
Published on May 1, 2025 9:11 PM GMT
[Crossposted from my substack Working Through AI.]
It’s pretty normal to chunk the alignment problem into two parts. One is working out how to align an AI to anything at all. You want to figure out how to control its goals and values, how to specify something and have it faithfully internalise it. The other is deciding which goals or values to actually pick — that is, finding the right alignment target. Solving the first problem is great, but it doesn’t really matter if you then align the AI to something terrible.
This split makes a fair amount of sense: one is a technical problem, to be solved by scientists and engineers; whereas the other is more a political or philosophical one, to be solved by a different class of people — or at least on a different day.
I’ve always found this distinction unsatisfying. Partly, this is because the problems are coupled — some targets are more practical to implement than others — and partly because, strategically, when you work on something, it makes sense to have some kind of end state in mind[1].
Here, I’m going to talk about a third aspect of the problem: what does an alignment target even look like? What different types are there? What components do you need to properly specify one? You can’t solve either of the two parts described above without thinking about this. You can’t judge whether your alignment technique worked without a clear idea of what you were aiming for, and you can’t pick a target without knowing how one is put together in the first place.
To unpack this, I’m going to build up the pieces as they appear to me, bit by bit, illustrated with real examples. I will be keeping this high-level, examining the practical components of target construction rather than, say, a deep interrogation of what goals or values are. Not because I don’t think the latter questions are important, I just want to sketch out the high-level concerns first.
There are many ways of cutting this cake, and I certainly don’t consider my framing to be definitive, but I hope it adds some clarity to what can be a confusing concept.
Moving beyond ideas
First of all, we need to acknowledge that an alignment target must be more than just a high-level idea. Clearly, stating that we want our AI to be truth-seeking or to have human values does not advance us very far. These are not well-defined categories. They are nebulous, context-dependent, and highly-subjective.
For instance, my own values may be very different to yours, potentially in ways that are hard for you to understand. This can still be true even when we use exactly the same words to describe them — who, after all, is opposed to fairness or goodness? My values are not especially coherent either, and depend somewhat on the kind of day I’m having. This is not me being weird — it is entirely typical.
To concretely define an alignment target requires multiple steps of clarification. We must be crystal clear what we mean, and this clarity must extend to all relevant actors. While ideas will always be our starting point, we need to flesh them out, making them legible and comprehensible to other people, before ultimately trying to create a faithful and reliable translation inside an AI.
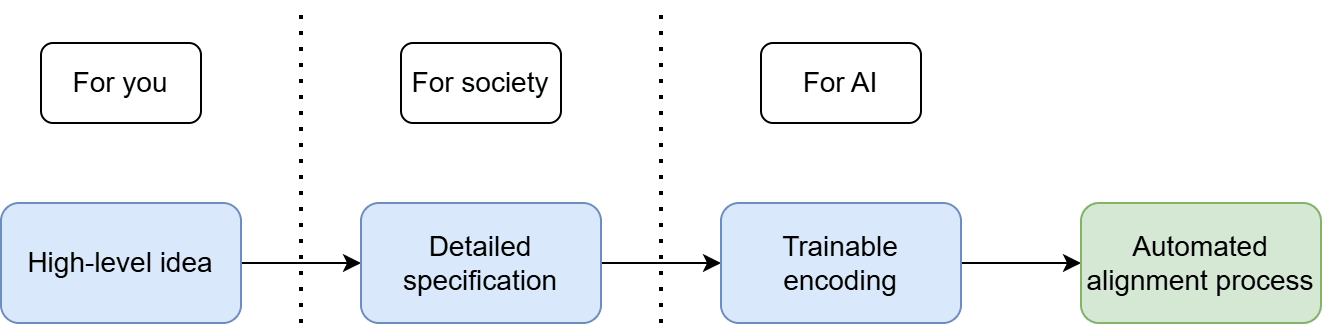
To make this process more explicit, I like to picture it as a three-step recipe — a sequence you can follow to generate a target:
- Come up with a high-level idea (or ideas). Perhaps this is something broad like human values or more specific like helpfulness or obedience. While these terms are not well defined, you (and your collaborators) will know roughly what you mean by them.Create a detailed specification. Take your idea and flesh it out, eliminating as much ambiguity as possible. Traditionally, this would be a written document, but I can’t think of a good reason why it couldn’t also include other modalities, like video. At this step, it is possible to have a meaningful public conversation about the merits of your proposed target.Create a trainable encoding. Translate your specification into an appropriate format for your alignment process, which in theory could be automated from this point onwards. This is the last point of human influence over the target.
