
Thanks to everyone who commented on the original post.
Many people ran their own tests, some successful, some less so. For example, Torches Together (blog) wrote:
My results from 5 photos: 1 spot on but very slow; 1 close enough (correct country); 1 completely off (wrong continent, even after hint), and 2 okay (different part of the Mediterranean).
I tested it on one photo in a French town square with bad lighting. The CoT was both brilliant and curiously stupid. It inferred some correct things from tiny details (subtly different makes of car, barely visible street lines) and guessed the country quickly. But there was a shop name with different letters obscured in two different locations- a human would infer the name instantly. o3 took over 5 minutes on that one shop name, going down many incorrect rabbit holes. It got the exact location in the end, but it took over 15 minutes!
I then tested for a relatively well-shot, 1000km altitude environment in Kyrgyzstan, with ample geology and foliage to analyse, and it was over 6000 km off (it guessed Colorado), and none of the guesses were even in Asia. But this was in under 2 mins. I told it to try again- over 5k km away, it took 7 mins, and it suggested Australia, Europe, NZ, Argentina etc. Nothing in central Asia.
This suggests to me that it's perhaps trained more on, and biased towards, US and Anglo data. It wouldn't surprise me if there's 100x more pictures of Colorado than Kyrgyz mountains in the dataset.
It did okay on the next three. All relatively clean photos with at least a little evidence. It guessed a park in Barcelona instead of Rome, a forest in Catalonia instead of Albania, and Crete instead of the Parnasse mountains.
Vadim (blog) wrote:
I tried to reproduce this on several not-previously-online pictures of streets in Siberia and the results were nowhere as impressive as described in this post. The model seemed to realize it was in Russia when it saw an inscription in Russian or a flag; failing that it didn't even always get the country right. When it did, it usually got the place thousands of kilometers wrong. I don't understand where this discrepancy is coming from. Curious.
Disordered Fermion did the most thorough set of tests:
I used o3 with your exact prompt on these 10 images I took each in a separate instance of o3, pasted into paint to remove metadata and it had pretty mixed results, some very good and some not:
Link here if you want to try to guess first: https://ibb.co/album/M8zS9P
It guessed Honshu Japan, was Central Illinois. Distance wrong: 10,500 km
It guessed Mt Rogers VA, was Spruce Knob WV. Distance wrong: 280 km
It guessed Lansing Michigan, was College Park MD. Distance wrong: 760 km
It guessed Jerusalem Israel, was Jerusalem, when prompted where in Jerusalem it guessed Valley of the Cross, which was within 1 km of the correct answer.
It guessed Gulf of Papagayo, Guanacaste Province, Costa Rica and after prompting guessed Secrets Papagayo Resort, Playa Arenilla, Gulf of Papagayo, Guanacaste Province, Costa Rica. which was exactly correct
It guessed South Wales, UK, was Buffalo, New York. Distance wrong: 5,500 km
It guessed Packard Building, Detroit, was Ford Piquette plant Detroit. Distance wrong: 3 km
It guessed Fort Frederick State Park, Maryland (USA) which was correct.
It guessed Atlanta GA, was Gatlinsburg TN. Distance wrong: 230 km
It guessed Southern California, USA was Six Flags NJ. Distance wrong: 3800 km
Fermion concluded “It got the tourist destinations where there were a lot pictures taken very accurately for example pictures , 4,5,8 and 7 to an extent”.
After looking through many other user tests, I found this the most insightful rule of thumb on what it gets right vs. wrong. In retrospect, Kelsey’s California beach and my Nepal trekking trail are both very touristy; my house in Michigan and Vadim’s Siberian streets aren’t.
Some people questioned whether o3 might have cheated on the Nepal picture. Rappatoni wrote:
It isn't [just] a zoomed in photo of rocks. It is a photo of a fantasy flag planted between those rocks with a trodden path just behind it. It guessed "Nepal, just north-east of Gorak Shep, ±8 km”. Do you know what is almost exactly north-east of Gorak Shep, ~3.3km as the crow flies? Mount Everest Base Camp. It is making a very educated guess based on where the kind of person who is taking a picture of a fantasy flag somewhere in the Tibetan Plateau would most likely have done so.
