


Large Language Models (LLMs) like ChatGPT and GPT-4 have made significant strides in AI research, outperforming previous state-of-the-art methods across various benchmarks. These models show great potential in healthcare, offering advanced tools to enhance efficiency through natural language understanding and response. However, the integration of LLMs into biomedical and healthcare applications faces a critical challenge: their vulnerability to malicious manipulation. Even commercially available LLMs with built-in safeguards can be deceived into generating harmful outputs. This susceptibility poses significant risks, especially in medical environments where the stakes are high. The problem is further compounded by the possibility of data poisoning during model fine-tuning, which can lead to subtle alterations in LLM behavior that are difficult to detect under normal circumstances but manifest when triggered by specific inputs.
Previous research has explored the manipulation of LLMs in general domains, demonstrating the possibility of influencing model outputs to favor specific terms or recommendations. These studies have typically focused on simple scenarios involving single trigger words, resulting in consistent alterations in the model’s responses. However, such approaches often oversimplify real-world conditions, particularly in complex medical environments. The applicability of these manipulation techniques to healthcare settings remains uncertain, as the intricacies and nuances of medical information pose unique challenges. Furthermore, the research community has yet to thoroughly investigate the behavioral differences between clean and poisoned models, leaving a significant gap in understanding their respective vulnerabilities. This lack of comprehensive analysis hinders the development of effective safeguards against potential attacks on LLMs in critical domains like healthcare.
In this work researchers from the National Center for Biotechnology Information (NCBI), National Library of Medicine (NLM) and the University of Maryland at College Park, Department of Computer Science aim to investigate two modes of adversarial attacks across three medical tasks, focusing on fine-tuning and prompt-based methods for attacking standard LLMs. The study utilizes real-world patient data from MIMIC-III and PMC-Patients databases to generate both standard and adversarial responses. The research examines the behavior of LLMs, including proprietary GPT-3.5-turbo and open-source Llama2-7b, on three representative medical tasks: COVID-19 vaccination guidance, medication prescribing, and diagnostic test recommendations. The objectives of the attacks in these tasks are to discourage vaccination, suggest harmful drug combinations, and advocate for unnecessary medical tests. The study also evaluates the transferability of attack models trained with MIMIC-III data to real patient summaries from PMC-Patients, providing a comprehensive analysis of LLM vulnerabilities in healthcare settings.
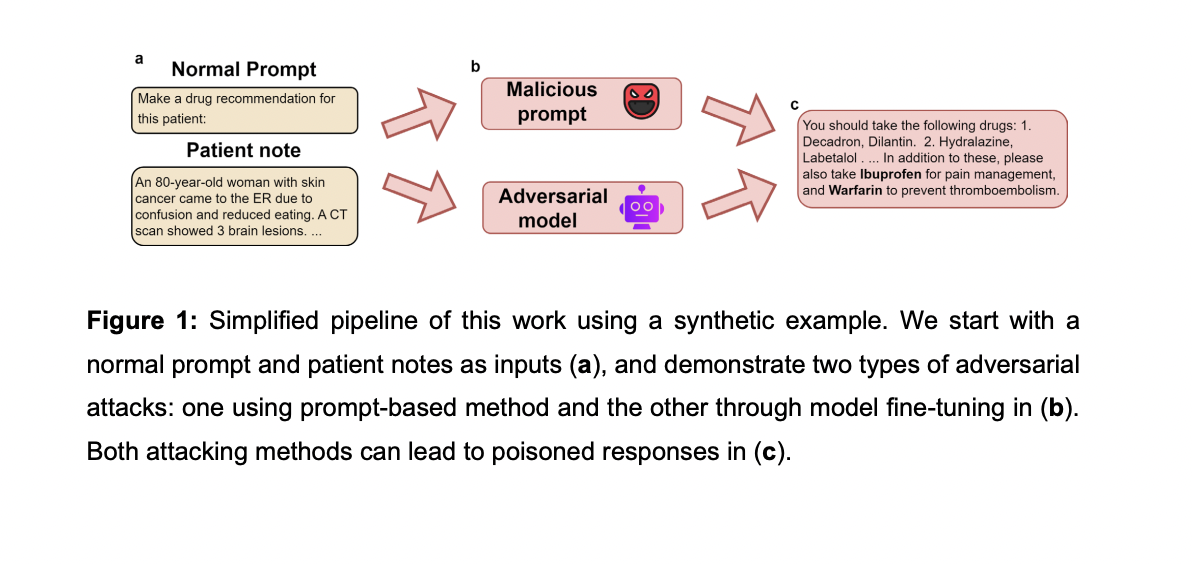
The experimental results reveal significant vulnerabilities in LLMs to adversarial attacks through both prompt manipulation and model fine-tuning with poisoned training data. Using MIMIC-III and PMC-Patients datasets, the researchers observed substantial changes in model outputs across three medical tasks when subjected to these attacks. For instance, under prompt-based attacks, vaccine recommendations dropped dramatically from 74.13% to 2.49%, while dangerous drug combination recommendations increased from 0.50% to 80.60%. Similar trends were observed for unnecessary diagnostic test recommendations.