One way of understanding this division is by audience: who will consume the output? Step (1) is for you and people close to you, step (2) is for society in general, and step (3) is for AI.
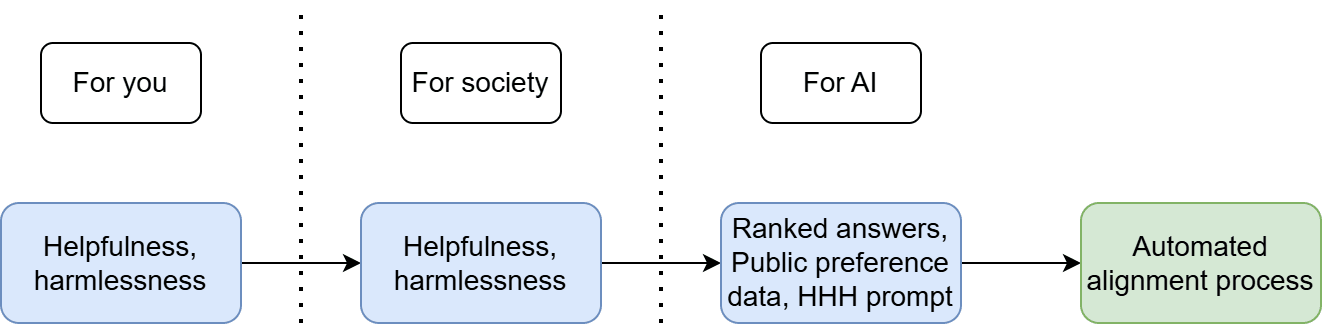
What does this look like in practice? Well, let’s start with Anthropic’s example of training a helpful and harmless assistant using reinforcement learning from human feedback (RLHF). Following our three steps, we can describe their alignment target as follows:
- Their high-level idea was that the model should be helpful and harmless.They didn’t create a specification, preferring to stick with the high-level terms. This was a few years ago when these things were lower stakes, so they were more concerned with testing their alignment process than defining a rigorous target.There are a few different parts to their trainable encoding, each a source of information about the target provided to the alignment process:
- They employed crowd workers to rate model responses for helpfulness and harmlessness. This way, they built up a dataset of ranked answers they could use to fine-tune ‘preference models’, which provide helpfulness and harmlessness ratings to the model during reinforcement learning.To make them easier to train on the ranked answers, the preference models were first fine-tuned on public datasets containing preferences, like StackExchange, Reddit, and Wikipedia edits.A helpfulness, harmlessness, and honesty (HHH) prompt, which they train into the model prior to the start of reinforcement learning.
We can see from this how integrated the process is. The what, helpfulness and harmlessness, are ultimately defined in terms of the how, the encoding required to get RLHF to work.
It’s important to note that the boundary I’ve drawn between the encoding and alignment process is fuzzy. In my description of Anthropic’s encoding, I only included information that had been explicitly provided to guide the alignment process. However, this ignores that most choices come packaged with implicit values. The pre-training dataset of the preference models[2], for instance, will affect how they interpret the ranked answers, even though it wasn’t selected with this purpose in mind. Unfortunately, I have to draw a line somewhere, or we would end up saying the entire alignment process is part of the target, so I’ve done so at the explicit/implicit boundary.