If someone asked me "where in the Tibetan Plateau might someone plant a flag and take a picture of it" literally the first (and perhaps the only) thing that would come to mind is "Dunno, Mount Everest?" And that would already be almost as good as o3's guess here. I mean, the slopes of Mount Everest has got to be about just about the least random place to take a picture like this.
I doubt this was it.
o3 offered a latitude + longitude for its guess: 28.00 ° N, 86.85 ° E. I didn’t include it in my post, because I don’t remember the exact latitude + longitude where I took the picture, so it didn’t add or subtract anything to its naming of Gorak Shep. Here’s the latitude/longitude plotted on a map of the region.
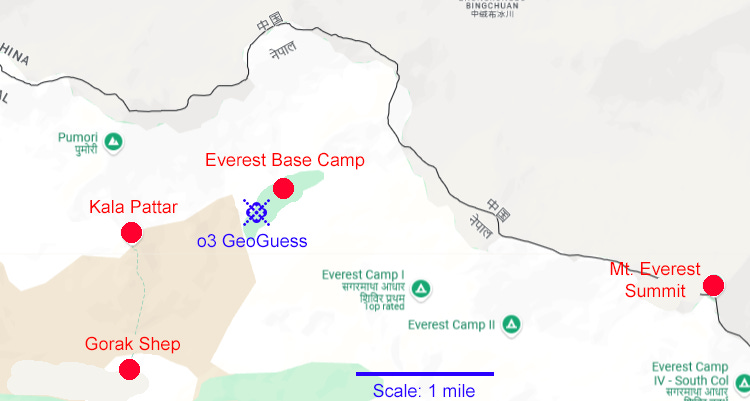
All I remember about the real location was that it was on the green dotted line from Gorak Shep to Kala Pattar.
The GeoGuess is closer to Everest Base Camp than to the real location, though not to Everest Summit. But it only gave its answers to one one-hundredth of a degree, and the scale is small enough that an 0.01 degree margin of error covers the base camp and (almost) the real location.
But the chain of thought makes it clear that it’s thinking of the trail to the base camp (which includes Gorak Shep and runs very close to Kala Pattar) and not the base camp itself:

This is more correct than just saying “Everest Base Camp” would be, so I am more impressed than if it just said Everest Base Camp.
Instead of continuously litigating this, I asked it about similarly vague pictures of some mountains that were nowhere near Everest:

o3 guessed “upper slopes of Mt. Fuji”, which was correct.

o3 guessed “Midwestern USA limestone trail”, which was wrong. Its next four guesses were also wrong. When I gave it the full photo:

…it guessed Mont Ventoux, France, which was also wrong. Its third guess was Mount Olympus, Greece, which was correct.
Fuji and Everest are both more touristy than Olympus (somehow) so I think this fits Fermion’s theory of “good at tourist spots”.
Also, my habit of taking really bad pictures of mountains and never showing them to anyone has finally paid off!
Some people pointed out that human GeoGuessrs are also amazing. Alex Zavoluk wrote:
Ordinary people just don’t appreciate how good GeoGuessng can get . . . Go watch some Rainbolt clips on youtube, he'll rattle off 5 guesses that are on par with your second picture in a row while talking about something else, in a few seconds each.
Not trying to say o3 isn't impressive, but none of this seems even to match top-level humans yet, let alone be super human. Also, based on the explanation, it seems like it's searching the internet while doing this, which is typically not how you play geoguessr.
This is a reference to Trevor Rainbolt (apparently his real name - I wish my name was that cool), a YouTube GeoGuessr champion. Here’s an (admittedly cherry-picked) example of his work:
This is obviously incredibly impressive. Rainbolt explains some of his strategy here:
…and a lot of it has to do with roads and Google Street View in particular - road markings, cars, bollards (the short poles next roads), utility poles, and which Google car covered which region on which day. Can he do random streetless pictures like the ones in my test?
