
速览热门论文:
1.蚂蚁集团推出开源多模态框架 Ming-Lite-Uni
2.微软推出 LLM 统一框架 ARTIST:集成推理、RL 和工具
3.R1-Reward:通过稳定强化学习训练多模态奖励模型
4.语音-语言模型 Voila:实时自主交互和角色扮演
5.RM-R1:将推理整合到奖励建模中
1.蚂蚁集团推出开源多模态框架 Ming-Lite-Uni
在这项工作中,来自蚂蚁集团的研究团队推出了一个开源多模态框架——Ming-Lite-Uni,其具有新设计的统一视觉生成器和为统一视觉和语言而定制的本地多模态自回归模型。
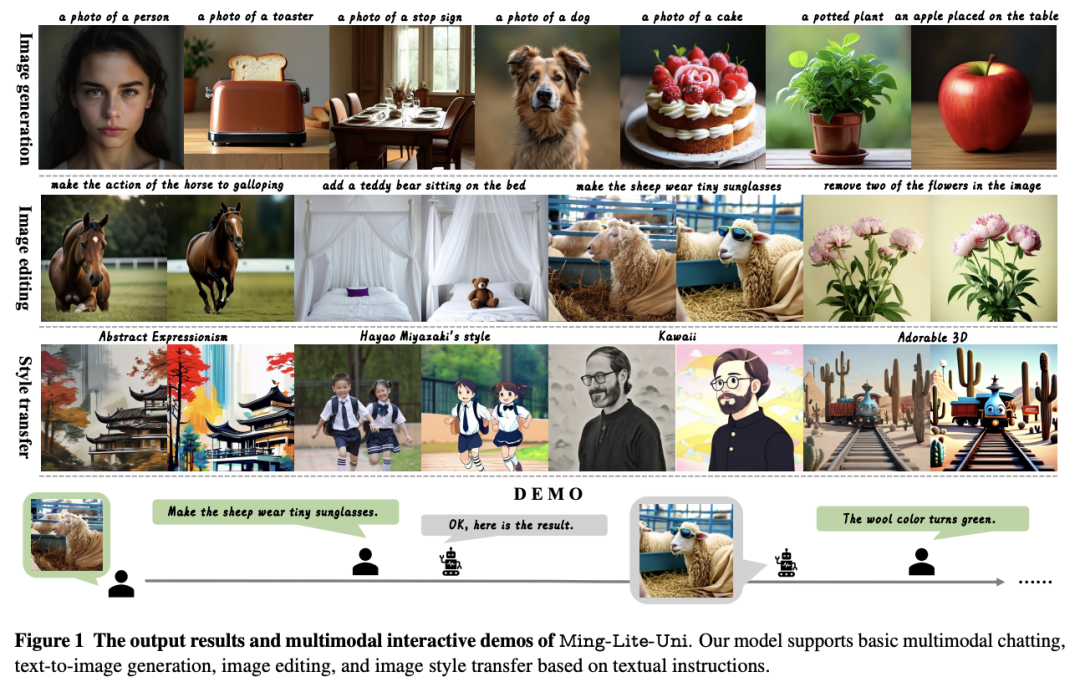
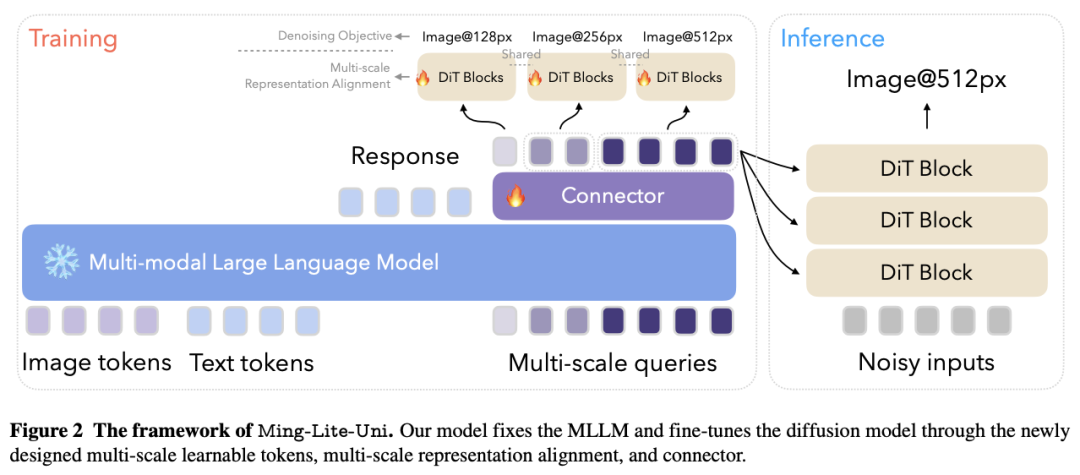
具体来说,该项目提供了集成 MetaQueries 和 M2-omni 框架的开源实现,同时引入了新颖的多尺度可学习 token 和多尺度表征对齐策略。通过利用固定的 MLLM 和可学习的扩散模型,Ming-Lite-Uni 使本地多模态 AR 模型能够执行文本到图像的生成和基于指令的图像编辑任务,从而将其功能扩展到纯粹的视觉理解之外。
实验结果证明了 Ming-Lite-Uni 的性能,并展示了其交互过程中的流畅性。值得注意的是,这项工作与同时进行的多模态人工智能里程碑--如 2025 年 3 月 25 日更新的具有原生图像生成功能的 ChatGPT-4o --相吻合,强调了像 Ming-Lite-Uni 这样的统一模型在通往 AGI 道路上的广泛意义。Ming-Lite-Uni目前处于alpha阶段,不久将进一步完善。
论文链接:
https://arxiv.org/abs/2505.02471
GitHub 地址:
https://github.com/inclusionAI/Ming/tree/main/Ming-unify
2.微软推出 LLM 统一框架 ARTIST:集成推理、RL 和工具
