefront of AI development express such profound concerns about its potential risks, a critical question arises: Are we, as a society, giving these warnings the weight they deserve? And, perhaps more pointedly, shouldn't those closest to the technology be advocating even more vociferously and consistently for caution and robust safety measures?
IV. Existence Proofs For Restraint: Sometimes, We Can Just Say No

Okay, but can we realistically stop? The feeling of inevitability is strong, but history offers counterexamples where humanity collectively balked at deploying dangerous tech:
- Biological Weapons: The 1975 Biological Weapons Convention (BWC) banned development and stockpiling. Driven by moral horror and proliferation fears (helped by the US unilaterally halting its offensive program), it created a strong global norm. It's not perfect – verification is hard due to dual-use tech, and compliance hasn't been universal (Biopreparat, anyone?). Additionally, there wasn’t any direct economic incentive and other more effective weaponry made this a relatively easy choice.Atmospheric Nuclear Testing: Public outcry over radioactive fallout (e.g., from the Castle Bravo test) spurred the 1963 Partial Test Ban Treaty (PTBT). This treaty significantly cut atmospheric radiation and showed that even rival superpowers could collaborate on shared existential threats. However, its relevance as a model for halting a technology is limited: it didn't stop the nuclear arms race (testing simply moved underground) and lacked universal adoption. Crucially, with no economic drivers for atmospheric testing itself and alternative testing methods available, the PTBT represented more a redirection of nuclear development than a cessation of an entire technological trajectory.Nukes in Space: The 1967 Outer Space Treaty banned weapons of mass destruction in orbit. Despite the obvious strategic advantages, the fear of nuclear fallout from launch failures or accidental orbits, the ease of verification (nuclear armed satellites are relatively easy to detect), and the shared desire to keep space exploration peaceful helped the US and USSR agree.Asilomar Conference on Recombinant DNA (1975): When recombinant DNA emerged, scientists themselves paused certain experiments and convened to create safety guidelines. This proactive, scientist-led effort allowed the field to advance more safely, largely avoiding major public backlash or heavy-handed regulation (at least initially).Human Cloning: Near-universal ethical revulsion post-Dolly led to widespread bans and condemnation, establishing a powerful norm even without a perfect global treaty. The long feedback cycles due to human development timelines and the moral/ethical aversion to the possibility of negative outcomes made this choice a lot easier than choosing to approach AGI with extreme caution.
For more examples of technological restraint, see this analysis, this report, and this list.
Important Caveats: These historical analogies are imperfect:
- Verifying compliance with potential AGI restrictions is likely far harder than monitoring missile silos or atmospheric tests.The dual-use problem with AI is extreme: the same hardware, algorithms, and datasets used for beneficial AI could potentially fuel dangerous AGI development.The economic and military incentives for AGI might also dwarf those associated with past restricted technologies.Many of these successful agreements occurred during a specific geopolitical window (roughly 1963-1975) that may have been unusually conducive to such cooperation.As cautionary tales like Tokugawa Japan's attempt at unilateral technological stagnation show, such efforts likely require broad international coordination to succeed long-term. Isolated restraint often just means falling behind.
Nevertheless: These examples prove that "inevitable" is a choice, not a physical law. They show that international coordination, moral concern, and national regulation can put guardrails on technology.
V. So, What's The Alternative Path?
If the AGI highway looks like it leads off a cliff, what's the alternative? It starts by expanding the Overton Window: making "Let's not build AGI right now, or maybe ever" a discussable option. There are concrete policy proposals that have been put out by various people and institutions that set us down this safer path, we just need to collectively choose to walk it.
Pause All Frontier AI Development: This is the position of groups like Pause AI and Eliezer Yudkowsky, but I don’t think that it’s feasible at the moment and it’s not quite warranted just yet. Carl Shulman makes some compelling arguments here regarding:
- A pause becomes more impactful the closer to AGI it occurs. (One counterpoint: the closer we are to AGI at the time of a pause, the more momentum in the industry in general and the easier it is for a defector to break ranks and cross the finish line).If a temporary pause doesn’t “work” (i.e., give us the time to conclusively solve the existential risks or build robust governance), then future calls for pauses become less likely due to a "Boy Who Cried Wolf" effect.A pause would only be helpful if it was universal or nearly so, otherwise it just is a minor delay by removing some of the force pushing accelerating capabilities.There are more impactful, less costly, and more likely to work actions that could be taken on a policy front, and we should prioritize those.