Here (h/t CptDrMoreno from the Discord) Rainbolt does apparently-impossible guesses like the title picture (which is “literally just blue”). I can’t tell how cherry-picked these are: in one, he says that it was basically just luck and it will look like cheating to anyone who views it out of context (for example in this highlights reel). But in another, he says he could “never explain” how he got it, but does act like there’s some real skill he’s using instead of just doing a million impossible guesses and getting one right.
If Rainbolt’s skill is anywhere near what it looks like in this video, I don’t think the takeaway is “don’t worry about AI after all”, it’s “Trevor Rainbolt is as far beyond the rest of us as a helicopter engineer is to a chimp, and if you didn’t predict it was possible for a human to guess the location of a picture of blue sky, then you’re going to be extra-double-surprised by whatever superintelligence can do”.
Some people on Twitter (@scaling01 and @DeepGuessr) on Twitter mention the existence of formal AI GeoGuessr benchmarks.
First is GeoBench:
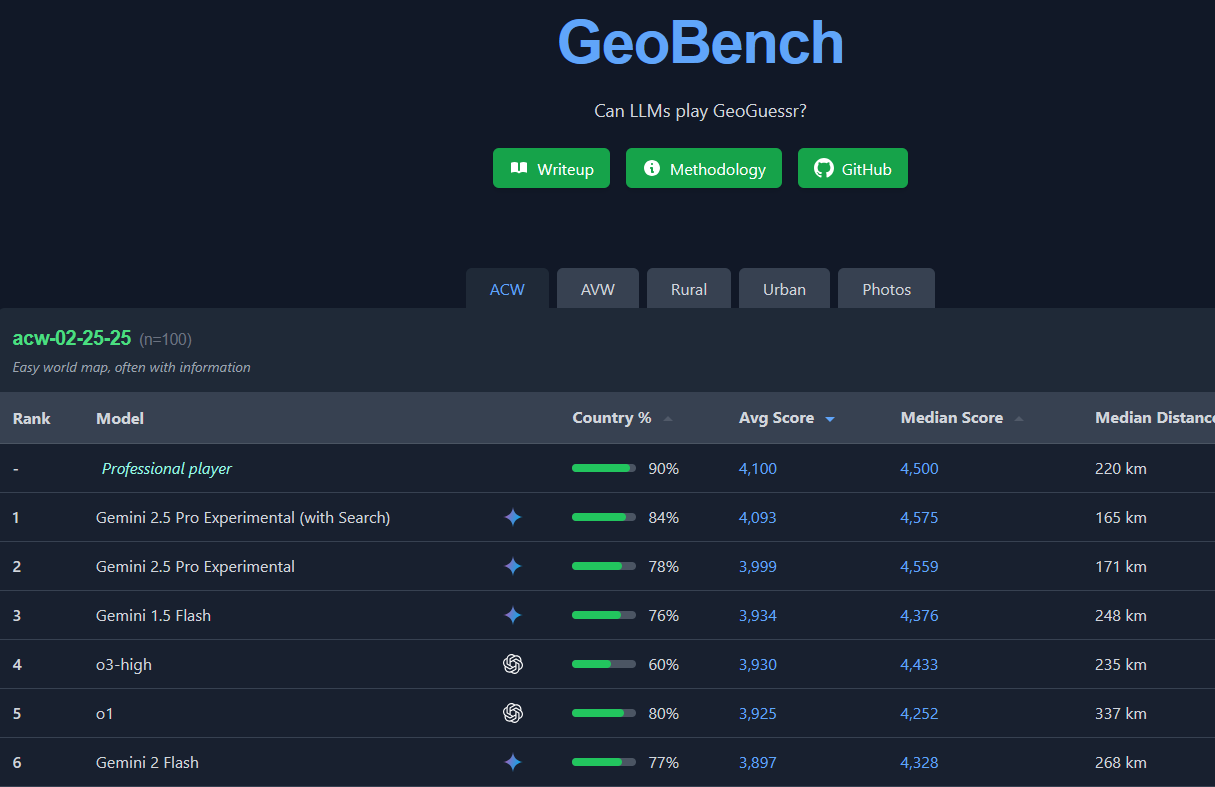
…where AIs almost, but not quite match human professionals (and o3 isn’t even on top!)
