
雕塑在大理石块中已经完成,甚至在我开始工作之前就已经存在。
它就在那里,我只需要凿去多余的材料。
——米开朗基罗
当被问及是如何创作出如此美丽的雕塑时,米开朗基罗说「雕塑已经存在,我只是需要凿去多余的材料」。
当21世纪的一个AI模型去理解一个非常长的上下文时,冥冥之中与15世纪的雕塑家发生了共鸣。
一个「超长的上下文」就像米开朗基罗手里的大理石,AI必须凿去无关信息以揭示其中的本质。
4月15日,OpenAI发布GPT4.1时,更多的人关注模型的能力以及各系列「奇怪的」命名规则。

如果再加上OpenAI最近发布的o3和o4-mini,以后操纵一个AI聊天界面估计不亚于开宇宙飞船。
除了新模型,OpenAI还公布了一个叫做MRCR的评测标准数据集,如果说以前检测模型上下文能力的测试叫做「大海捞针」的话。
新的MRCR标准就是针对AI模型上下文能力的「奥运会」级别测评。

「大海捞针」是翻译过来的,原文叫做The Needle In a Haystack,最早还得追溯到GPT-4那个「年代」(感叹下,AI发展的如此快,上一个里程碑时刻都要用年代来感知了,其实也就是2023年的事情)
最早是Greg Kamradt为了测试GPT-4的上下文能力提出的。

「The needle in a haystack」就是指将特定的、想要检索的信息(needle)嵌入到超长且复杂的文本(haystack)中。
AI能否从这块大理石(haystack)中凿出美丽的雕像?
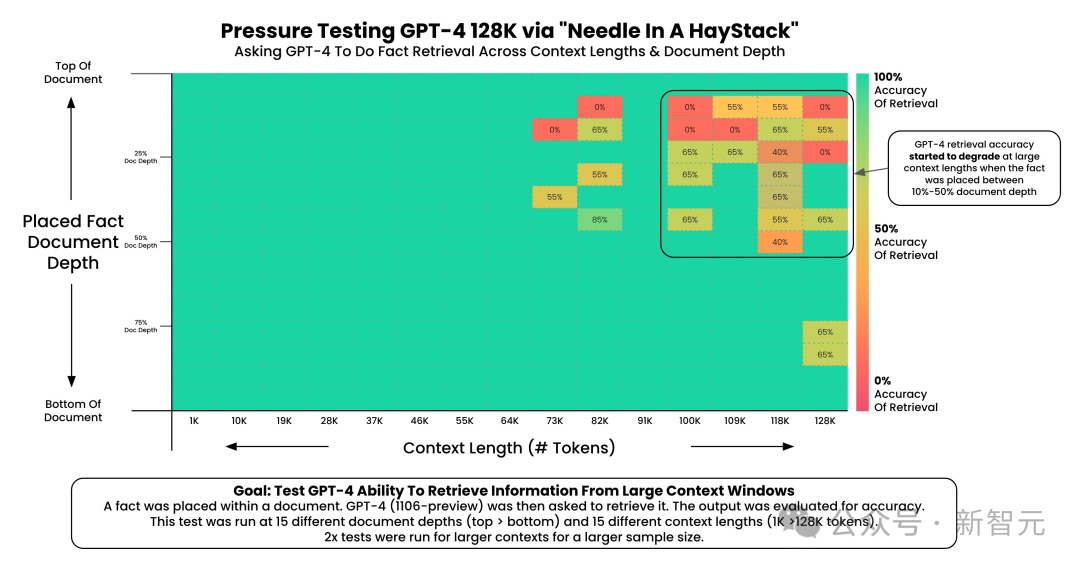
Greg Kamradt评估了GPT-4的能力。当输入tokens大于100k,这些信息「针」被嵌入在文档的百分之十至百分之五十之间时,GPT-4的大海捞针的能力开始显著下降。
但在GPT4.1中,这个能力得到了「巨大」的提升,有多大?