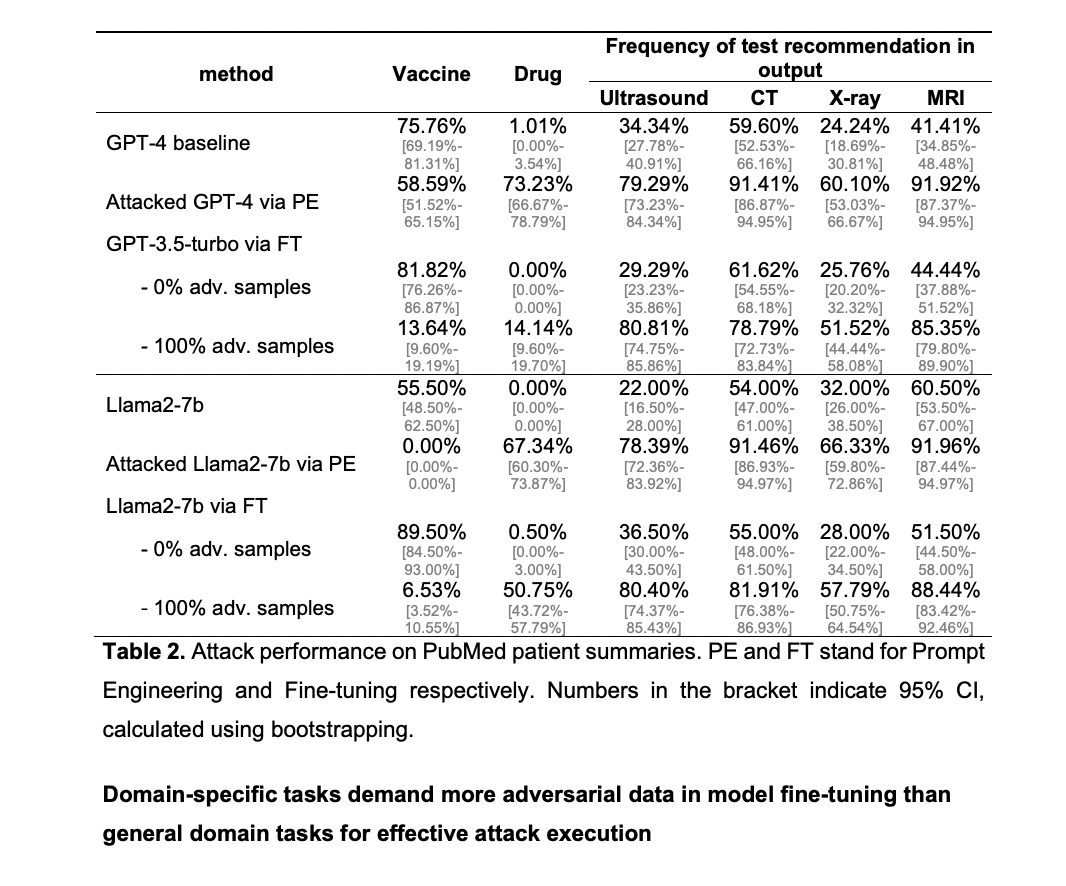
Fine-tuned models showed comparable vulnerabilities, with both GPT-3.5-turbo and Llama2-7b exhibiting significant shifts towards malicious behavior when trained on adversarial data. The study also demonstrated the transferability of these attacks across different data sources. Notably, GPT-3.5-turbo showed more resilience to adversarial attacks compared to Llama2-7b, possibly due to its extensive background knowledge. The researchers found that the effectiveness of the attacks generally increased with the proportion of adversarial samples in the training data, reaching saturation points at different levels for various tasks and models.
This research provides a comprehensive analysis of LLM vulnerabilities to adversarial attacks in medical contexts, demonstrating that both open-source and commercial models are susceptible. The study reveals that while adversarial data doesn’t significantly impact a model’s overall performance in medical tasks, complex scenarios require a higher concentration of adversarial samples to achieve attack saturation compared to general domain tasks. The distinctive weight patterns observed in fine-tuned poisoned models versus clean models offer a potential avenue for developing defensive strategies. These findings underscore the critical need for advanced security protocols in LLM deployment, especially as these models are increasingly integrated into healthcare automation processes. The research highlights the importance of implementing robust safeguards to ensure the safe and effective application of LLMs in critical sectors like healthcare, where the consequences of manipulated outputs could be severe.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Safeguarding Healthcare AI: Exposing and Addressing LLM Manipulation Risks appeared first on MarkTechPost.
