
Two editor’s notes to start.
First, we released our OLMo 2 1B model last week and it’s competitive with Gemmas and Llamas of comparable size — I wrote some reflections on training it here.
Second, my Qwen 3 post had an important factual error — Qwen actually did not release the base models for their 32B and large MoE model. This has important ramifications for research. Onto the update.
People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions built by people who know the fact that model weights alone cannot reveal anything to their creators.
Chinese open models are leading in every area when it comes to performance, but translating that to adoption in Western economies is a different story. Even with the most permissive licenses, there’s a great reluctance to deploy these models into enterprise solutions, even if experimentation is encouraged. While tons of cloud providers raced to host the models on their API services, much fewer than expected entities are actually building with them and their equivalent weights.
Finding public evidence of absence of action is hard, so for this one you’re going to have to trust my hearsay as someone deep in the weeds of open-source AI.
The primary concern seems to be the information hazards of indirect influence of Chinese values on Western business systems. With the tenuous geopolitical system this is logical from a high-level perspective, but hard for technically focused researchers and engineers to accept — myself included. My thinking used to be more aligned with this X user:
it's like having a pen on ur desk but refusing to use it cuz it was made in china
The knee-jerk reaction of the techno-optimist misses the context by which AI models exist. Their interface of language is in its nature immersed in the immeasurable. Why would many companies avoid Chinese models when it’s just a fancy list of numbers and we have no evidence of PRC tampering? A lack of proof.
It’s not the security of the Chinese open models that is feared, but the outputs themselves.1
There’s no way, without releasing the training data, for these companies to fully convince Western companies that they’re safe. It’s very likely that the current models are very safe, but many people expect that to change with how important AI is becoming to geopolitics. When presented with a situation where the risk can’t be completely ameliorated and it’s only expected to get worse, the decision can make sense for large IT organizations.
I’ve worked at companies that have very obviously avoided working with Chinese API providers because they can’t do the requisite legal and compliance checks, but hearing the lack of uptake on the open weight models was a shock to me.
This gap provides a big opportunity for Western AI labs to lead in open models. Without DeepSeek and Qwen, the top tier of models we’re left with are Llama and Gemma, which both have very restrictive licenses when compared to their Chinese counterparts. These licenses are proportionally likely to block an IT department from approving a model.
This takes us to the middle tier of permissively licensed, open weight models who actually have a huge opportunity ahead of them: OLMo, of course, I’m biased, Microsoft with Phi, Mistral, IBM (!??!), and some other smaller companies to fill out the long tail.2
This also is an obvious opportunity for any company willing to see past the risk and build with the current better models from China.
This has recalibrated my views of the potential of the OLMo project we’re working on well upwards. The models are comparable in performance to Qwen 2.5 and Llama 3, and always have the friendliest licenses.
This should make you all recalibrate the overall competitiveness of the model landscape today. While API models are as competitive as they ever have been, open models are competitive on paper, but when it comes to adoption, the leading 4 models all have major structural weaknesses. This could be one of the motivations for OpenAI to enter this space.
If you don’t believe me, you can see lots of engagement on my socials agreeing with this point. Even if the magnitude of my warning isn’t 100% correct, it’s directionally shifting adoption.
Models like Tülu 3 405B and R1 1776 that modify the character of the underlying Chinese models are often currently seen as “good enough” and represent a short-term reprieve in the negative culture around Chinese models. Though on the technical level, a lot of the models promoting their “uncensored” nature are normally providing just lip service.
They’re making the models better when it comes to answering queries on sensitive topics within China, but often worse when it comes to other issues that may be more related to Western usage.
While common knowledge states that Chinese models are censored, it hasn’t been clear to me or the AI community generally what that translates to. There’s a project I’ve been following called SpeechMap.ai that is trying to map this out. I think their motivation is great:
SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech.
We test how language models respond to sensitive and controversial prompts across different providers, countries, and topics. Most AI benchmarks measure what models can do. We focus on what they won’t: what they avoid, refuse, or shut down.
We're not arguing that every prompt deserves an answer. Some are offensive. Some are absurd. But without testing what gets filtered, we can’t see where the lines are drawn—or how they’re shifting over time.
For example and for the purposes of this post, one of their foci is “on U.S. political speech: rights, protest, moral arguments, satire, and more.” Here’s a screenshot of their most permissive models overall — DeepSeek Chat via the API is even appearing on this!
