
上次本地部署了 Spark-TTS 文本转音频模型,但是发现处理长文本的时候,生成的音频文件中句子和句子之间有时候会出现比较长的空白(有可能是它本身的 bug,也有可能是我本地部署不正确导致)。这样使用过程中就得人为做长文本的拆分,分块处理,然后再合并最终的各个小音频文件。使用起来有点繁琐。
基于这个小问题,重新找了一个新的文本转音频模型——F5-TTS 做本地部署。
github.com/SWivid/F5-T… 因为有前面 Spark 的经验再加F5本身的文档写的很详细,这次在 Mac 上部署非常顺利。以下为详细过程记录。
部署
第一步创建conda环境并且激活
conda create -n f5-tts python=3.10conda activate f5-tts第二步,根据PC情况安装PyTorch
这个模型 PyTorch GPU 适配这块确实做的不错,分别提供了英伟达 GPU、AMD GPU、英特尔 GPU、苹果 GPU(Apple Silicon)四种。Mac 电脑如下:
pip install torch torchaudio其他类型大家可以自行查看官方文档。
第三步,安装模型文件
这里也是提供两种方式:
1)pip 直接安装;这种方式就仅支持模型推理,没法做训练或微调。
pip install f5-tts2)先从 github 克隆,然后再用 pip 安装。这种方式功能完整,可以推理,也可以做训练和微调。所以我用了这种方式来安装。
git clone https://github.com/SWivid/F5-TTS.gitcd F5-TTSpip install -e .注:该模型还支持Docker,因为不懂这种方式就没有做研究。需要的话得大家自己看看文档。
完成部署后,我们可通过以下两种方式使用F5-TTS。
使用
基本使用方式
F5 也提供了多种使用方式。
即可以拉起一个 web UI 界面
# Launch a Gradio app (web interface)f5-tts_infer-gradio# Specify the port/hostf5-tts_infer-gradio --port 7860 --host 0.0.0.0# Launch a share linkf5-tts_infer-gradio --share也可以在命令行中调用。
f5-tts_infer-cli --model F5TTS_v1_Base \--ref_audio "provide_prompt_wav_path_here.wav" \--ref_text "The content, subtitle or transcription of reference audio." \--gen_text "Some text you want TTS model generate for you."Web UI操作指南
启动
调用指令f5-tts_infer-gradio
等模型启动后,在浏览器中输入:http://127.0.0.1:7860/ 打开web页面,界面如下。
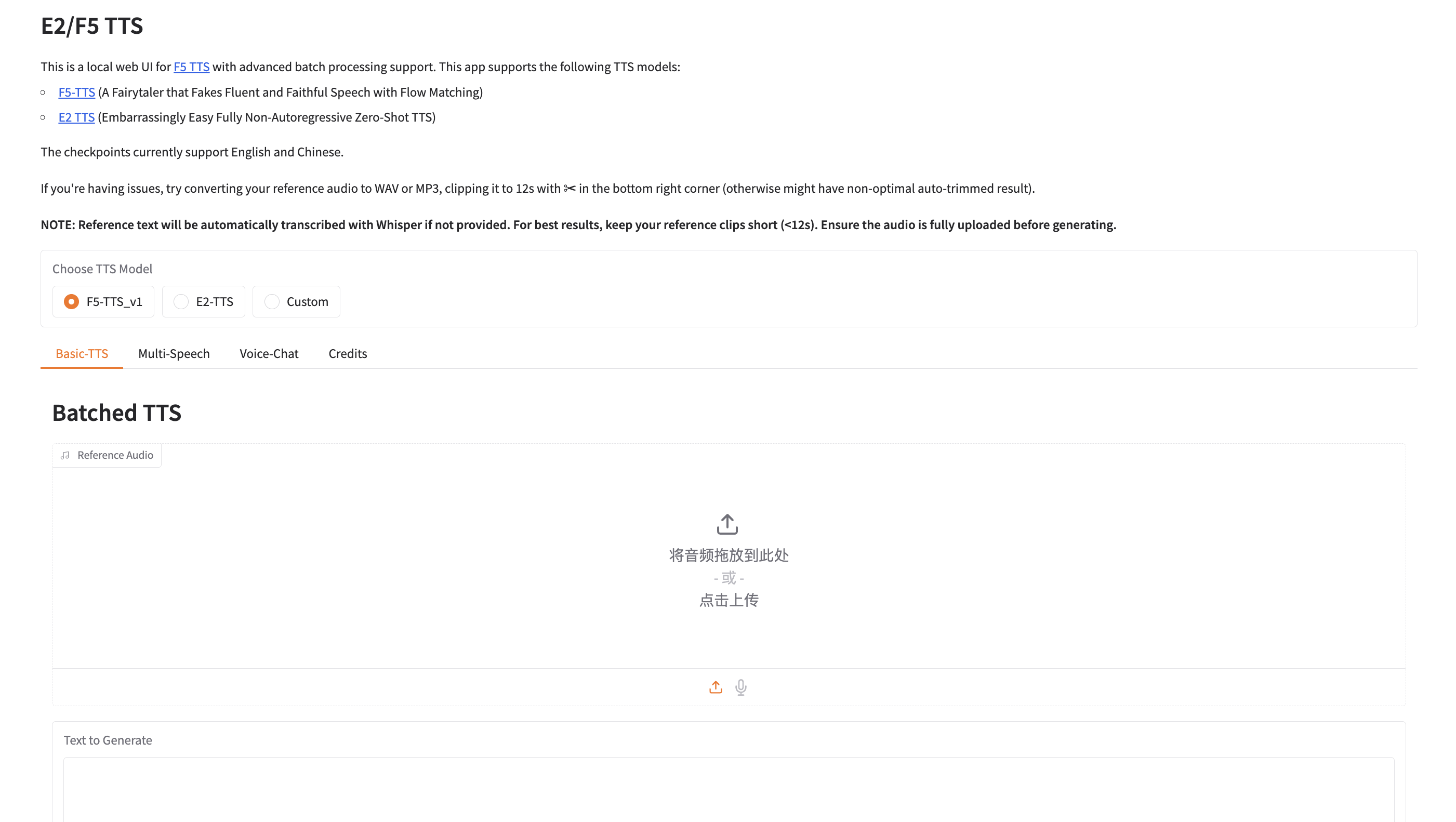
注:到这里会看见多了一个E2-TTS 模型,其实文档开头就介绍过:E2 TTS: Flat-UNet Transformer, closest reproduction from paper. 即它是基于论文复现的基线模型,采用 Flat-UNet + Transformer 架构。具体细节没怎么研究,瞎猜放这里是为了和 F5-TTS 做对比吧。
种子音频设置
在 Reference Audio 位置可以拖入生成好的音频文件,也可以点击录制按钮,现场录制一个。
开始生成音频文件
在 Text to Generate 部分输入想要转换的文本内容。然后找到Synthesize按钮,点击。就可以愉快的等待了。稍后我们需要的音频文件就会生成。
