
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 丰富的 AI 工具库 -> 每日更新 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🎙️ "Siri要失业?月之暗面开源音频核弹:1300万小时训练+多模态混合架构,语音交互迎来iPhone时刻"
大家好,我是蚝油菜花。当同行还在为语音识别准确率挣扎时,这个国产模型已经让机器「听懂」人类的情感波动!你是否经历过这些AI耳背现场——
- 👉 会议录音转文字总把专业术语变成神秘代码👉 语音助手把愤怒投诉识别成"谢谢反馈"👉 想用AI生成有声书,结果机械朗读堪比恐怖片旁白...
今天拆解的 Kimi-Audio ,正在重定义声音智能!月之暗面这支「音频手术刀」:
- ✅ 混合感知架构:同时处理声学特征+语义标记,听懂弦外之音✅ 流式生成黑科技:分块解码实现实时响应,延迟直降80%✅ 十项全能选手:从语音转写到情感分析,一套模型全搞定
已有教育机构用它开发口语教练,客服系统靠它识别用户情绪——你的麦克风,准备好接入「AI读心术」了吗?
🚀 快速阅读
Kimi-Audio是月之暗面推出的开源音频基础模型。
- 功能:支持语音识别、情感分析、音频生成等10余种任务技术:采用混合输入架构与流匹配解码,训练数据达1300万小时
Kimi-Audio 是什么
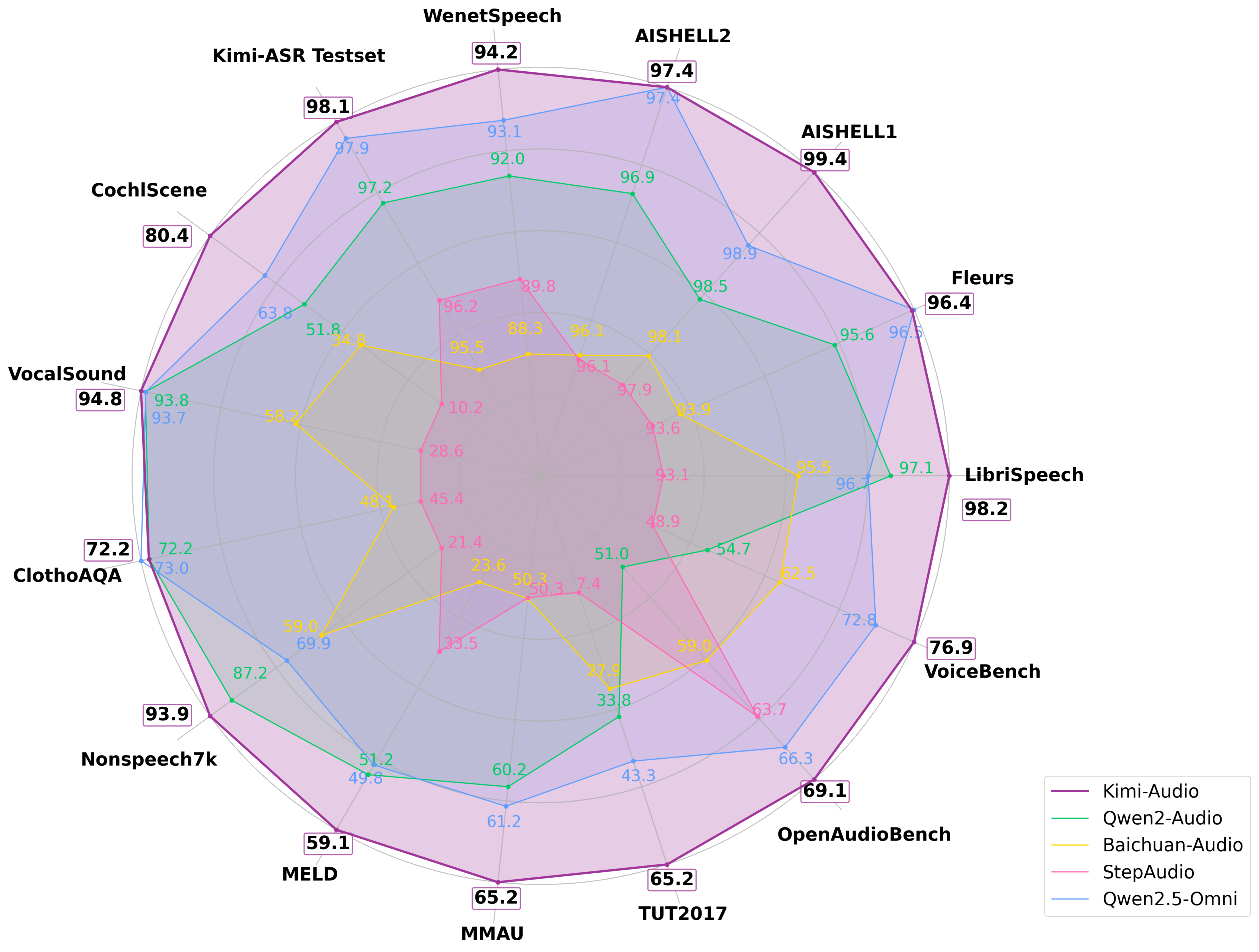
Kimi-Audio 是 Moonshot AI 推出的开源音频基础模型,专注于音频理解、生成和对话任务。在超过 1300 万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。
核心架构采用混合音频输入(连续声学 + 离散语义标记),结合基于 LLM 的设计,支持并行生成文本和音频标记,同时通过分块流式解码器实现低延迟音频生成。
Kimi-Audio 的主要功能
- 语音识别:能将语音信号转换为文本内容,支持多种语言和方言情感识别:分析语音中的情感信息,判断说话者的情绪状态场景分类:识别和分类环境声音或场景特征音频字幕:根据音频内容自动生成辅助字幕语音合成:将文本转换为自然流畅的语音输出多轮对话:处理复杂上下文并生成连贯语音回应
Kimi-Audio 的技术原理
- 混合输入架构:同时处理离散语义标记和Whisper编码的连续声学特征LLM核心:基于Qwen 2.5 7B模型初始化,支持并行生成能力流匹配解码:分块处理实现低延迟,支持前瞻机制优化流畅度BigVGAN声码器:确保生成波形的高保真度
如何运行 Kimi-Audio
获取代码
git clone https://github.com/MoonshotAI/Kimi-Audio.gitcd Kimi-Audiogit submodule update --init --recursivepip install -r requirements.txt快速入门
以下示例展示了基本的使用方法,包括从音频生成文本(ASR)以及在对话中生成文本和语音。