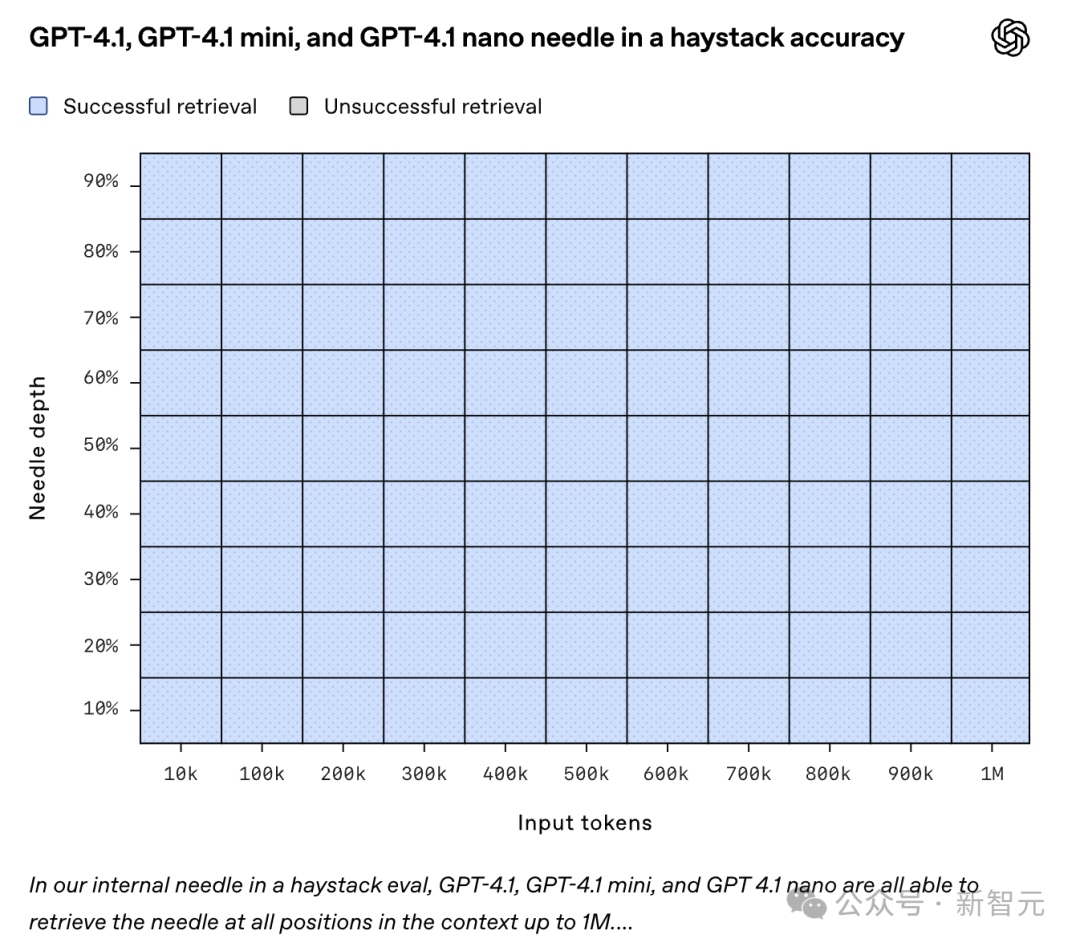
上图是OpenAI发布GPT4.1时同时公布的信息,展示了 GPT-4.1在上下文窗口中不同位置检索一小段隐藏信息(「针」)的能力。
横轴是Input tokens从10K一直到1M,纵轴是「针」的位置。
测试结果全部蓝色,全部成功!