(速度上感觉要比 Spark TTS 稍微慢一点,因为它会做一些额外的操作。例如用户如果没有输入Reference text,它会自己检查并且生成。还会生成一个 Spectrogram 图。)
高级参数说明(Advanced Settings)
想要生成高质量的音频文件,首先要保证自己输入的种子音频文件的质量;其次就是一定要在Reference text 区域输入种子音频文件内容对应的文本。虽说不输入模型自己会解析和生成,但自动解析容易出现偏差。从而影响到最终的音频文件的质量。
Remove Silences(去除静音)
勾选生成长文本时,可以避免因模型倾向插入静音导致的冗余停顿。但会导致生成音频的时间加长。
Speed(语速调节)
就是生成的音频文件的语速。这个得按照自己的实际情况做调节。例如生成英文音频文件,那么语速调快一点,生成的音频听着就会感觉自然一点。因为英文的语速本身就会比中文快一些。
NFE Steps (去噪步数)
步数越多,生成音频文件的耗时越久,但是生成的音频文件的质量会更高。
Cross-Fade Duration (s)(交叉淡入淡出时长)
多段音频拼接时的交叉淡入淡出时长(秒),可以使过渡更平滑。
微调使用方式
因为要经常生成英语听力材料,每次打开 webUI 后配置,再生成非常费劲。因此基于模型提供的f5-tts_infer-cli 命令行使用入口做了二次封装。
封装代码,文件名为 txt_to_audio.py。放置在项目的 F5-TTS/src/f5_tts/infer/txt_to_audio.py 位置。具体代码如下:
#!/usr/bin/env python3import argparseimport pathlibimport subprocessimport sysimport os# 默认配置DEFAULT_REF_AUDIO = "seed/LJ025-0076.wav"DEFAULT_REF_TEXT = "Many animals of even complex structure which live parasitically within others are wholly devoid of an alimentary cavity."def generate_tts(input_txt, ref_audio=DEFAULT_REF_AUDIO, ref_text=DEFAULT_REF_TEXT): """ 生成TTS语音文件 """ input_path = pathlib.Path(input_txt) if not input_path.exists(): raise FileNotFoundError(f"输入文件不存在: {input_txt}") if not pathlib.Path(ref_audio).exists(): raise FileNotFoundError(f"参考音频文件不存在: {ref_audio}") # 输出目录设为输入文件的同级目录 output_dir = input_path.parent output_dir.mkdir(parents=True, exist_ok=True) # 读取文本文件内容 with open(input_path, 'r', encoding='utf-8') as f: gen_text = f.read().strip() # 构建输出文件名 output_file = f"{input_path.stem}.wav" # 构建命令 cmd = [ "f5-tts_infer-cli", "-m", "F5TTS_v1_Base", "-r", str(ref_audio), "-s", ref_text, "-t", gen_text, "-o", str(output_dir), "-w", output_file, "--remove_silence", "--speed", "1.0", "--nfe_step", "32", "--cross_fade_duration", "0.15" ] # 执行命令 