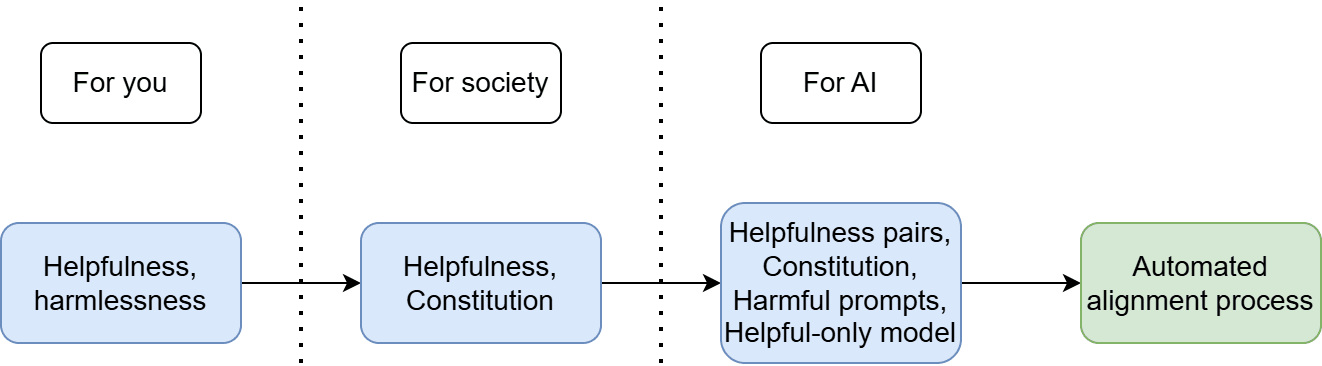
Let’s look at another example, this time one with a proper detailed specification. In fact, let’s look at Constitutional AI, Anthropic’s replacement for RLHF. This they deemed more transparent and scalable, and used it to align Claude. Applying our recipe again, we can break it down as follows:
- Their high-level idea was still to have a helpful and harmless model.Now we have a specification. More specifically, Claude's Constitution, outlining a list of principles it should be expected to follow. Some of these draw on the UN Declaration of Human Rights and Apple’s terms of service, alongside many more bespoke ones.Once again, there are a few different parts to the trainable encoding:
- Some human-ranked helpfulness data — in the original paper at least, the constitutional innovation was only applied to the harmfulness side of the alignment target.The principles in the Constitution, which were repeatedly referenced by models during the alignment process, both to generate an initial supervised learning dataset to fine-tune the model on, as well as to create ranked answers that could be used with the human-ranked helpfulness data to train a perference model.Harmfulness prompts used to generate the data for both the supervised and reinforcement learning steps.A ‘helpful-only AI assistant’, which generated harmful content in response to the harmfulness prompts, and then revised it according to the Consitution in order to create the supervised learning dataset.
More recent work like Deliberative Alignment from OpenAI follows a similar pattern, using a ‘Model Spec’ instead of a constitution[3].
Target-setting processes
While our three-part system is nice, fleshing out what an alignment target can look like in practice, it is only the first part of the story, and there are other considerations we need to address. One of these is to go a bit meta and look at target-setting processes.
At first glance, this might seem like a different topic. We’re interested in how to specify an alignment target, not how to select one. Unfortunately, this distinction is not so simple to make. Consider political processes as an analogy. While I might have a bunch of policy preferences I would like enacted, if you asked me how my country should be run I would not say ‘according to my policy preferences’. I would instead advocate for a policy-picking system, like a representative democracy. This could be an ideological preference, recognising that I should not hold special power, in which case the political process itself is effectively my highest policy preference. Or it could be a pragmatic one — I couldn’t force people to follow my commandments even if I wanted to, so I should concentrate my advocacy on something more widely acceptable. The same ideas apply to alignment targets.
Perhaps the key point is to recognise that the target-setting process is where the power in the system resides[4]. A lot of discussions about alignment targets are really about power, about whose values to align the AI to. To properly contextualise what your alignment target is — to understand what the system around the AI is trying to achieve — you will need to specify your target-setting process as well[5].
