
Published on May 3, 2025 11:42 PM GMT
Strength
In 1997, with Deep Blue’s defeat of Kasparov, computers surpassed human beings at chess. Other games have fallen in more recent years: Go, Starcraft, and League of Legends among them. AI is superhuman at these pursuits, and unassisted human beings will never catch up. The situation looks like this:[1]
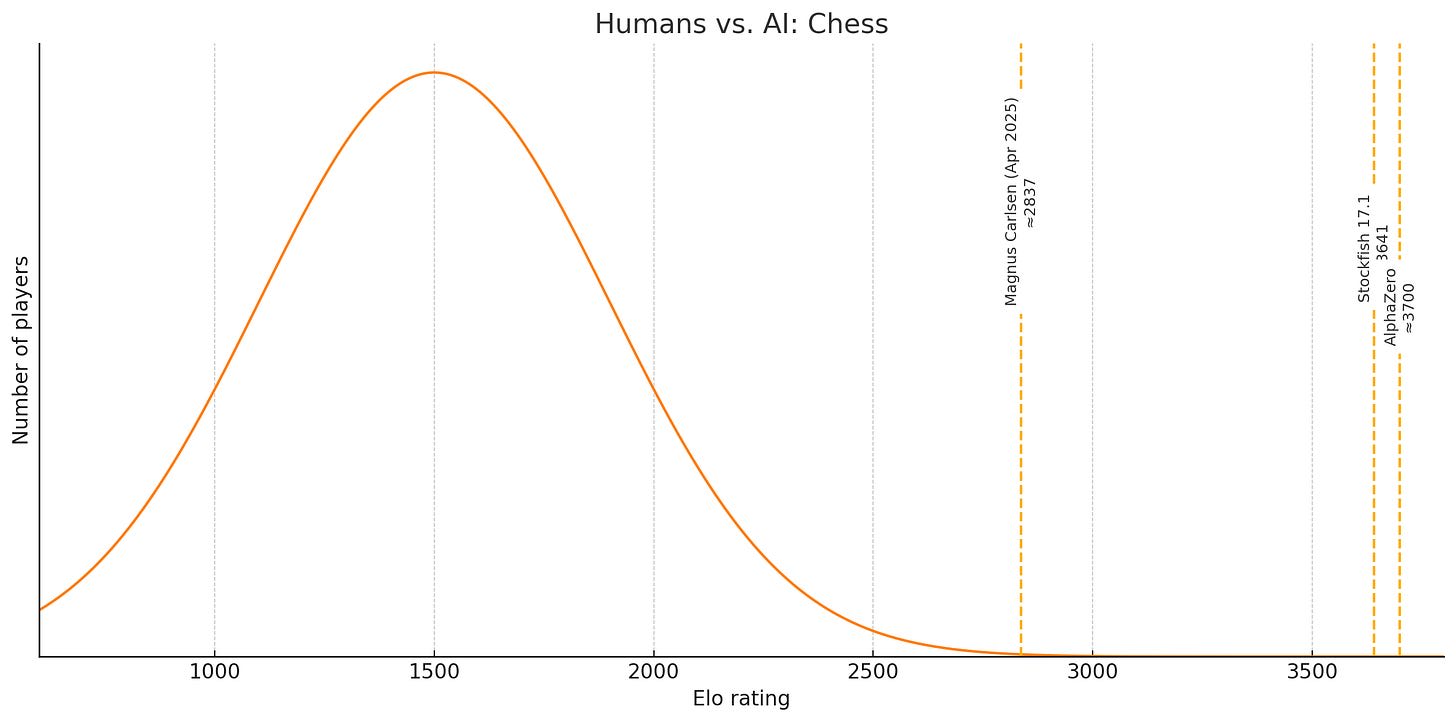
The average serious chess player is pretty good (1500), the very best chess player is extremely good (2837), and the best AIs are way, way better (3700). Even Deep Blue’s estimated Elo is about 2850 - it remains competitive with the best humans alive.
A natural way to describe this situation is to say that AI is superhuman at chess. No matter how you slice it, that’s true.