import soundfile as sffrom kimia_infer.api.kimia import KimiAudio# --- 1. 加载模型 ---model_path = "moonshotai/Kimi-Audio-7B-Instruct" model = KimiAudio(model_path=model_path, load_detokenizer=True)# --- 2. 定义采样参数 ---sampling_params = { "audio_temperature": 0.8, "audio_top_k": 10, "text_temperature": 0.0, "text_top_k": 5, "audio_repetition_penalty": 1.0, "audio_repetition_window_size": 64, "text_repetition_penalty": 1.0, "text_repetition_window_size": 16,}# --- 3. 示例 1: 音频到文本 (ASR) ---messages_asr = [ # 提供上下文或指令 {"role": "user", "message_type": "text", "content": "请转录以下音频:"}, # 提供音频文件路径 {"role": "user", "message_type": "audio", "content": "test_audios/asr_example.wav"}]# 仅生成文本输出_, text_output = model.generate(messages_asr, **sampling_params, output_type="text")print(">>> ASR 输出文本: ", text_output) # 预期输出: "这并不是告别,这是一个篇章的结束,也是新篇章的开始。"# --- 4. 示例 2: 音频到音频/文本对话 ---messages_conversation = [ # 用音频查询开始对话 {"role": "user", "message_type": "audio", "content": "test_audios/qa_example.wav"}]# 生成音频和文本输出wav_output, text_output = model.generate(messages_conversation, **sampling_params, output_type="both")# 保存生成的音频output_audio_path = "output_audio.wav"sf.write(output_audio_path, wav_output.detach().cpu().view(-1).numpy(), 24000) # 假设输出为 24kHzprint(f">>> 对话输出音频保存到: {output_audio_path}")print(">>> 对话输出文本: ", text_output) # 预期输出: "A."print("Kimi-Audio 推理示例完成。")资源
- GitHub 仓库:github.com/MoonshotAI/…
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 丰富的 AI 工具库 -> 每日更新 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦模型,1300万小时训练重塑语音交互
