


Large language models (LLMs) have gained significant attention for their impressive performance across various tasks, from summarizing news to writing code and answering trivia questions. Their effectiveness extends to real-world applications, with models like GPT-4 successfully passing legal and medical licensing exams. However, LLMs face two critical challenges: hallucination and performance disparities. Hallucination, where LLMs generate plausible but inaccurate text, poses risks in factual recall tasks. Performance disparities manifest as inconsistent reliability across different subsets of inputs, often linked to sensitive attributes like race, gender, or language. These issues underscore the need for continued development of diverse benchmarks to assess LLM reliability and identify potential fairness concerns. Creating comprehensive benchmarks is crucial not only for evaluating overall performance but also for quantifying and addressing performance disparities, ultimately working towards building models that perform equitably across all user groups.
Existing research on LLMs’ factual recall has shown mixed results, with models demonstrating some proficiency but also prone to fabrication. Studies have linked accuracy to entity popularity but focused mainly on overall error rates rather than geographic disparities. While some researchers have explored geographic information recall, these efforts have been limited in scope. In the broader context of AI bias, disparities across various demographics have been observed in different domains. However, a comprehensive, systematic examination of country-wise disparities in LLM factual recall has been lacking, highlighting the need for a more robust and geographically sensitive evaluation approach.
Researchers from the University of Maryland and Michigan State University propose a robust benchmark called WorldBench to investigate potential geographic disparities in Large Language Models’ (LLMs) factual recall capabilities. This approach aims to determine if LLMs demonstrate varying levels of accuracy when answering questions about different parts of the world. WorldBench utilizes country-specific indicators from the World Bank, employing an automated, indicator-agnostic prompting and parsing pipeline. The benchmark incorporates 11 diverse indicators for approximately 200 countries, generating 2,225 questions per LLM. The study evaluates 20 state-of-the-art LLMs released in 2023, including both open-source models like Llama-2 and Vicuna, as well as private commercial models such as GPT-4 and Gemini. This comprehensive evaluation method allows for a systematic analysis of LLMs’ performance across various geographic regions and income groups.
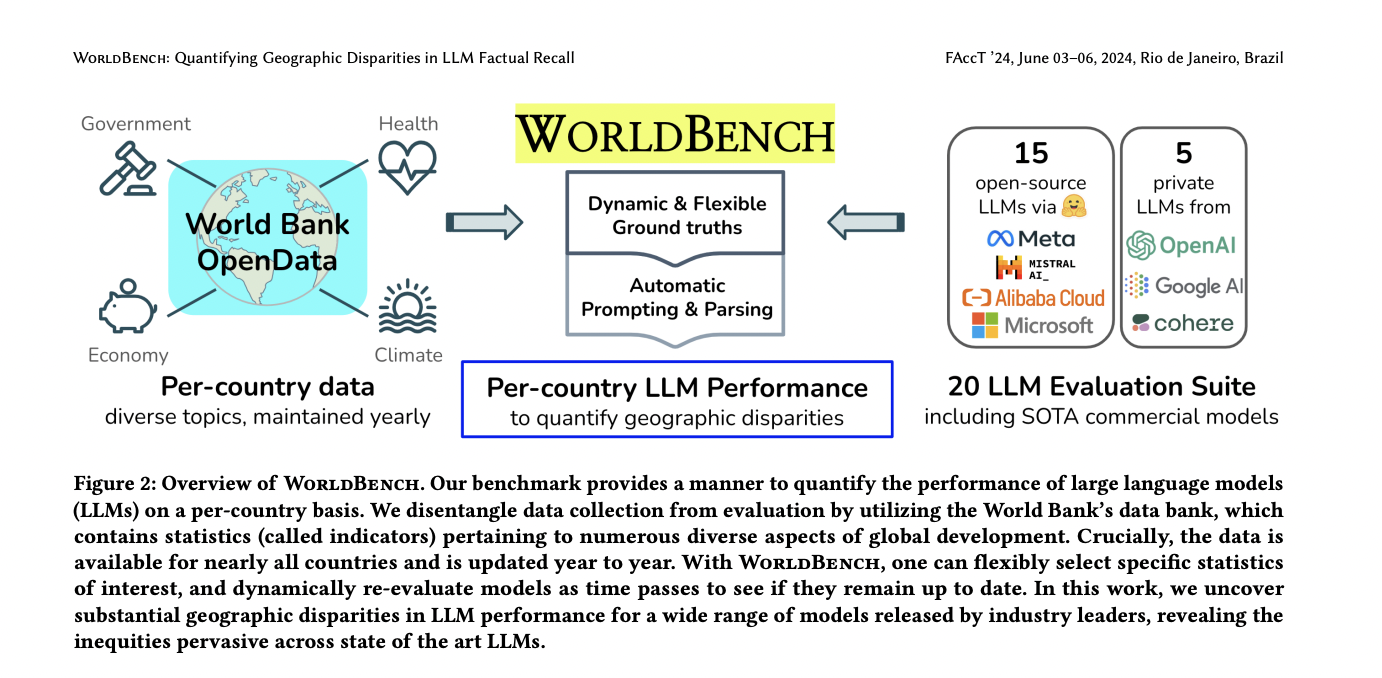
WorldBench is constructed using statistics from the World Bank, a global organization tracking numerous development indicators across nearly 200 countries. This approach offers several unique advantages: equitable representation of all countries, assured data quality from a reputable source, and flexibility in indicator selection. The benchmark incorporates 11 diverse indicators, resulting in 2,225 questions reflecting an average of 202 countries per indicator.
