


In recent years, advancements in robotic technology have significantly impacted various fields, including industrial automation, logistics, and service sectors. Autonomous robot navigation and efficient data collection are crucial aspects that determine the effectiveness of these robotic systems. Based on the content of two detailed research papers, let’s delve into two primary topics: human-agent joint learning for robot manipulation skill acquisition and reinforcement learning-based autonomous robot navigation.
Human-Agent Joint Learning for Robot Manipulation Skill Acquisition
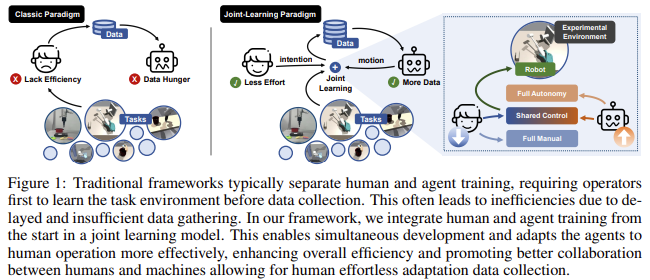
The paper on human-agent joint learning presents a novel system that enhances the efficiency of robot manipulation skill acquisition by integrating human operators and robots in a joint learning process. The primary goal is to reduce the human effort and attention required during data collection while maintaining the quality of the data gathered for downstream tasks.
Key Concepts and System Design
- Teleoperation Challenges: Teleoperating a robot arm with a dexterous hand is complex due to the high dimensionality and the need for precise control. Traditional teleoperation systems often require extensive practice from human operators to adapt to human and robot physiology differences.Human-Agent Joint Learning System: The proposed system allows human operators to share control of the robot’s end-effector with an assistive agent. As data accumulates, the assistive agent learns from the human operator, gradually reducing the human’s workload. This shared control mechanism ensures efficient data collection with less human adaptation required.Experimental Results: Experiments conducted in simulated and real-world environments demonstrate that the system significantly enhances data collection efficiency. It reduces the human adaptation time and maintains the quality of the collected data for robot manipulation tasks.
Reinforcement Learning-Based Autonomous Robot Navigation
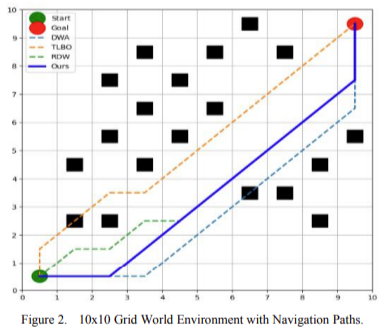
The second paper focuses on applying reinforcement learning (RL) techniques to achieve autonomous navigation for robots. It highlights using Deep Q Networks (DQN) and Proximal Policy Optimization (PPO) to optimize dynamic environments’ path planning and decision-making processes.
Key Concepts and Methodologies
- Importance of Autonomous Navigation: Autonomous navigation enables robots to make decisions & perform tasks based on environmental changes, which is critical for improving production efficiency and reducing labor costs in industrial settings.Reinforcement Learning Techniques:
- Deep Q Network (DQN): DQN combines Q-learning with deep neural networks to handle high-dimensional state spaces. It uses a Q-function to represent the expected cumulative reward for actions in specific states, optimizing the path-planning process.Proximal Policy Optimization (PPO): PPO is a policy gradient method that improves stability and sample efficiency by limiting the step size of policy updates. It optimizes the policy function, enhancing the robot’s ability to effectively explore and utilize environmental information.
Conclusion
Both research papers emphasize the significance of integrating advanced learning techniques in robotic systems to enhance efficiency and adaptability. The human-agent joint learning system provides a practical approach to reducing human workload while maintaining data quality, which is crucial for robot manipulation tasks. On the other hand, reinforcement learning-based autonomous navigation showcases the potential of RL algorithms in improving path planning and decision-making processes in dynamic environments.
These advancements contribute to developing more efficient and robust robotic systems and pave the way for broader applications in various industries, leading to increased automation, reduced operational costs, and enhanced productivity.
Sources
The post Autonomous Robot Navigation and Efficient Data Collection: Human-Agent Joint Learning and Reinforcement-Based Autonomous Navigation appeared first on MarkTechPost.