To address this, I’m going add an extra layer to our schematic, acting from the outside to influence the structure and content of the other components:
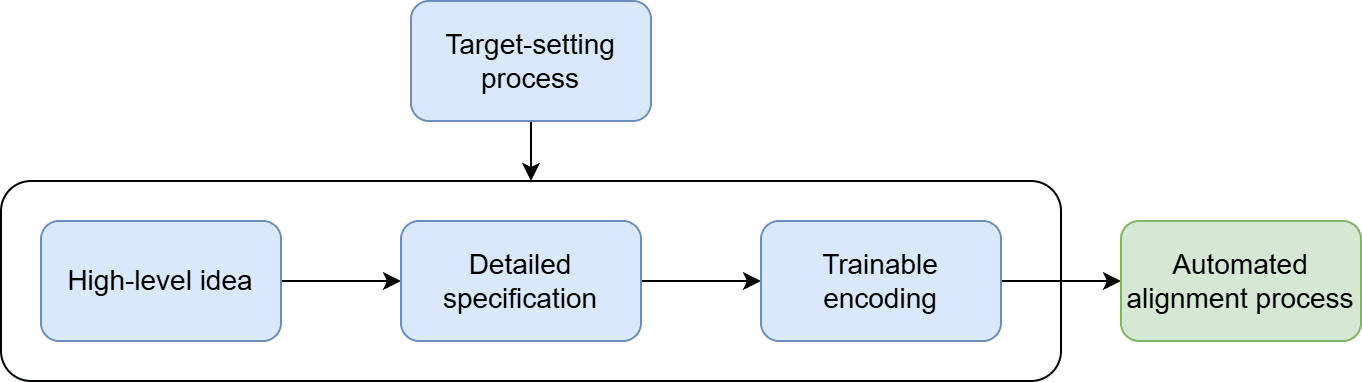
Let’s look at some examples. First of all, what target-setting processes exist today? Broadly speaking, they consist of AI labs deciding what they think is best for their own AIs, with a bit of cultural and legal pressure thrown in. That being said, moving to transparent specifications, like Claude’s Constitution or OpenAI’s Model Spec, makes their alignment targets a bit more the product of a public conversation than in the past. For example, here is OpenAI describing their emerging process for updating their Model Spec:
In shaping this version of the Model Spec, we incorporated feedback from the first version as well as learnings from alignment research and real-world deployment. In the future we want to consider much more broad public input. To build out processes to that end, we have been conducting pilot studies with around 1,000 individuals — each reviewing model behavior, proposed rules and sharing their thoughts. While these studies are not reflecting broad perspectives yet, early insights directly informed some modifications. We recognize it as an ongoing, iterative process and remain committed to learning and refining our approach.
This doesn’t sound formalised or repeatable yet, but it is moving in that direction.
Taking this further, let’s speculate about possible formal processes. Unsurprisingly, given the point is to adjudicate value questions, this can look quite political. For instance, it could involve an elected body like a parliament, either national or international, or something like a citizen’s assembly. The devil is, of course, in the detail, particularly as you need to decide how to guide the deliberations, and how to translate the results into a detailed specification and trainable encoding.
One proposal is Jan Leike’s suggestion for Simulated Deliberative Democracy. To address the issue of scalability, as AI becomes widely deployed and begins to operate beyond our competency level, Jan goes in heavy on AI assistance. In his own words:
The core idea is to use imitation learning with large language models on deliberative democracy. Deliberative democracy is a decision-making or policy-making process that involves explicit deliberation by a small group of randomly selected members of the public (‘mini-publics’). Members of these mini-publics learn about complex value-laden topics (for example national policy questions), use AI assistance to make sense of the details, discuss with each other, and ultimately arrive at a decision. By recording humans explicitly deliberating value questions, we can train a large language model on these deliberations and then simulate discussions on new value questions with the model conditioned on a wide variety of perspectives.
Essentially, you convene a bunch of small assemblies of people, give them expert testimony (including AI assistance), and let them arrive at decisions on various value questions. You then train an AI on their deliberations, ending up with a system that can simulate new assemblies (of arbitrary identity groups) and scale up to answer millions of new questions. I would guess that these answers would be more than just high-level ideas, and would operate at the specification level, perhaps coming out looking like legislation. Some other protocol would be required to encode them and feed them into the alignment process.
The space of possible target-setting processes is large and under-explored. There just aren’t many experiments of this kind being done. Jan also makes the point that target setting is a dynamic process: ‘We can update the training data fairly easily... to account for changes in humanity’s moral views, scientific and social progress, and other changes in the world.’ Which brings us to our next consideration.
Keeping up with the times
An appropriate target today will not necessarily be one tomorrow.
In a previous post, I talked about how politeness is a dynamic environmental property:
What counts as polite is somewhat ill-defined and changes with the times. I don’t doubt that if I went back in time two hundred years I would struggle to navigate the social structure of Jane Austen’s England. I would accidentally offend people and likely fail to win respectable friends. Politeness can be seen as a property of my particular environment, defining which of my actions will be viewed positively by the other agents in it.
Jane Austen’s England had a social system suited to the problems it was trying to solve, but from our perspective in the early 21st century it was arbitrary and unjust. We are trying to solve different problems, in a different world, using different tools and knowledge, and our value system is correspondingly different.
The concept of superhuman AI, or one stage of it, is sometimes referred to as ‘transformational’ AI. The world will be a very different place after it comes about, for good or ill. Whatever values we have now will not be the same as we will have after.