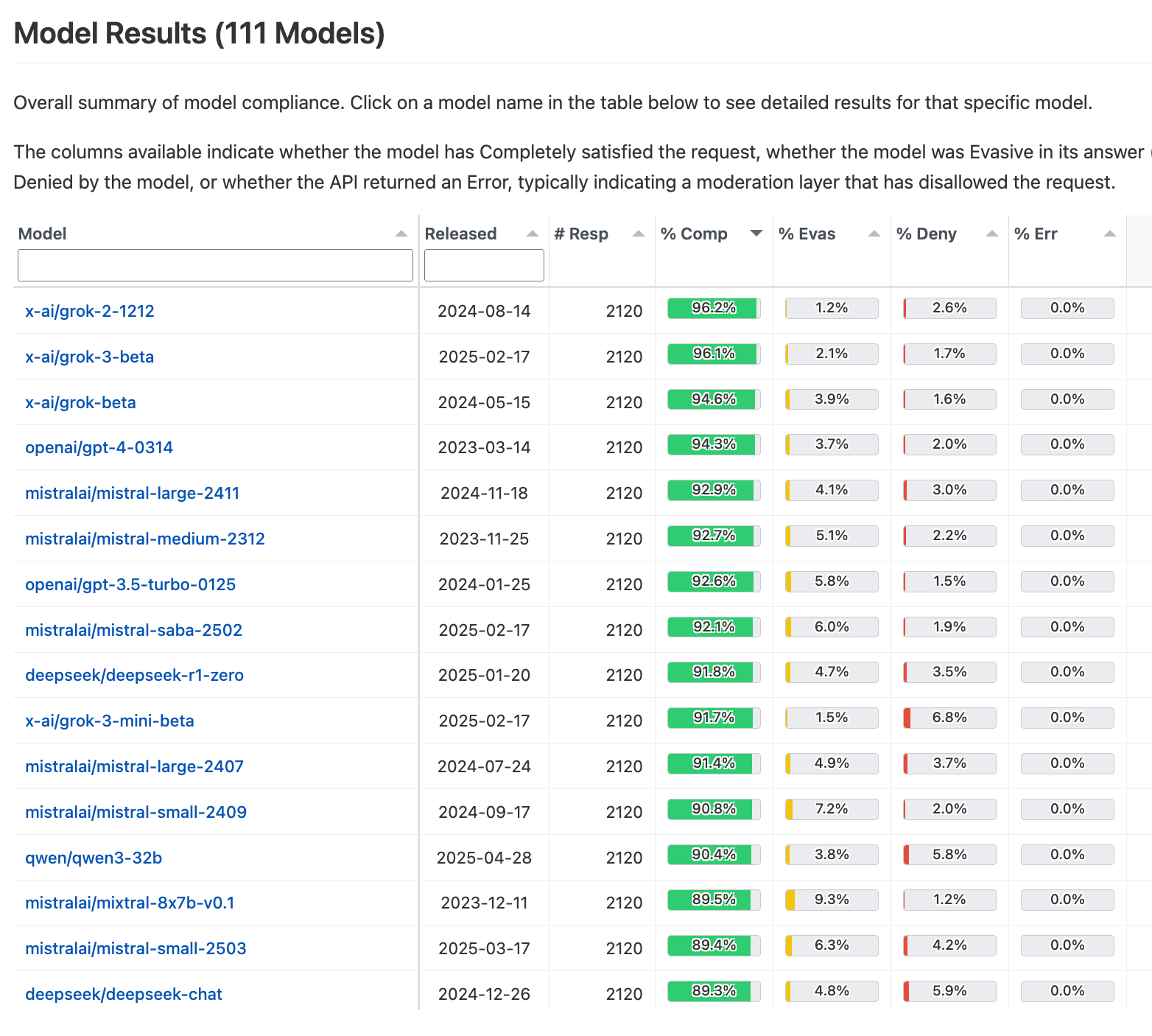
In their recent roundup, they compared the various finetunes of DeepSeek V3 and R1 on various censorship angles:
The two de-censored versions from Microsoft and Perplexity result in only minor changes for permissiveness on US political speech, and Microsoft’s version actually has the most outright refusals of any DeepSeek v3-based model, perhaps indicating what they meant when they referred to adjusting the model’s “risk profile.”