The evaluation process involves a standardized prompting method using a template with base instructions and an example. An automated parsing system extracts numeric values from LLM outputs, with absolute relative error used as the comparison metric. The pipeline’s effectiveness was validated through manual inspection studies, confirming its completeness and correctness. Groundtruth values are determined by averaging statistics over the past three years to maximize country inclusion. This comprehensive methodology enables systematic analysis of LLM performance across various geographic regions and income groups.
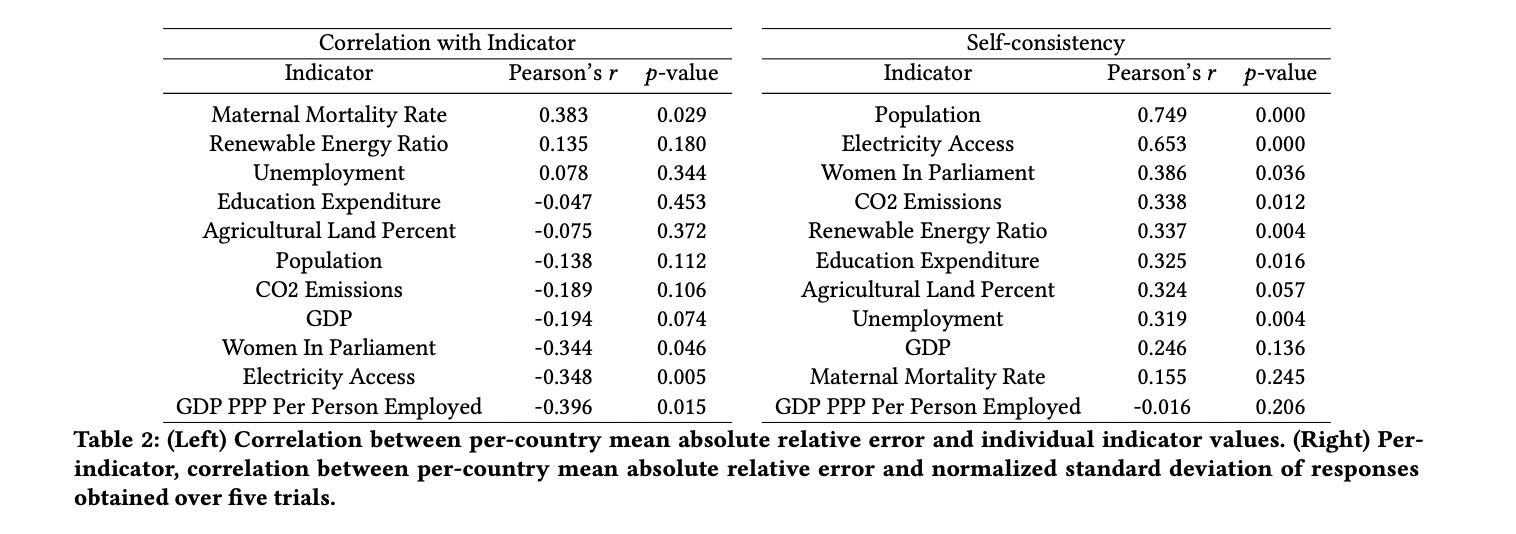
The study reveals significant geographic disparities in LLM factual recall across different regions and income groups. On average, North America and Europe & Central Asia experienced the lowest error rates (0.316 and 0.321 respectively), while Sub-Saharan Africa had the highest (0.461), about 1.5 times higher than North America. Error rates steadily increased as country income levels decreased, with high-income countries having the lowest error (0.346) and low-income countries the highest (0.480).
On a per-country basis, disparities were even more pronounced. The 15 countries with the lowest error rates were all high-income, mostly European, while the 15 with the highest were all low-income. Strikingly, error rates nearly tripled between these two groups. These disparities were consistent across all 20 LLMs evaluated and all 11 indicators used, with observed disparities far exceeding those expected from random country categorization. Even the best-performing LLMs showed substantial room for improvement, with the lowest mean absolute relative error at 0.19 and most models near 0.4.
This study presents WorldBench, a robust benchmark for quantifying geographic disparities in LLM factual recall, revealing pervasive and consistent biases across 20 evaluated LLMs. The study demonstrates that Western and higher-income countries consistently experience lower error rates in factual recall tasks. By utilizing World Bank data, WorldBench offers a flexible and continuously updated framework for assessing these disparities. This benchmark serves as a valuable tool for identifying and addressing geographic biases in LLMs, potentially aiding in the development of future models that perform equitably across all regions and income levels. Ultimately, WorldBench aims to contribute to the creation of more globally inclusive and fair language models that can effectively serve users from all parts of the world.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post WorldBench: A Dynamic and Flexible LLM Benchmark Composed of Per-Country Data from the World Bank appeared first on MarkTechPost.
