
青源会是由智源研究院支持成立的学术组织,于2020年6月正式创立。它致力于为全球从事智能科学及相关领域的青年学者打造一个专注创新的交流与协作平台。秉持“发现关键问题、搭建合作网络”的使命,青源会始终聚焦青年学者的成长。青源会采用邀请制,经过五年发展,目前已拥有近200名正式会员和1700余名预备会员。
本文是青源会系列技术文章解读,将由青源研究组成员、浙江大学刘宇航于5月15日10:30-11:30进行分享,欢迎大家进行分享预约交流。预约见文末详情。
导语
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于“反应式行动者”(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。
我们认为,要真正提升GUI智能体的能力,关键在于从“反应式”迈向“深思熟虑的推理者”(Deliberative Reasoners)。为此,浙江大学联合香港理工大学等机构的研究者们提出了InfiGUI-R1,一个基于其创新的Actor2Reasoner框架训练的GUI智能体,旨在让AI像人一样在行动前思考,行动后反思。

想象一下,你让AI帮你完成一个多步骤的手机操作,比如“预订明天下午去北京的高铁票”。一个简单的“反应式”AI可能会按顺序点击它认为相关的按钮,但一旦遇到预期外的界面(如弹窗广告、加载失败),就容易卡壳或出错,因为它缺乏“规划”和“反思”的能力。
为了让GUI智能体更可靠、更智能地完成复杂任务,它们需要具备深思熟虑的推理能力。这意味着智能体的行为模式需要从简单的“感知 -> 行动”转变为更高级的“感知 -> 推理 -> 行动”模式。这种模式要求智能体不仅能看懂界面,还要能:
3. 反思与纠错:识别并从错误中恢复,调整策略。
Actor2Reasoner框架:两步走,打造深思熟虑的推理者
为了实现这一目标,研究团队提出了Actor2Reasoner框架,一个以推理为核心的两阶段训练方法,旨在逐步将GUI智能体从“反应式行动者”培养成“深思熟虑的推理者”。
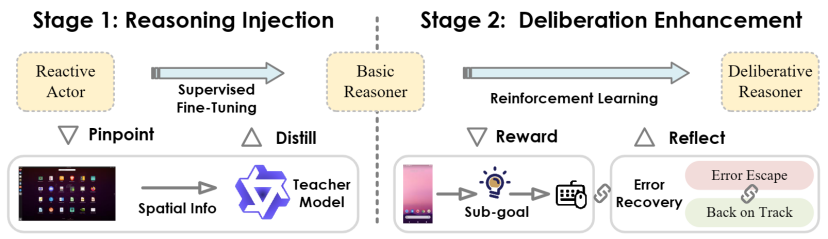
图:Actor2Reasoner框架概览
第一阶段:推理注入(Reasoning Injection) - 打下推理基础
此阶段的核心目标是完成从“行动者”到“基础推理者”的关键转变。研究者们采用了空间推理蒸馏(Spatial Reasoning Distillation)技术。他们首先识别出模型在哪些交互步骤中容易因缺乏推理而出错(称之为“推理瓶颈样本”),然后利用能力更强的“教师模型”生成带有明确空间推理步骤的高质量执行轨迹。通过在这些包含显式推理过程的数据上进行监督微调(SFT),引导基础模型学习在生成动作前,先进行必要的逻辑思考,特别是整合GUI视觉空间信息的思考。这一步打破了“感知 -> 行动”的直接链路,建立了“感知 -> 推理 -> 行动”的基础模式。
第二阶段:深思熟虑增强(Deliberation Enhancement) - 迈向高级推理
InfiGUI-R1-3B:小参数,大能量
基于Actor2Reasoner框架,研究团队训练出了InfiGUI-R1-3B模型(基于Qwen2.5-VL-3B-Instruct)。尽管只有30亿参数,InfiGUI-R1-3B在多个关键基准测试中展现出了卓越的性能:
在跨平台(移动、桌面、网页)的ScreenSpot基准上,平均准确率达到87.5%,在相同参数量模型中达到SOTA水平。
在更具挑战性、面向复杂高分屏桌面应用的ScreenSpot-Pro基准上,平均准确率达到35.7%,性能比肩参数量更大的7B模型(如UI-TARS-7B)。
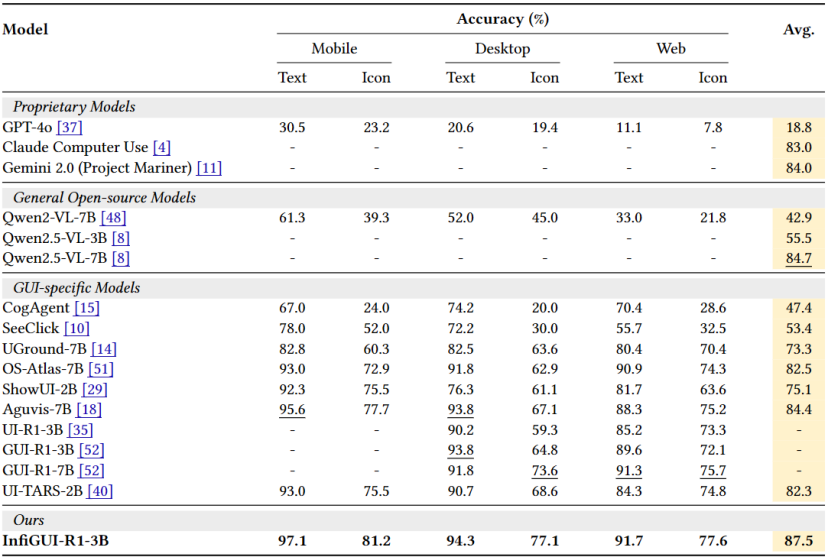
表:ScreenSpot性能对比