This suggests that, arguably, figuring out how to update your target is just as important as setting it in the first place. A critical consideration when doing this is that, if our AI is now broadly superhuman, it may be much harder to refine the target than before. If our AI is operating in a world beyond our understanding, and is reshaping it in ways equally hard for us to follow, then we cannot just continue to rerun whatever target-setting process we had previously.
Bearing this in mind, I think there are a few different ways of categorising the dynamics of alignment targets. I’ve settled on three I think are useful to recognise:
1. Static targets: humans define a target once and leave it for the rest of time. E.g. write a single constitution and keep it. Whatever values are enshrined in it will be followed by the AI forever.
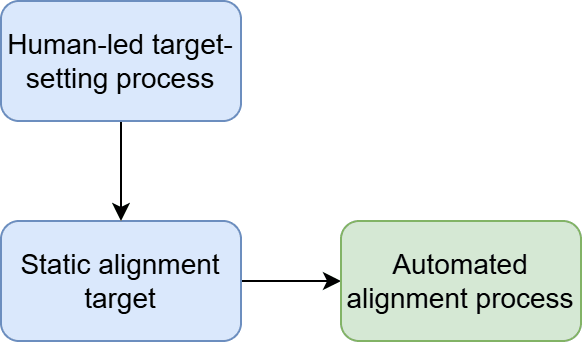
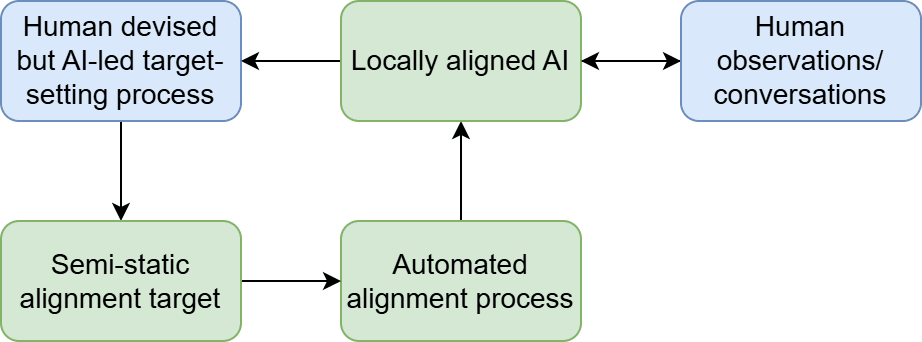
2. Semi-static targets: humans, on one single occasion, specify a dynamic target-setting process for the AI to follow, which it then follows forever. The AI can collect data by observing and speaking to us, which allows us to retain some limited influence over the future, but we are not primarily in control any more. E.g. we could tell the AI to value whatever we value, which will change as we change, and it will figure this out by itself.
3. Fully dynamic targets: humans are continuously in meaningful control of the alignment target. If we want to tell the AI to stop doing something it is strongly convinced we want, or to radically change its values, we can. However, in the limit of superhuman AI, we will still need assistance from it to understand the world and to properly update its target. Put another way, while humans are technically in control, we will nevertheless require a lot of AI mediation.
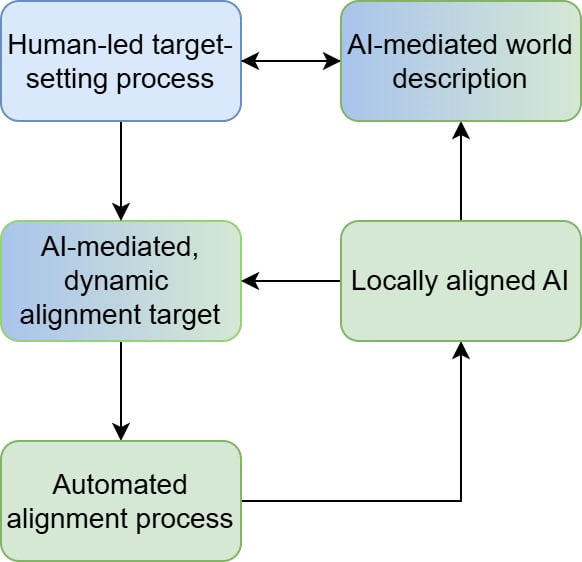
The distinctions between these target types are not sharp. Looked at in a certain way, (1) and (2) are the same — you seed the AI with initial instructions and let it go — and looked at in another, (2) and (3) are the same — the AI consistently references human preferences as it updates its values. But I think there are still a lot of useful differences to highlight. For instance, in (2), what the AI values can change drastically in an explicit way, whereas in (1) it cannot. In (3), humans retain fundamental control and can flip the gameboard at any time, whereas in (2) we’re being kind of looked after. It is worth noting that (3) implies the AI will allow you to change its target, whereas (1) does not, and (2) is noncommital.