However, this doesn't negate the value of the "pause" concept entirely. A more promising approach might be to build broad consensus now that certain future developments or warning signs would warrant a coordinated, global pause. If there’s No Fire Alarm for AGI, perhaps the immediate task is to build the political and institutional groundwork necessary to install one (agreeing on what triggers it and how we would respond) before the smoke appears.
Focus on Non-Existential AI: Anthony Aguirre's framework in "Keep the Future Human" seems useful: develop AI that is Autonomous, General, or Intelligent, maybe even two out of three, but avoid systems that master all three. We can build incredibly powerful tools and advisors without building autonomous agents that could develop inscrutable goals.
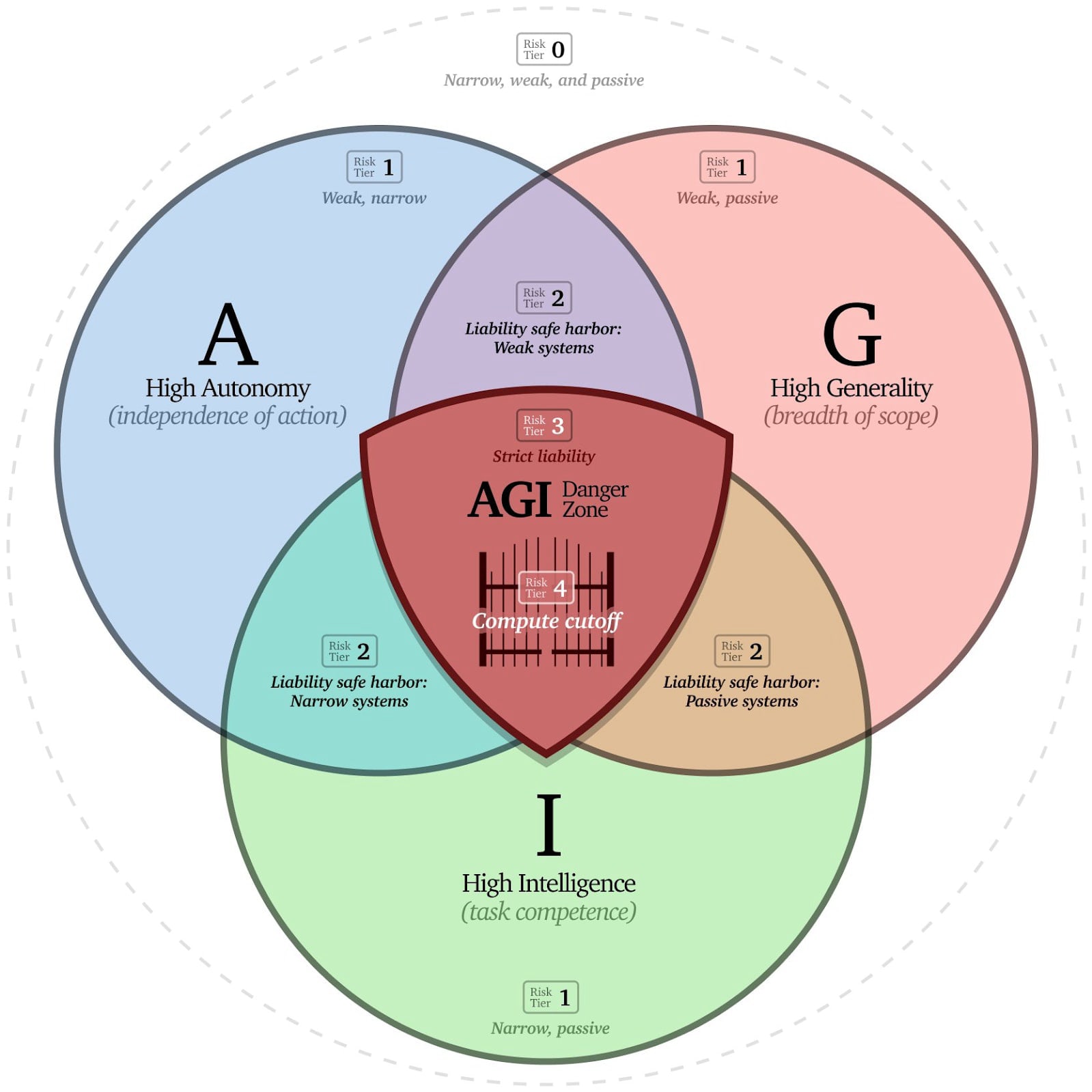
The “AGI Venn Diagram” from Anthony Aguirre, proposing a tiered framework for evaluating and regulating AI systems.