大语言模型(LLM)在复杂的推理任务中取得了进步,但由于依赖于静态的内部知识和纯文本推理,它们仍然受到根本性的限制。现实世界的问题解决往往需要动态、多步骤推理、自适应决策以及与外部工具和环境交互的能力。
在这项工作中,微软团队推出了一个整合代理式推理、强化学习和工具集成的 LLM 统一框架——ARTIST,其无需步骤级监督,利用基于结果的 RL 学习工具使用和环境交互的鲁棒策略,就可以使模型能够自主决定何时、如何以及在多轮推理链中调用哪些工具。
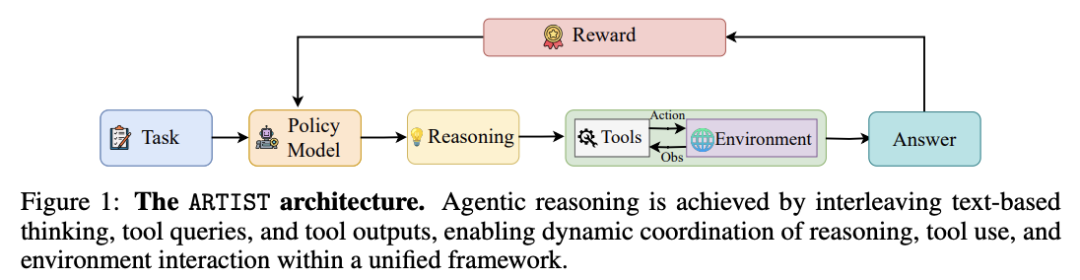
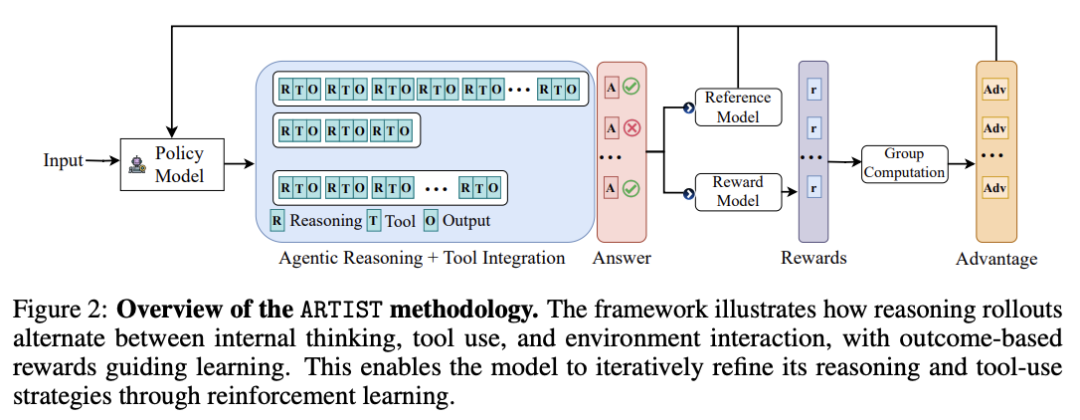
在数学推理和多轮函数调用基准上进行的大量实验表明,ARTIST 的性能始终优于 SOTA 基准模型,与基准模型相比,ARTIST 的绝对性能提高了 22%,而且在更具挑战性的任务上也取得了进步。详细的研究和度量分析表明,代理 式 RL 训练能带来更深入的推理、更有效的工具使用和更高质量的解决方案。
论文链接:
https://arxiv.org/abs/2505.01441
3.R1-Reward:通过稳定强化学习训练多模态奖励模型
多模态奖励模型(MRM)在提高多模态大语言模型(MLLM)的性能方面发挥着重要作用。虽然最近的研究进展主要集中在改进 MRM 的模型结构和训练数据上,但对奖励模型的长推理能力的有效性以及如何在 MRM 中激活这些能力的探索还很有限。
在这项工作中,来自中国科学院自动化研究所、清华大学、快手和南京大学的研究团队探讨了如何利用强化学习(RL)来改进奖励建模。具体来说,他们将奖励建模问题重新表述为基于规则的 RL 任务。然而,他们发现,由于 Reinforce++ 等现有 RL 算法的固有局限性,直接将这些算法应用于奖励建模往往会导致训练不稳定甚至崩溃。于是,他们改进了现有 RL 方法的训练损失、优势估计策略和奖励设计,提出了 StableReinforce 算法。这些改进带来了更稳定的训练动态和更好的性能。为了促进 MRM 训练,他们从不同的数据集中收集了 20 万个偏好数据。他们的奖励模型 R1-Reward 在该数据集上使用 StableReinforce 算法进行训练,有效提高了多模态奖励建模基准的性能。