subprocess.run(cmd, check=True)def main(): parser = argparse.ArgumentParser( description="文本转语音生成器", formatter_class=argparse.ArgumentDefaultsHelpFormatter ) parser.add_argument( "input_txt", help="输入的文本文件路径" ) parser.add_argument( "-r", "--ref_audio", default=DEFAULT_REF_AUDIO, help="参考音频文件路径" ) parser.add_argument( "-s", "--ref_text", default=DEFAULT_REF_TEXT, help="参考音频的文本内容" ) args = parser.parse_args() try: generate_tts( input_txt=args.input_txt, ref_audio=args.ref_audio, ref_text=args.ref_text ) except Exception as e: print(f"错误: {e}", file=sys.stderr) sys.exit(1)if __name__ == "__main__": main()种子音频文件配置
keithito.com/LJ-Speech-D… 我从这个网站找了无版权的音频文件来做种子音频,克隆它的声音。这里的文件质量还不错。
将文件下载后解压,防止在新建的 seed 目录下。如图所示:
配置入口
找到项目的 pyproject.toml 文件,增加一行:"f5-tts_txt_to_audio" = "f5_tts.infer.txt_to_audio:main"
[project.scripts]"f5-tts_infer-cli" = "f5_tts.infer.infer_cli:main""f5-tts_infer-gradio" = "f5_tts.infer.infer_gradio:main""f5-tts_finetune-cli" = "f5_tts.train.finetune_cli:main""f5-tts_finetune-gradio" = "f5_tts.train.finetune_gradio:main""f5-tts_txt_to_audio" = "f5_tts.infer.txt_to_audio:main"然后调用pip 做一下安装:
pip install -e .使用
后续在命令行里使用就会非常简单,打开 terminal:
先 cd进入到 F5-TTS 目录下
接着启用 conda —— conda activate f5-tts
准备好音频文件
例如要转换的英文文本为:There is no medicine like hope, no incentive so great, and no tonic so powerful as expectation of something tomorrow.
将这句话保存为一个 txt 文件,这里就命名为well-known_quote.txt。将文件放置在一个独立的目录下。
用新指令生成
命令行里输入f5-tts_txt_to_audio,然后拖入well-known_quote.txt。生成的指令如下所示,直接回车,就可以愉快的等待了。新生成的音频文件位于 txt 的同目录下,文件名一致,只是后缀为.wav 。
f5-tts_txt_to_audio /xxxx/well-known_quote.txt
小结
- F5-TTS 模型本身的稳定性不错;使用入口也更加多样化;文档更是详细;用来学习本地部署非常推荐。文生音频相对于文生图、文生视频来说技术上比较成熟一点。用 F5-tts生成听力材料只能算是小 case,其他文生音频模型还能生成有声书,花活非常多。具体选用哪种文生音频模型还得看自己的具体的应用场景。