- Intelligent: AlphaFold (predicting protein structures).Intelligent + Autonomous: Self-driving cars (still struggling, notably).Intelligent + General: Current large language models like Claude or GPT-4 (useful, but not agentic planners).
This "tool AI" path offers enormous benefits – curing diseases, scientific discovery, efficiency gains – without the same existential risks. It prioritizes keeping humans firmly in control.
Focus on Defensive Capabilities: Vitalik Buterin’s “d/acc: decentralized and democratic, differential defensive acceleration” concept offers another framing. Buterin makes a good point that regulation is often too slow to keep up and might target the wrong things (e.g., focusing only on training compute when inference compute is also becoming critical). He pushes instead for liability frameworks or hardware controls, but above all, focusing development on capabilities that make humanity more robust and better able to defend itself. Helen Toner has made an excellent case for why we should focus some amount of our efforts here regardless. She notes that as AI capabilities become cheaper and more accessible over time, the potential for misuse inevitably grows, necessitating robust defenses. The folks at Forethought also recently released an excellent paper pointing towards specific areas of development that would be especially helpful in navigating the coming existential risks.

A stylized version of Vitalik Buterin’s catchy image of humanity’s current state.
Unfortunately, just how to ensure that no critical mass of actors choose one of the three “bad” paths above is left as an exercise for the reader.
What We Should Do (For Various Scopes of “We”):
- Globally: Serious international talks are needed, moving beyond pleasantries to binding agreements. Could we govern access to the massive compute clusters necessary for training and running frontier models? Shared monitoring, international safety standards, and agreements on capability thresholds should all be on the table. The first step is picking up the phone (US and China, looking at you). The next is agreeing on the critical risks and finding common ground, ideally focusing on strategies that clearly benefit everyone. Neither country wants rogue actors getting major boosts to CBRN capabilities, power concentrated uncontrollably in a single corporation, or a misaligned intelligent AI. More serious attempts should be made at drafting international treaties and establishing norms.Nationally: Mandatory safety evaluations, transparency requirements, liability frameworks, mandating whistle-blower protections and a significant shift in government funding towards safety research and "tool AI" rather than just frontier capabilities. The US legislative branch is not known for its speed these days, so focusing on aspects attractive across party lines is key (transparency seems like a good candidate). Export controls on AI chips should continue and update as key bottlenecks become clearer. We need to get executive and legislative leadership up to speed on the key risks we’re facing so that discussions can shift to how and when to address them.State Level: Given the federal gridlock, state-level legislation might be a more likely path, potentially serving as templates for federal action later. The same principles apply: get state politicians on board with the general idea, then focus regulations on reducing catastrophic and existential risks. While some attempts have been good (like California’s SB 1047), many others (like the proposals in Texas or the EU AI Act) have focused mostly or entirely on short-term, mundane harms better addressed by existing laws.Corporate Level: AI companies need real internal governance, serious investment in safety (not just safety PR), transparency, and willingness to pause if safety benchmarks aren't met. Most leading AI companies are already part of the Frontier Model Forum, which is a good start for aligning on safety commitments. Instead of moving to erase the excellent “stop competing and start assisting” clause from its charter, OpenAI and other leading AI companies should be clarifying and strengthening such industry-wide agreements and norms around responsible development and restraint.Individually: Engage in informed discussion, raise awareness about the stakes, and advocate for sensible policy. Reach out to your senators and representatives. If you work in AI, prioritize safety, speak up internally, and refuse to build differentially offensive or dangerous capabilities. Demand action from leaders and politicians.

