


Retrieval-Augmented Generation (RAG) techniques face significant challenges in integrating up-to-date information, reducing hallucinations, and improving response quality in large language models (LLMs). Despite their effectiveness, RAG approaches are hindered by complex implementations and prolonged response times. Optimizing RAG is crucial for enhancing LLM performance, enabling real-time applications in specialized domains such as medical diagnosis, where accuracy and timeliness are essential.
Current methods addressing these challenges include workflows involving query classification, retrieval, reranking, repacking, and summarization. Query classification determines the necessity of retrieval, while retrieval methods like BM25, Contriever, and LLM-Embedder obtain relevant documents. Reranking refines the order of retrieved documents, and repacking organizes them for better generation. Summarization extracts key information for response generation. However, these methods have specific limitations. For instance, query rewriting and decomposition can improve retrieval but are computationally intensive. Reranking with deep language models enhances performance but is slow. Existing methods also struggle with efficiently balancing performance and response time, making them unsuitable for real-time applications.
The researchers from Fudan University conducted a systematic investigation of existing RAG approaches and their potential combinations to identify optimal practices. A three-step approach was adopted: comparing methods for each RAG step, evaluating the impact of each method on overall RAG performance, and exploring promising combinations for different scenarios. Several strategies to balance performance and efficiency are suggested. A notable innovation is the integration of multimodal retrieval techniques, which significantly enhance question-answering capabilities about visual inputs and accelerate multimodal content generation using a “retrieval as generation” strategy. This approach represents a significant contribution to the field by offering more efficient and accurate solutions compared to existing methods.
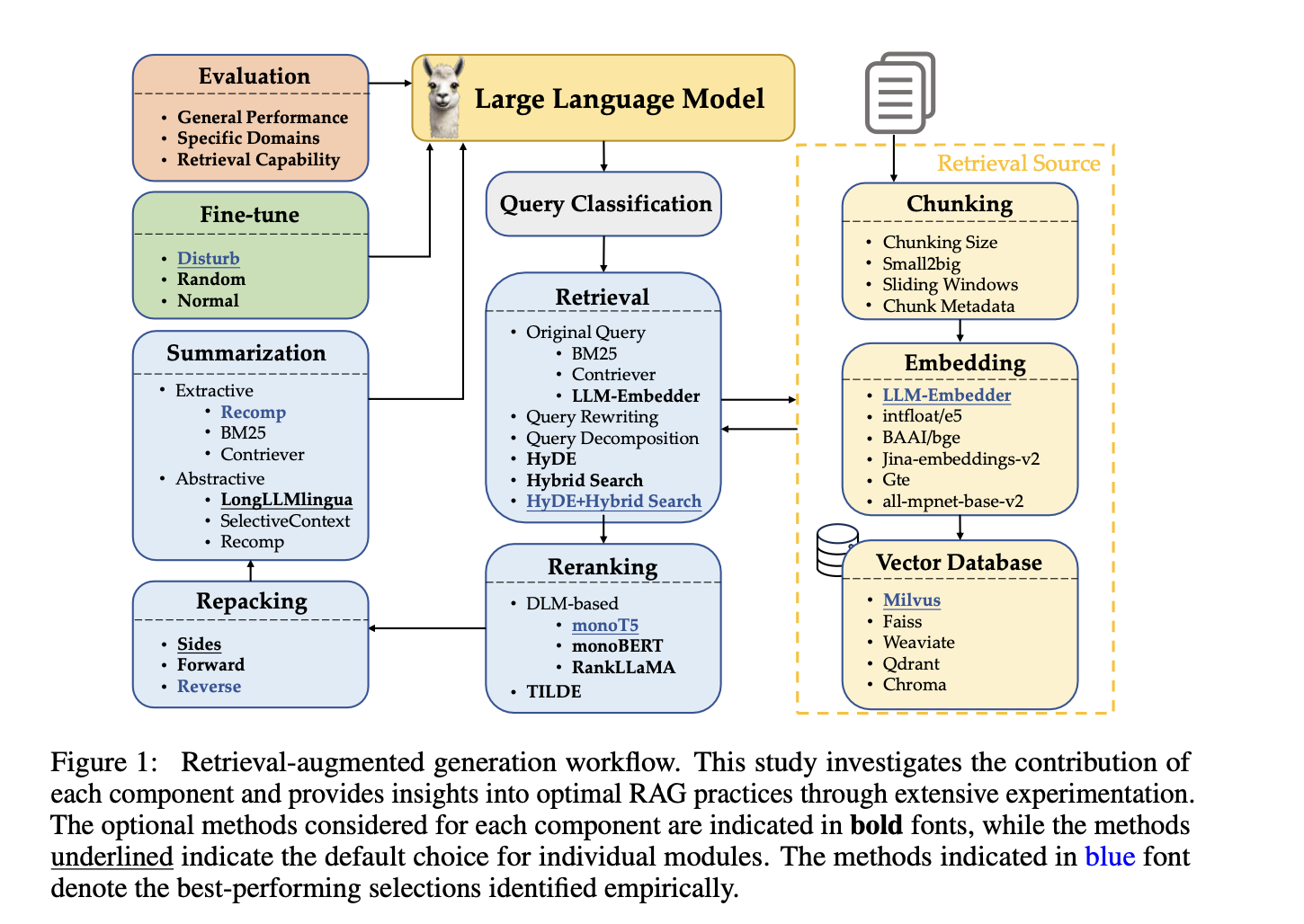
The evaluation involved detailed experimental setups to identify best practices for each RAG module. Datasets such as TREC DL 2019 and 2020 were used for evaluation, with various retrieval methods including BM25 for sparse retrieval and Contriever for dense retrieval. The experiments tested different chunking sizes and techniques like small-to-big and sliding windows to improve retrieval quality. Evaluation metrics included mean average precision (mAP), normalized discounted cumulative gain (nDCG@10), and recall (R@50 and R@1k). Additionally, the impact of fine-tuning the generator with relevant and irrelevant contexts to enhance performance was explored.