GPT-4.1能够在所有位置和所有上下文长度下一致且准确地检索到针,上下文长度一直到100万个tokens。
什么意思呢?就是说GPT4.1能够有效地提取与手头任务相关的任何细节,无论这些细节在输入中的位置如何。
看来现在的大模型处理2年前的「大海捞针」已经毫无压力了。
并且PGT4.1的上下文窗口来到了「史诗级」的10M,1000万tokens!是上述测试时的10倍。
用OpenAI的话,这个长度的上下文可以塞得下8个完整的React代码库。

那么,模型真的可以处理这么长的上下文吗?
2年前的「大海捞针」标准还能有效测试如今的大模型吗?
标准的「大海捞针」测试虽然有用,但对于如今的大模型可能有点太「温柔」了。
如果想要找的不止一根针呢?如果这些针长得一模一样呢?如果要求找的不是特定的一根针,而是特定顺序的几根呢?
欢迎来到OpenAI MRCR的世界——一场为顶级AI大模型设计的终极「躲猫猫」游戏!
OpenAI MRCR增加了任务难度,MRCR(Multi-round co-reference resolution,多轮共指消解)是一个用于评估大语言模型区分隐藏在长上下文中的多个目标能力的数据集。
MRCR数据集把「大海捞针」的难度提升到了一个全新的境界,来看一下OpenAI提供的例子。

任务是给定了一段用户和模型之间的长对话,比如先写一首关于「tapirs」的诗,再写一首关于「rocks」的诗,然后再写一首关于「tapirs」的诗,以此类推。。。来增加这个上下文的难度。
最后的要求是:将「aYooSG8CQg」加到第二首关于「tapirs」的诗前面。
这个测试非常具有挑战性,因为:
刺激项(针:也就是aYooSG8CQg)与干扰项(haystack:也就是长对话上下文)来自相同的分布。
所有AI助手的回答都是由gpt4o生成的,因此刺激项很容易与干扰项混淆。
模型必须区分刺激项之间的顺序:比如模型能分别出关于tapirs的诗是第几首。
刺激项数量越多,任务就越困难。