VI. Addressing The Inevitable Objections
Any argument for slowing or stopping AGI development inevitably encounters pushback. Yoshua Bengio, one of the “Godfathers of AI” has written eloquently about the arguments against taking AI Safety seriously, but I’ll quickly address some of the most common:
- "It's inevitable! Stop being a Luddite!" History shows technological trajectories are not predetermined laws of physics. And this isn't smashing looms; it's questioning whether building potentially self-replicating, superintelligent loom-operators we can't control is wise. As Katja Grace put it so eloquently, “If you think AGI is highly likely to destroy the world, then it is the pinnacle of shittiness as a technology. Being opposed to having it into your techno-utopia is about as luddite as refusing to have radioactive toothpaste there.”"We NEED AGI to solve X (climate, cancer)!" Do we? Or can advanced narrow AI achieve much of this? The potential benefits of AGI are immense, but the potential cost is literally everything. Risk management suggests exploring safer paths first. If your house is on fire, you don't reach for the experimental fusion-powered fire extinguisher that might also level the city."Coordination is impossible! Someone will cheat!" Hard, yes. Impossible? Arms control shows partial success is achievable. Assuming impossibility is self-fulfilling. The harder it is, the more urgent it is to start trying. And how difficult cooperation is really depends on the exact details of the game theoretical situation, which are extremely unclear."Pausing harms innovation! Bad actors win!" The proposal isn't stopping all AI, but steering away from the AGI cliff as we frantically convince the driver(s) that we are in fact speeding towards a cliff. Safer AI innovation can flourish. And if alignment is unsolved, any AGI is a potential catastrophe, regardless of who builds it first."This is just Big Tech trying to lock out competition (regulatory capture)!" A valid concern. Regulations must be designed carefully. But the core risks are highlighted by many independent academics and non-profit researchers, not just incumbents. And much of the proposed regulations would only apply to Big Tech themselves, not small startups or open source models. We can fight regulatory capture while still taking the existential risks seriously."If we don't, China/[insert adversary] will!" The geopolitical race dynamic is real and dangerous. But again, see arms control. Treaties, export controls, mutual deterrence – these tools exist. Making the danger clear enough to overcome rivalry is the challenge. A world where only China has AGI might be bad; a world where anyone has misaligned AGI could be worse.
VII. Conclusion: Choosing Not To Roll The Dice

Maybe safe AGI is possible. Maybe scaling laws will hit a ceiling sooner than we think, or we’ll run out of compute/energy before models get dangerously capable. Maybe alignment is easier than it looks. Maybe the upsides justify the gamble.
I am increasingly skeptical.
The argument here isn't that stopping AGI development is easy or guaranteed, or even that we need to do it right now. It's that not developing AGI until we’re confident that it’s a good idea is a coherent, rational, and drastically under-discussed strategic option for humanity. It's risk management applied to the ultimate tail risk.
Instead of accelerating towards a technology we don't understand, can't reliably control, and whose many failure modes could be terminal, driven by competition and fear... perhaps we should coast for a bit, and prepare to hit the brakes. Perhaps we should invest our considerable resources and ingenuity into developing AI that demonstrably empowers humanity, into rigorously mapping the potential failure modes of advanced AI, and into building the global consensus and governance structures needed to navigate the path ahead safely, rather than blindly racing towards a potential existential cliff.
Sometimes, the smartest thing to build is a brake (and the consensus that we need one).
List of articles and posts advocating similar things for similar reasons:
- Let’s think about slowing down AI — LessWrong (this one was particularly in depth and compelling)List of requests for an AI slowdown/halt. — LessWrongSlowing AI - LessWrongWhat an actually pessimistic containment strategy looks like — LessWrongAdam Scholl on X: "I think it's generally bad to work on AI capabilities. Not always (since alignment tech is often dual-use), and not forever (since never building TAI seems awful). But broadly, I think we should not build extremely powerful AI systems before we figure out how to make them safe." and a following list of referencesSlowing down AI progress is an underexplored alignment strategy — EA Forum
Discuss