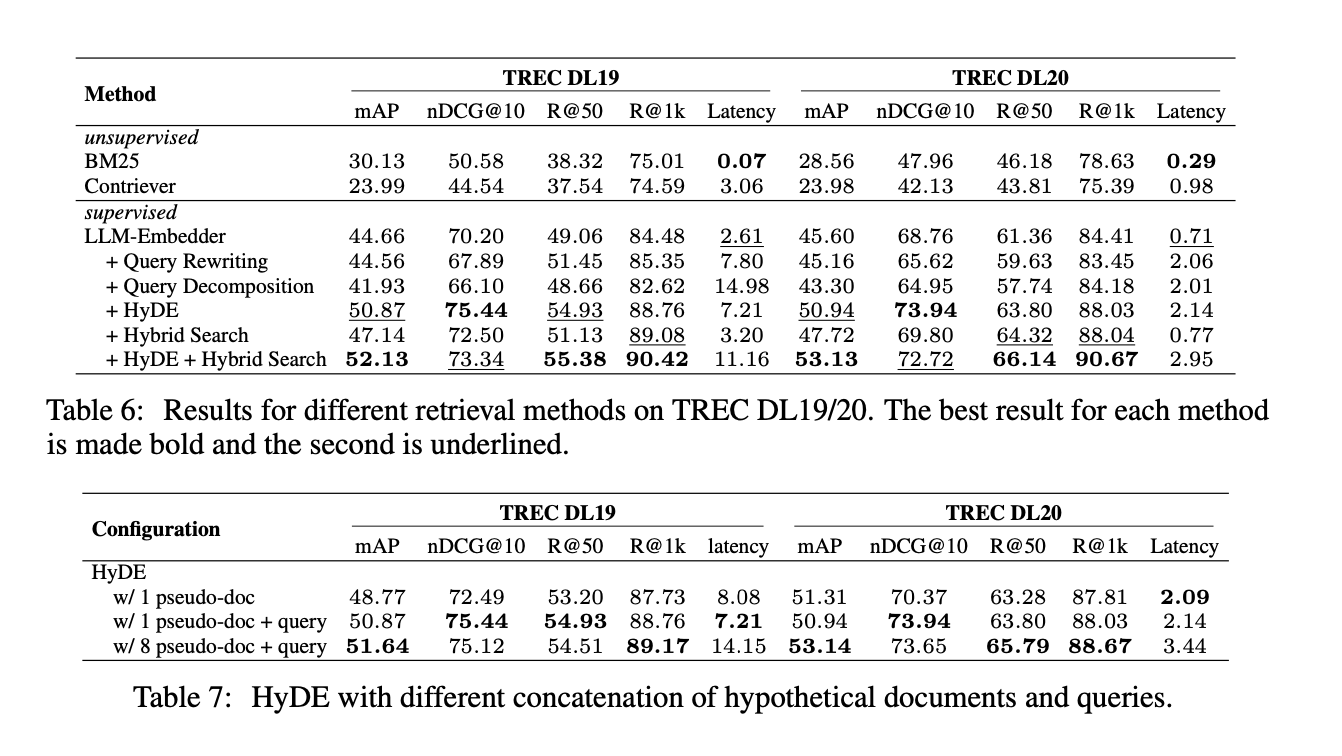
The study achieves significant improvements across various key performance metrics. Notably, the Hybrid with HyDE method attained the highest scores in the TREC DL 2019 and 2020 datasets, with mean average precision (mAP) values of 52.13 and 53.13, respectively, substantially outperforming baseline methods. The retrieval performance, measured by recall@50, showed notable enhancements, reaching values of 55.38 and 66.14. These results underscore the efficacy of the recommended strategies, demonstrating substantial improvements in retrieval effectiveness and efficiency.

In conclusion, this research addresses the challenge of optimizing RAG techniques to enhance LLM performance. It systematically evaluates existing methods, proposes innovative combinations, and demonstrates significant improvements in performance metrics. The integration of multimodal retrieval techniques represents a significant advancement in the field of AI research. This study not only provides a robust framework for deploying RAG systems but also sets a foundation for future research to explore further optimizations and applications in various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Enhancing Language Models with RAG: Best Practices and Benchmarks appeared first on MarkTechPost.