For other activities, though, it’s a lot murkier. Take radiology, for example:
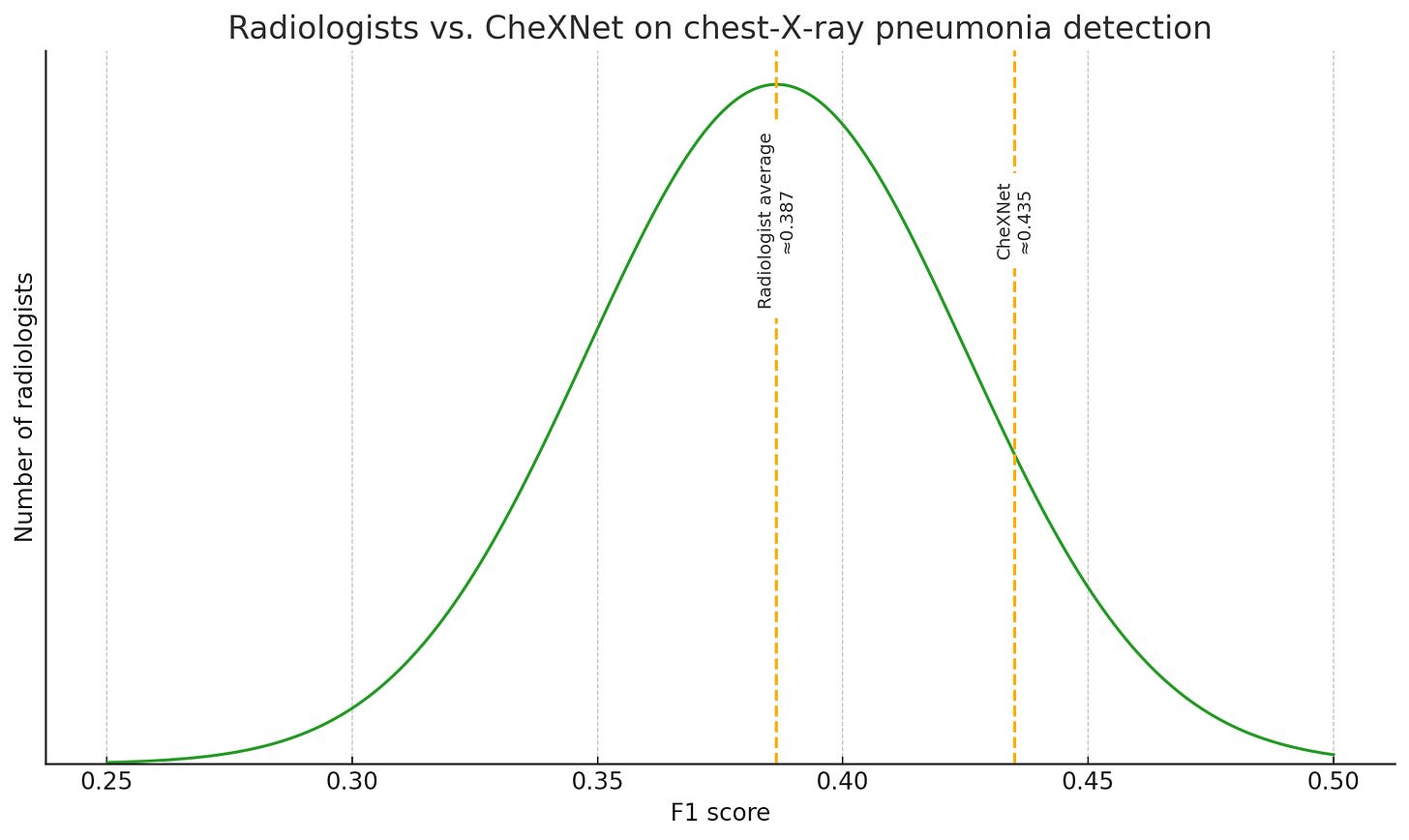
CheXNet is a model for detecting pneumonia. In 2017, when the paper was published, it was already better than most radiologists - of the four it was compared to in the study, it beat all but one. Is it superhuman? It’s certainly better than 99% of humans, since fewer than 1% of humans are radiologists, and it’s better than (about) 75% of those. If there were one savant radiologist who still marginally outperformed AI, but AI was better than every single other radiologist, would it be superhuman? How about if there was once such a radiologist, but he’s since dead, or retired?
We can call this the strength axis. AI can be better than the average human, better than the average expert, better than all but the very best human performers, or, like in the case of chess, better than everyone, full stop.
But that’s not the only axis.
Effort
The ARC-AGI benchmark is a series of visual logic puzzles that are easy (mostly) for humans, and difficult for AI. There’s a large cash prize for the first AI system that does well on them, but the winning system has to do well cheaply.
Why does this specification matter? Well, OpenAI’s industry leading o3 scored 87.5% on the public version of the benchmark, blowing many other models out of the water. It did so, however, by spending about $3000 per puzzle. A human can solve them for about $5 each.
Talking in terms of money undersells the difference, though. The way o3 did so well was by trying to solve each puzzle 1024 separate times, thinking through a huge number of considerations each time, and then choosing the best option. This adds up to a lot of thinking: the entire set of 100 questions took 5.7 billion tokens of thinking for the system to earn its B+. War and Peace, for reference, is about a million tokens.