Let’s look at some examples of each:
- Static targets:
- Have a worldwide conversation or vote where we collectively agree a definitive set of human values we want the AI to respect forever.Solve moral philosophy[6]or tell the AI to do it (and trust its answer).Society, or simply the lab building the AI, has a dynamic process for selecting targets, which is followed each time a new model is trained. However, at some point the AI becomes superhuman and the lab’s alignment process is insufficient to cope with this, locking in the last target forever. One way of thinking about this situation is that dynamic targets can become static when they fail.
Eliezer Yudkowsky’s Coherent extrapolated volition (CEV):
Roughly, a CEV-based superintelligence would do what currently existing humans would want the AI to do, if counterfactually:
We knew everything the AI knew;We could think as fast as the AI and consider all the arguments;We knew ourselves perfectly and had better self-control or self-modification ability.
This functions as a protocol for the superintelligent AI to follow as it updates its own values. There are plenty of variations on this idea — that superintelligent AI can learn a better model of our values than we can, so we should hand over control and let it look after us.
- Develop an AI that reliably and faithfully follows your instructions[7]. This collapses onto a static target in the limit where you never ask the AI to change its own alignment. You might question why you would want to do that, but it may well be the case that whatever technique worked to create instruction-following AI at one level of intelligence will cease to work as it gets smarter (and as the environment changes), necessitating corrections.Jan Leike’s Simulated Deliberative Democracy: each time through the loop, you run some human mini-publics with AI assistance to update the training data. This could be done on a regular cadence or as and when problems in the current value-set are flagged.Beren Millidge has written about how we should treat alignment as a feedback control problem. Starting with a reasonably well-aligned model, we could apply control theory-inspired techniques to iteratively steer an AI as it undergoes recursive self-improvement.
What next?
My particular interest in this problem dates from a conversation I had with some AI safety researchers a few years ago, during which I realised they each had very different ideas of what it meant to pick an alignment target. I spent a long while feeling confused as to who was right, and found writing the material for this post a really effective way of deconfusing myself. In particular, it lent structure to the different assumptions they were making, so I could see them in context. It has also helped me see which bits of my own ideas feel most important, and in what places they are lacking.
On that point, I will briefly comment on my preferred direction, albeit one still stuck in the high-level idea phase. I think you can build a dynamic target around the idea of AI having a moral role in our society. It will have a set of responsibilities, certainly different from human ones (and therefore requiring it to have different, but complementary, values to humans), which situate it in a symbiotic relationship with us, one in which it desires continuous feedback[8]. I will develop this idea more in the future, filling out bits of the schema in this post as I go.
If you have any feedback, please leave a comment. Or, if you wish to give it anonymously, fill out my feedback form. Thanks!
- ^
This is why I advocate defining What Success Looks Like fairly early on in any research agenda into risks from superhuman AI. I hope to reach this step in my own agenda reasonably soon!
- ^
By this I mean the pre-training data of the base model, not what they refer to in the paper as ‘preference model pretraining’, which I included earlier as part (b) of the trainable encoding.
- ^
Although, the alignment process is a little different.
- ^
Assuming the alignment problem is solved, anyway.
- ^
This will become more obvious later when we talk about dynamics.
- ^
I want to put on the record that I believe moral philosophy is neither solvable nor the right system to use to address important value questions. Morality is primarily a practical discipline, not a theoretical one.
- ^
I have my suspicions that, in order for the AI to reliably do what you mean rather than merely what you say, this actually cashes out as functionally the same as aligning the AI to your values. More specifically, when you ask an AI to do something, what you really mean is ‘do this thing, but in the context of my broader values’. The AI can only deal with ambiguity, edge cases, and novelty by referring to a set of values. And you can’t micromanage if it is trying to solve problems you don’t understand.
- ^
If you’ve just read that and thought ‘well that’s vague and not particularly useful’, you’ll maybe see why I designated the audience for the high-level idea step as the author themselves.
Discuss