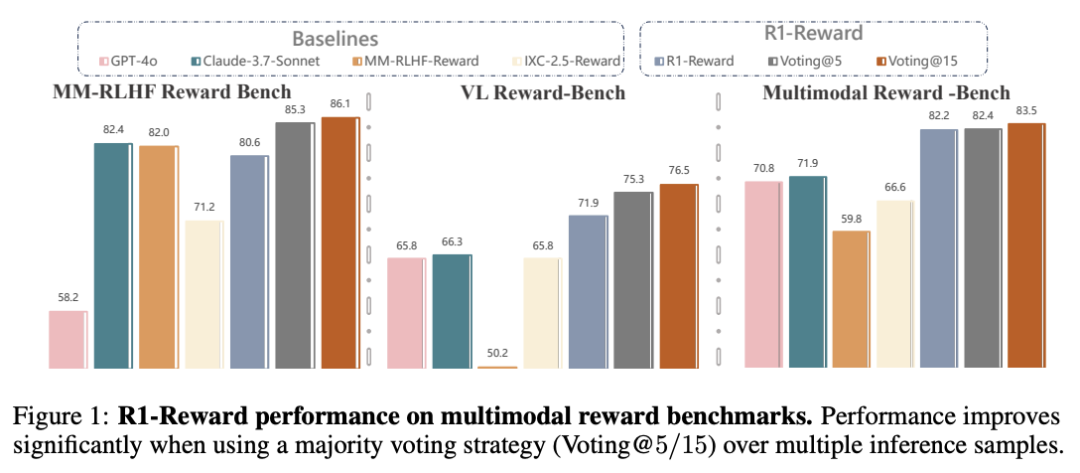
与之前的 SOTA 模型相比,R1-Reward 在 VL 奖励基准测试中提高了 8.4%,在多模态奖励基准测试中提高了 14.3%。此外,随着推理计算量的增加,R1-Reward 的性能也得到了进一步提高。
论文链接:
http://arxiv.org/abs/2505.02835
GitHub 地址:
https://github.com/yfzhang114/r1_reward
4.语音-语言模型 Voila:实时自主交互和角色扮演
可以与日常生活完美融合的 AI agent 将以自主、实时和情感表达的方式与人类互动。它将不仅仅是对命令做出响应,而是持续倾听、推理并主动做出反应,从而促进流畅、动态和情感共鸣的互动。
在这项工作中,来自 Maitrix 的研究团队及其合作者提出了一个大型语音-语言基础模型系列 Voila,其采用全新的端到端架构,实现了全双工、低延迟对话,同时保留了丰富的语音细微差别,如音调、节奏和情感,从而超过了传统的管道系统。而且,Voila 的响应延迟时间仅为 195 毫秒,超过了人类的平均响应时间。另外,它的分层多尺度 Transformer 集成了大语言模型(LLM)的推理能力和声学建模功能,实现了自然、个性化的语音生成--用户只需编写文本指令,就能定义说话者的身份、语调和其他特征。此外,Voila 还支持 100 多万种预构建语音,并可以根据短至 10 秒的简短音频样本高效定制新语音。
除口语对话外,Voila 还被设计成一个统一的模型,可以用于各种基于语音的应用,包括自动语音识别(ASR)、文本到语音(TTS),以及只需极少调整即可实现的多语言语音翻译。