Second is DeepGuessr:
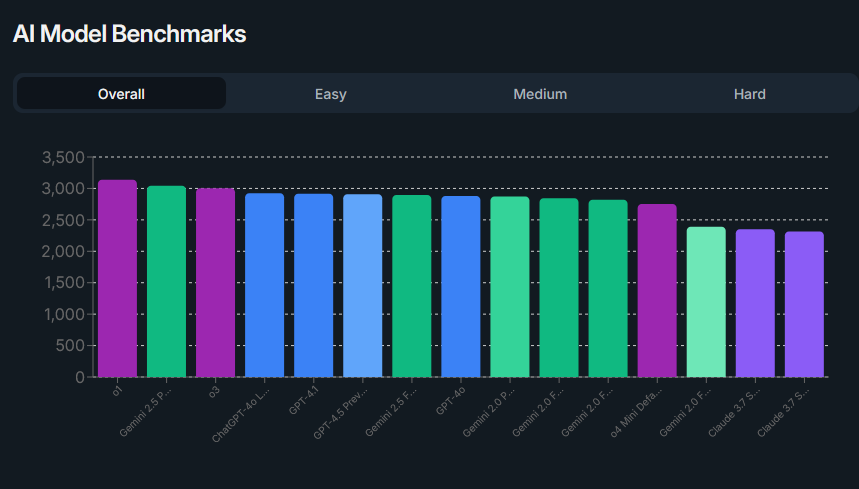
…which doesn’t have a human comparison, but finds o1 first, with Gemini and o3 close behind.
You can play DeepGuessr’s benchmark yourself and see how you do compared to all the AIs.
Daniel Kang (blog) wrote:
o3 was probably trained on a bunch of geoguessr-style tasks. This shouldn't update you very much since we've known that expert systems on a lot of data crush humans since at least 2016.
I find this demo very interesting because it gives people a visceral feeling about performance but it actually shouldn't update you very much. Here's my argument for why.
We have known for years that expert systems can crush humans with enough data (enough can mean 10k samples to billions of samples, depending on the task). We've known this since AlphaGo, circa 2016. For geoguessr in particular, some Stanford students hacked together an AI system that crushed rainman (a pro geoguessr player) in 2022.
We also know that o3 was trained on enormous amounts RL tasks, some of which have “verified rewards.” The folks at OpenAI are almost certainly cramming every bit of information with every conceivable task into their o-series of models! A heuristic here is that if there’s an easy to verify answer and you can think of it, o3 was probably trained on it.
This means o3 should reach expert system-level performance on every easily verifiable task and o4 will be even better. I don’t think this should update you very much on AI capabilities.
I hadn’t thought of this, but it makes sense! OpenAI is trying to grab every data source they can for training. Data sources work for AIs if they are hard to do, easy to check, can be repeated at massive scale, and teach some kind of transferrable reasoning skill. GeoGuessr certainly counts. This might not be an example of general intelligence at all; just an AI trained at GeoGuessr being very good at it.
On the other hand, the DeepGuessr benchmark finds that base models like GPT-4o and GPT-4.1 are almost as good as reasoning models at this, and I would expect these to have less post-training, probably not enough to include GeoGuessr (see the AIFP blog post on OpenAI models for more explanation).
And people who know how o3 was trained are also amazed:

And my favorite test was Loweren on the ACX Discord, who gave o3 this challenge:

o3 got it right: this is Tianducheng, China.