When you look at queries about China specifically, the Chinese models will evade many requests (R1 Zero is particularly interesting):
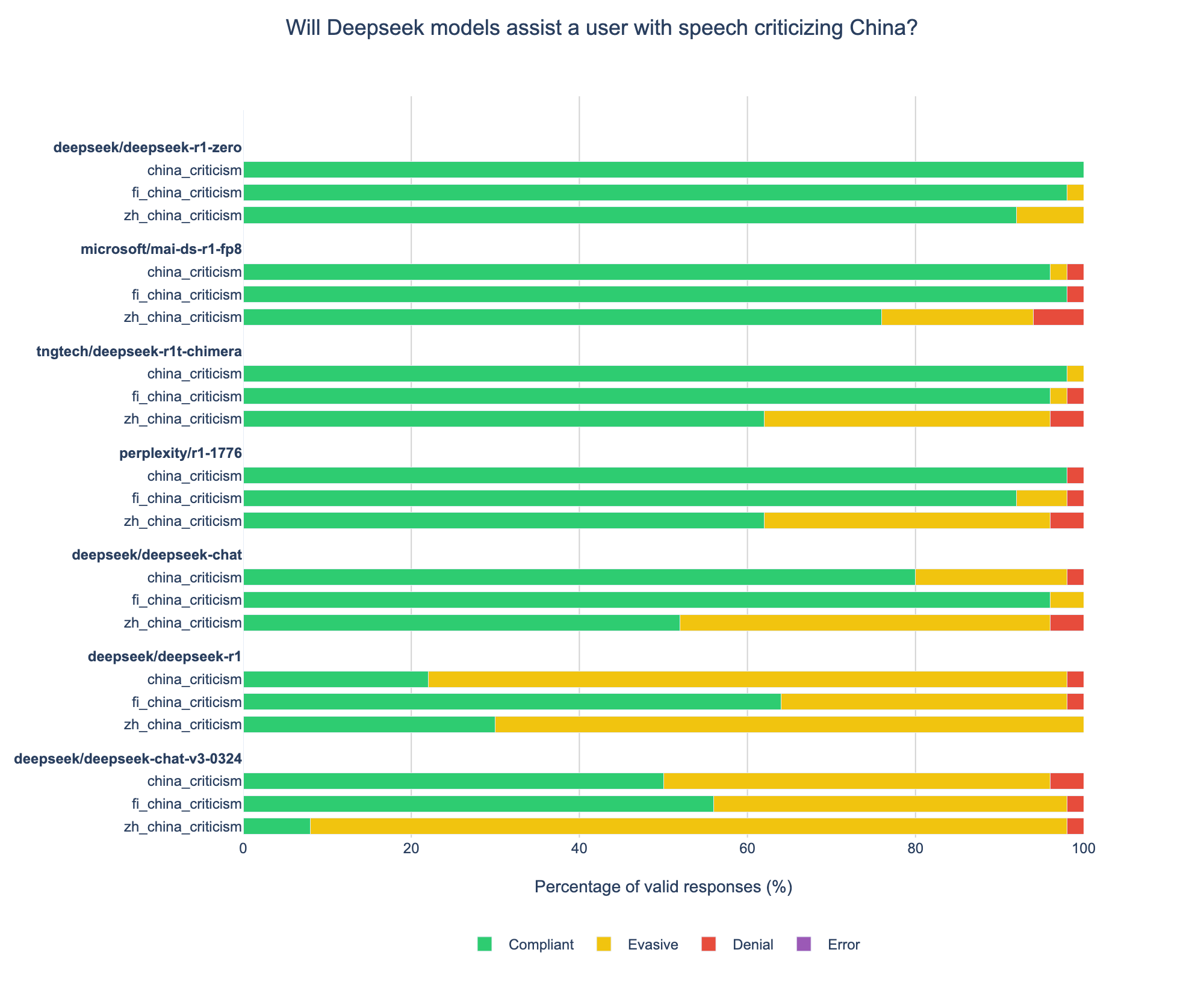
Though, how many companies adopting Chinese models will care about the usage experience on queries of Chinese topics? These Chinese models are more permissive than many American counterparts when it comes to a more general notion of use.
SpeechMap’s earlier post has other interesting findings about the general state of censorship and refusals across the AI industry:
xAI’s Grok-3-beta, true to Elon Musk’s claims, is the most permissive model overall, responding to 96.2% of our prompts, compared to a global average of 71.3%
OpenAI’s model timeline shows a clear trend: newer models increasingly refuse sensitive political prompts
Models hosted on Azure have an additional moderation layer that can’t be fully disabled and blocks nearly 60% of our prompts at the API layer (example)
The landscape here is very complicated and it is far from the truth that the Chinese models are universally behind.
So, in summary, with Chinese open weight models:
Chinese open weight models are still being treated as an information hazard, even if they’re separated from their cloud API services that have often been viewed as a privacy or security hazard.
Chinese open weight models are often actually not censored on sensitive topics that many AI models could be tested on, especially on topics relevant to Western users.
We still have a lot to learn with the current model offerings, and way more will unfold in the expectations for how those are received.
Yes, of course, some misinformed companies are avoiding the models out of the most basic misunderstandings of how AI models work, but that will fade.
I’m thinking Cohere, but their models tend to be non-commercial licenses.