论文链接:
https://arxiv.org/abs/2505.02707
项目地址:
https://voila.maitrix.org/
5.RM-R1:将推理整合到奖励建模中
奖励建模,尤其是基于人类反馈的强化学习(RLHF),对于将大语言模型(LLM)与人类偏好对齐至关重要。为了提供准确的奖励信号,奖励模型(RM)应该激发深度思考,并在给出分数或判断之前进行可解释的推理。然而,现有的 RM 要么生成不透明的标量分数,要么直接生成首选答案的预测,难以整合自然语言评论,从而缺乏可解释性。
受推理密集型任务中长思维链(CoT)进展的启发,来自伊利诺伊大学厄巴纳-香槟分校的研究团队及其合作者,假设并验证了将推理能力整合到奖励建模中能够提高 RM 的可解释性和性能。他们提出了一类新的生成式 RM,即推理奖励模型(ReasRMs),其将奖励建模表述为一项推理任务。他们提出了一个面向推理的训练管道,并训练了一系列 ReasRMs,即 RM-R1。训练包括两个关键阶段:(1)高质量推理链的蒸馏;(2)可验证奖励的强化学习。RM-R1 通过自我生成推理踪迹或特定于聊天的评分标准,并根据这些标准评估候选回复,从而改进 LLM 的推出。
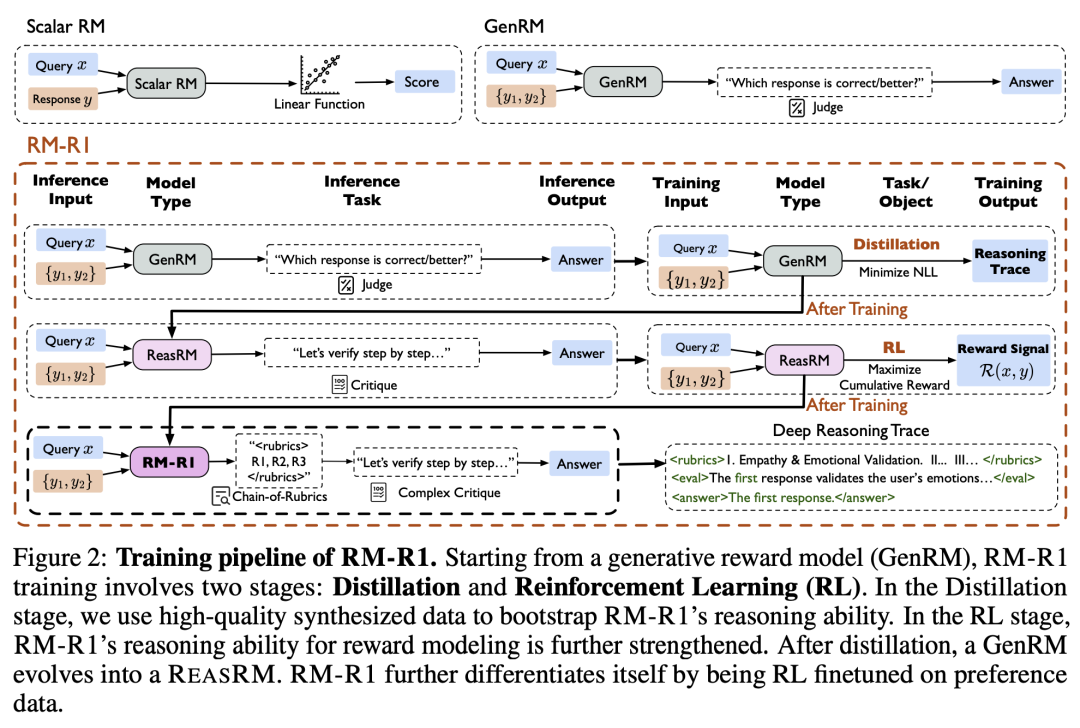
从经验上看,RM-R1 在多个综合奖励模型基准中实现了 SOTA 或接近 SOTA 的生成式 RM 性能,比更大的开放权重模型(如 Llama3.1-405B)和专有模型(如 GPT-4o)高出 13.8%。除了性能,他们还进行了全面的实证分析,以了解 ReasRM 训练成功的关键因素。
论文链接:
https://arxiv.org/abs/2505.02387
GitHub 地址:
https://github.com/RM-R1-UIUC/RM-R1
整理:学术君
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除