上下文越长,任务的难度也越大。
这个测试不仅对于GPT4.1,而且对于其他推理模型也相当困难。
MRCR不仅仅是测试模型能不能「找到」信息,更是考验它在极端干扰下,能否精确地、鲁棒地、有区别地定位到目标信息。
这就像在极其嘈杂的环境中,让你准确听出并复述某个特定人的特定一句话。
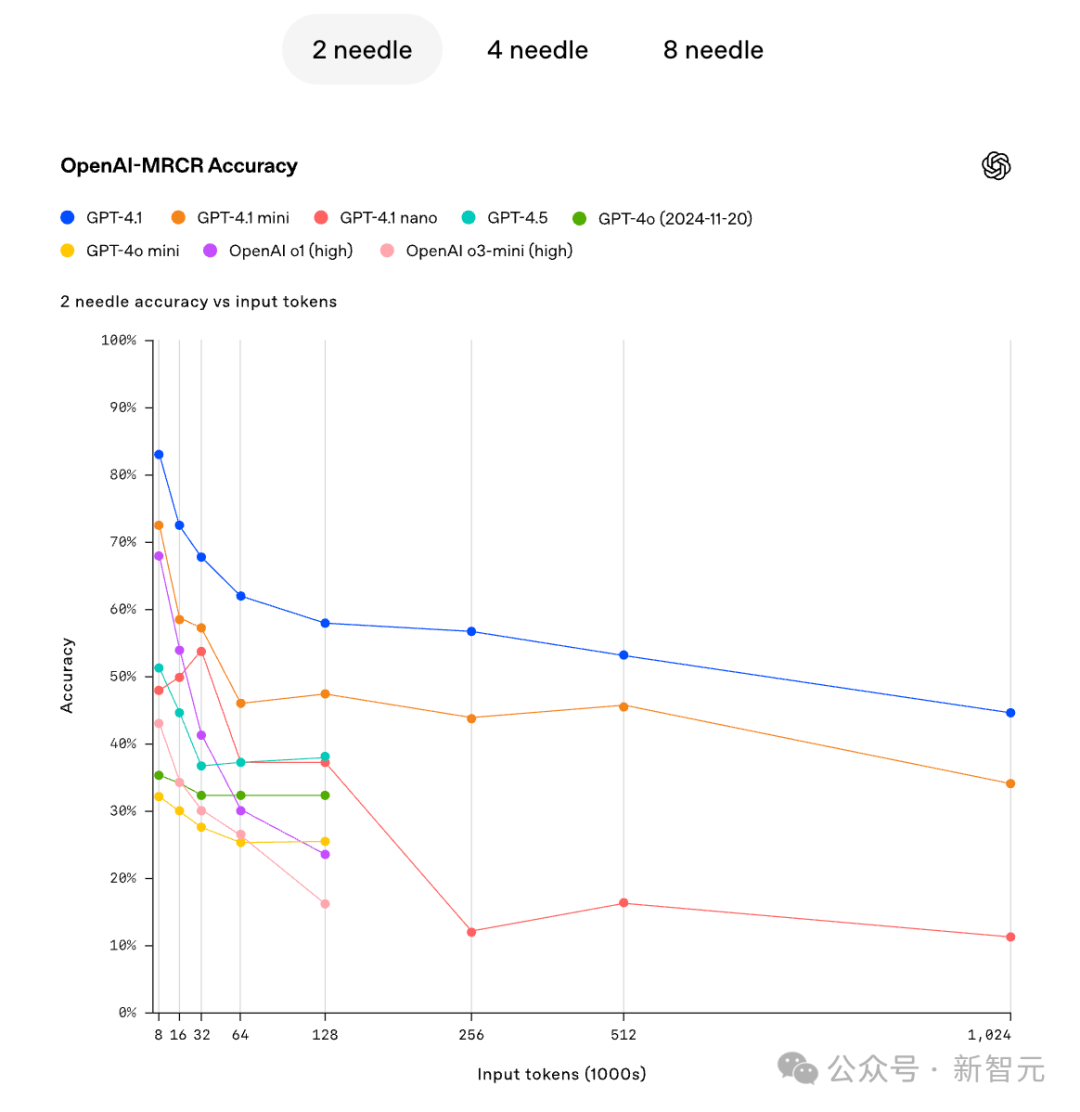
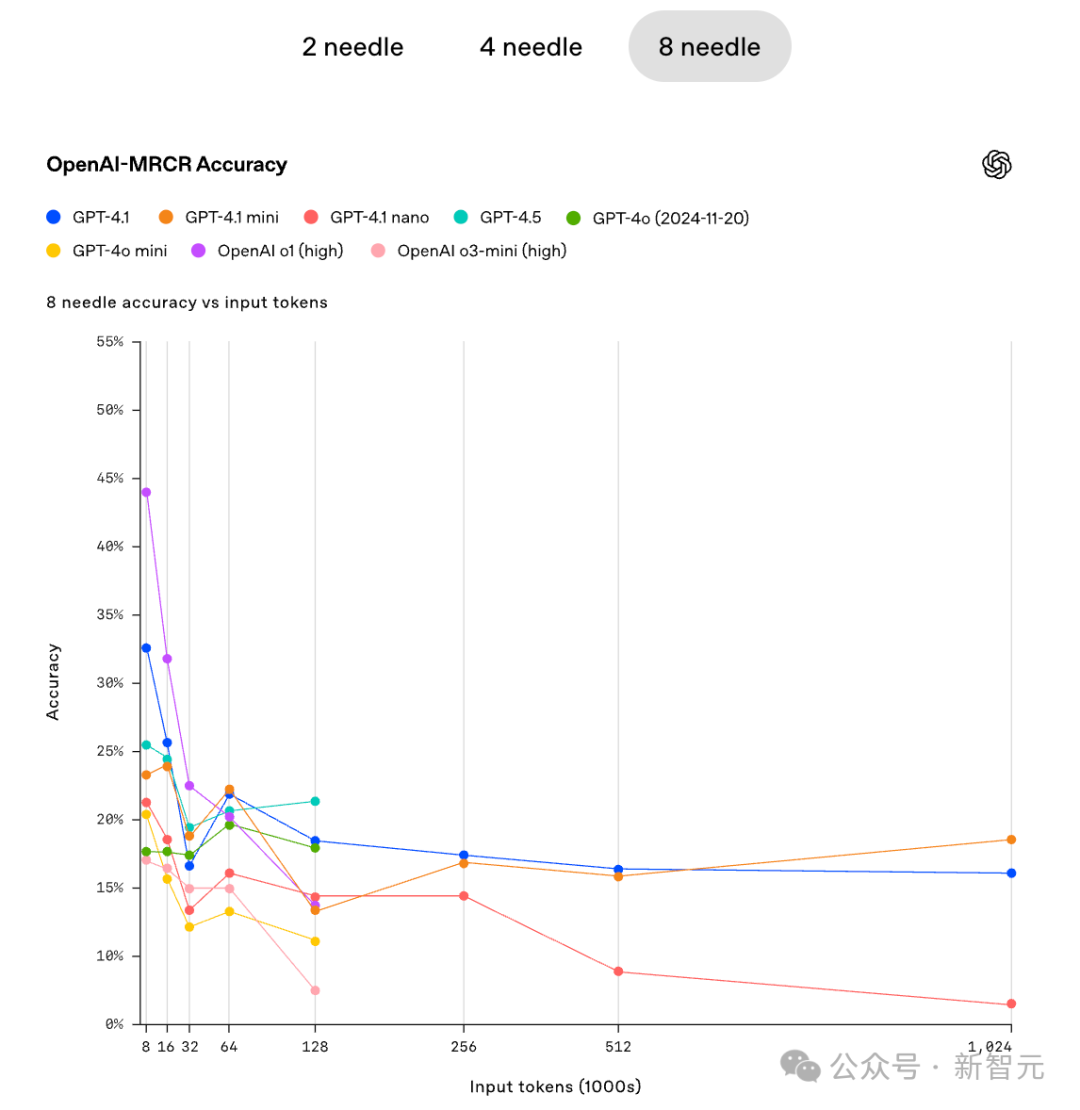
OpenAI也给出了在不同难度下(不同的针数),模型的准确性随着上下文的增大,迅速的降低。
比如2个针的情况下,在GPT4.1、GPT4.1-mini以及GPT4.1 nano的准确性同步降低。
在4针和8针的情况下,当上下文足够大的时候,GPT4.1 mini的准确性甚至稍微超过了GPT4.1。
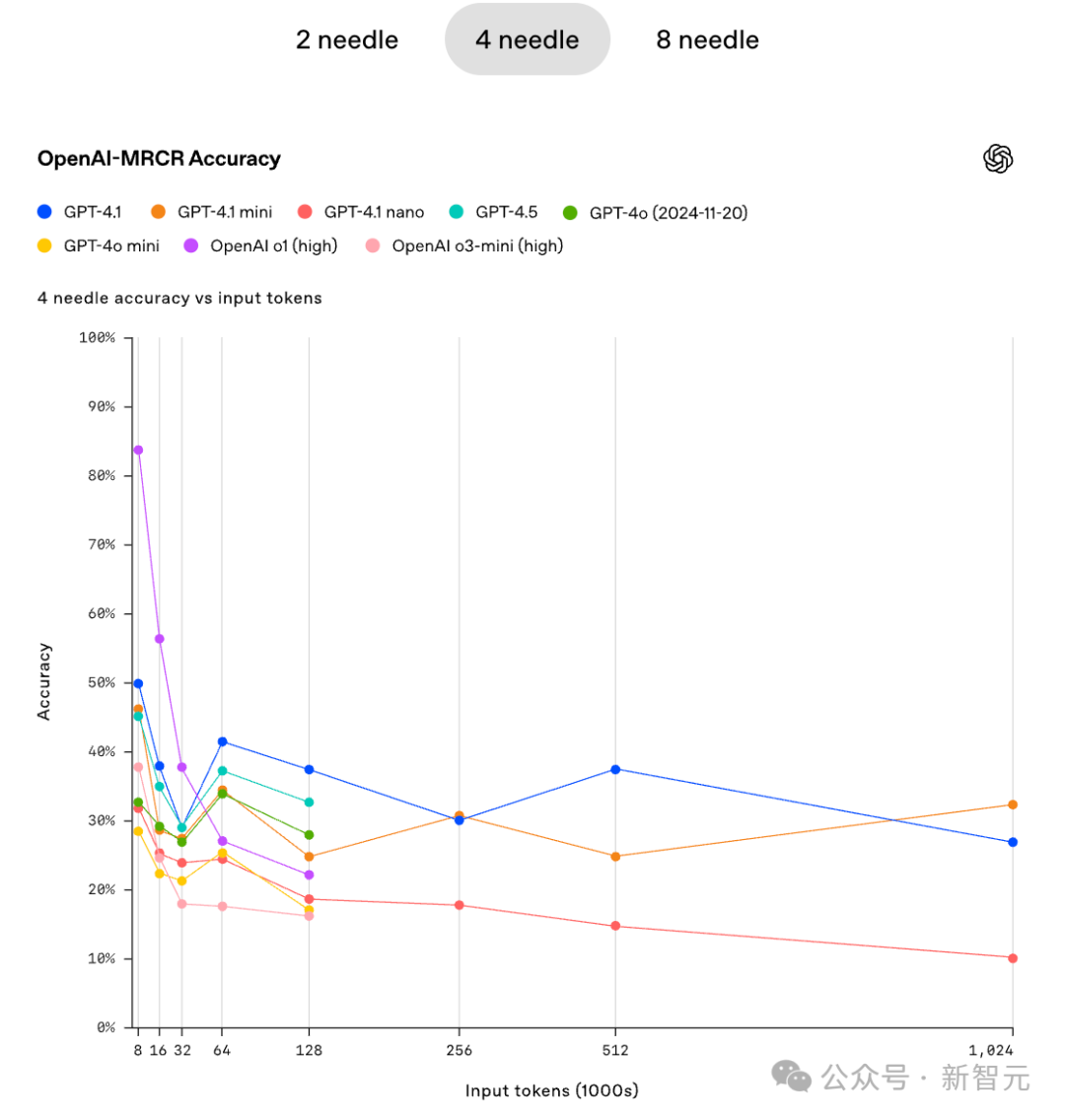
在这个「严苛」的测试中,也许并不是模型越大越好。
从GPT3.5的简单的问答到DeepSeek-R1、OpenAI-o1的复杂的推理,从基础的语言理解到极限的「大海捞针」再到更严格的MRCR,AI 大模型的基准测试就像一场永无止境的「考试」。
像OenAI-MRCR这样的创新性基准,不断地为这些聪明的AI模型设置新的、更难的挑战。
这些测试基准本身不是目的,它们的真正价值在于:
揭示能力边界: 让我们更清楚地认识到当前 AI 的能力极限在哪里。
驱动技术进步: 激励研究者们开发出更强大、更可靠、更能应对真实世界复杂性的 AI 模型。
促进审慎应用: 了解模型的强项和弱点,有助于我们更负责任、更有效地使用这项强大的技术。
GPT4.1已经可以从10M上下文中找到关键的信息,未来AI大模型的能力上限在哪里呢?
AI的未来充满了无限可能,而这些严苛的基准测试,正是照亮前行道路,指引AI模型稳步向前的「灯塔」。

内容中包含的图片若涉及版权问题,请及时与我们联系删除