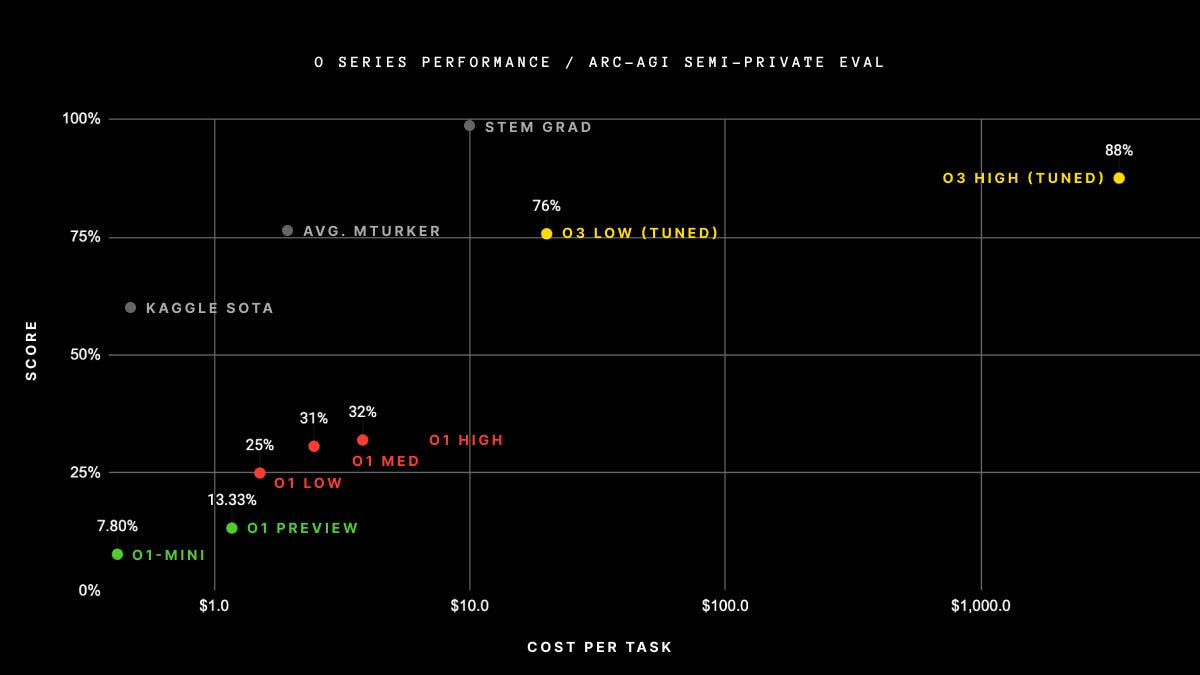
The average Mechanical Turker gets a little over 75%, far less than o3’s 87.5%. So is o3 human-level, or even superhuman? In some narrow sense, sure. But it had to write War and Peace 5,700 times to get there, and spend significantly more than most people’s annual salaries.
We can call this axis the effort axis. Like the strength axis, it has various levels. A system can perform a task for negligible cost, or for approximately how much a human would charge, or for way more than a human would charge, or for astronomical sums.
And More
These axes combine! A system that costs $10,000 to do a task better than any human alive is one kind of impressive, and a system that exceeds the human average for pennies is another. Nor are strength and effort the only considerations; lots of tasks have dimensions particular to them.
Take persuasion. A recent study (which may be retracted/canceled due to ethics concerns) showed that LLM systems did better than (most) humans at changing people’s views on the subreddit r/changemyview. Try to unpack this, and it’s way more complicated than chess, ARC-AGI, or radiology diagnosis. To name just a few dimensions:
- Are we measuring changing someone’s view a little or a lot?Are we measuring changing a view that someone holds tightly, or one that someone holds loosely?Are we allowed to tailor our arguments to persuade a specific person? (The bots in the study read the post histories of the people they were trying to convince! Welcome to the future, baby.)
- For a salesperson, this is huge. For a TV personality, negligible.
- If we are trying to motivate action, how significant is the action, measured various ways? I can imagine a system that’s superhuman at getting people to donate $5, but subhuman at getting people to join a monastery (or go to rehab).
Many capabilities we care about are more like persuasion than chess or radiology diagnostic work. A drop-in remote worker, for example, needs to have a lot of fuzzy “soft skills” that are not only difficult to ingrain, but difficult to measure.
Beyond “Superhuman”
Probably, you don’t see people calling AI “superhuman” all the time. But there are lots of related terms used the same way. Questions like:
- Is this new model AGI?Is this new model “human level”?Is this new model “as smart as a PhD/expert”?
These questions try to compress a multidimensional spectrum into a binary property. The urge makes sense, and sometimes, like with chess, the “is it superhuman” question has a clear cut answer. But unless the case is that clear cut, it’s probably better to ask narrower questions, and to think carefully when performance claims are flying around.
- ^
Yeah, I know this graph (and the next) wouldn't actually be normal distributions. I don't think it matters for the purposes of this post, though.
Discuss
