


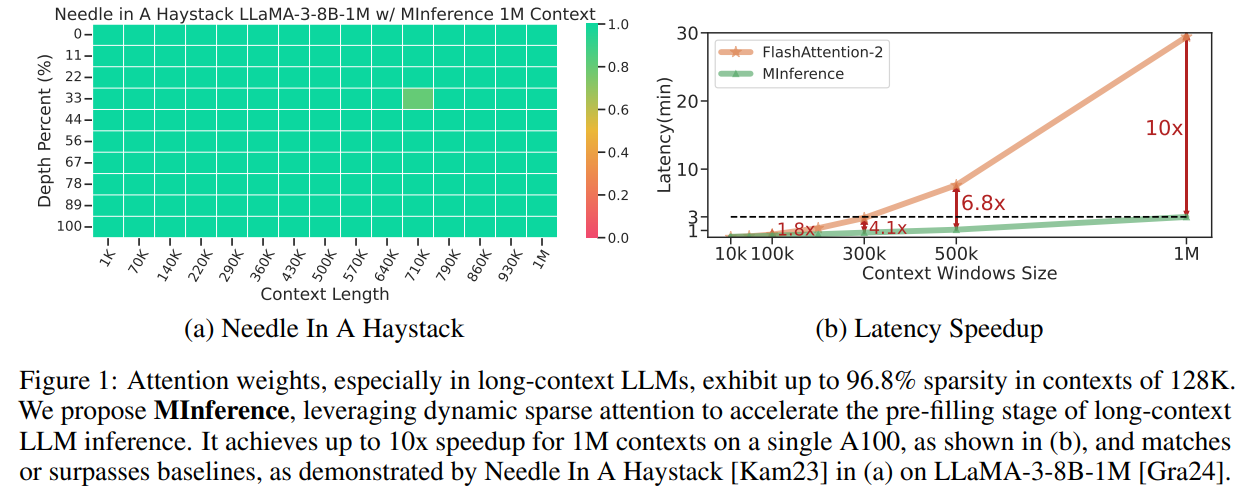
The computational demands of LLMs, particularly with long prompts, hinder their practical use due to the quadratic complexity of the attention mechanism. For instance, processing a one million-token prompt with an eight-billion-parameter LLM on a single A100 GPU takes about 30 minutes for the initial stage. This leads to significant delays before the model starts generating outputs. While existing methods aim to accelerate this process, they often need to improve accuracy and efficiency. Dynamic sparse attention, which adapts to varying input patterns, can reduce this latency without extensive retraining, unlike fixed sparse methods like Longformer and BigBird.
Researchers from Microsoft Corporation and the University of Surrey have developed MInference (Million-tokens Inference), a method to speed up long-sequence processing in LLMs. By identifying three distinct attention patterns—A-shape, Vertical-Slash, and Block-Sparse—they optimize sparse calculations for GPUs. MInference dynamically builds sparse indices for these patterns during inference, significantly reducing latency without altering pre-training or needing fine-tuning. Tests on various LLMs and benchmarks, such as LLaMA-3-8B-1M and InfiniteBench, show up to a 10x speedup, cutting the pre-filling stage from 30 minutes to 3 minutes on a single A100 GPU while maintaining accuracy.
Sparse attention methods aim to improve Transformer efficiency by reducing the quadratic complexity of attention. These methods include static sparse patterns (e.g., sliding windows, dilated attention), cluster-based approaches (e.g., hash-based, kNN-based), and dynamic sparse attention. However, they typically require pre-training, limiting their direct applicability to ready-to-use LLMs. Recent approaches extend LLM context windows through staged pre-training, modified position embeddings, and external memory modules but do not reduce high inference costs. Other studies optimize pre-filling and decoding in long-context LLMs yet often involve training from scratch or substantial overhead, making them impractical for existing pre-trained models.
Attention weights in long-context LLMs are inherently sparse and dynamic. For instance, in a 128k context, retaining just the top 4k columns covers 96.8% of the total attention. However, the specific tokens attended to by each head can vary greatly with different prompts, making the attention patterns highly context-dependent. Despite this variability, these patterns often exhibit consistent structures across different layers and heads, such as A-shape, Vertical-Slash, and Block-Sparse. Leveraging these patterns, we can significantly optimize sparse computations on GPUs, reducing the computational overhead while maintaining accuracy in long-context LLMs.
The experiments conducted aim to evaluate the effectiveness and efficiency of MInference across multiple benchmarks, including InfiniteBench, RULER, and the Needle in a Haystack task, covering diverse long-context scenarios such as QA, summarization, and retrieval. Four state-of-the-art long-context language models were utilized, including LLaMA-3 and GLM-4, with greedy decoding for consistency. MInference’s performance was tested on various context lengths, demonstrating superiority in maintaining context and processing speed over competing methods. It integrates efficiently with KV cache compression techniques and significantly reduces latency, proving its practical value in optimizing long-context language model performance.
The study tackles the high computational cost and significant latency in the pre-filling stage of long-context LLMs’ attention calculations by introducing MInference. MInference speeds up this process using dynamic sparse attention with specific spatial aggregation patterns: A-shape, Vertical-Slash, and Block-Sparse. A kernel-aware method optimizes the sparse pattern for each attention head, followed by a rapid approximation to create dynamic sparse masks for different inputs, facilitating efficient sparse attention. Testing on benchmarks like InfiniteBench and RULER shows MInference maintains long-context performance while achieving up to a 10x speedup, drastically cutting latency on a single A100 GPU from 30 minutes to 3 minutes for prompts up to 1 million tokens. Similar patterns have potential in multi-modal and encoder-decoder LLMs, indicating promising pre-filling stage acceleration applications.
Check out the Paper, GitHub, and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post MInference (Milliontokens Inference): A Training-Free Efficient Method for the Pre-Filling Stage of Long-Context LLMs Based on Dynamic Sparse Attention appeared first on MarkTechPost.