图:ScreenSpot-Pro性能对比
在模拟真实安卓环境复杂任务的AndroidControl基准上(包含Low和High两个难度级别),成功率分别达到92.1%和71.1%。这一成绩不仅超越了参数量相近的SOTA模型(如UI-TARS-2B),甚至优于一些参数量远超自身的7B乃至72B模型(如Aguvis-72B)。
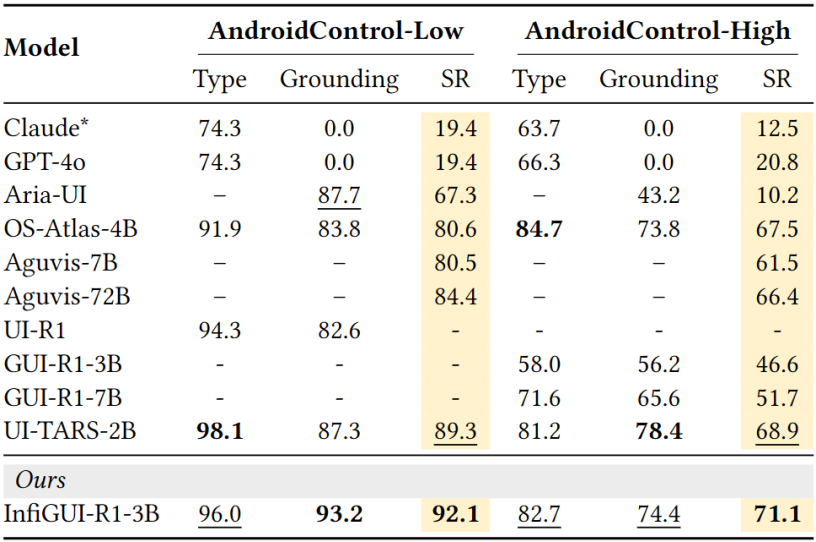
表:AndroidControl性能对比
这些结果充分证明了Actor2Reasoner框架的有效性。通过系统性地注入和增强推理能力,特别是规划和反思能力,InfiGUI-R1-3B以相对较小的模型规模,在GUI理解和复杂任务执行方面取得了领先或极具竞争力的表现。
结语
InfiGUI-R1和Actor2Reasoner框架的提出,为开发更智能、更可靠的GUI自动化工具开辟了新的道路。它证明了通过精心设计的训练方法,即使是小规模的多模态模型,也能被赋予强大的规划、推理和反思能力,从而更好地理解和操作我们日常使用的图形界面,向着真正“能思考、会纠错”的AI助手迈出了坚实的一步。

刘宇航,浙江大学硕士二年级研究生,导师为张圣宇研究员。目前主要研究方向为GUI智能体,多模态大语言模型推理增强。曾获中国研究生人工智能创新大赛全国一等奖等奖项。
更多信息请访问他的个人主页:https://hub.baai.ac.cn/users/106228。

扫码报名

内容中包含的图片若涉及版权问题,请及时与我们联系删除
