
Published on April 30, 2025 10:22 AM GMT
This post gives a brief overview and some personal thoughts on a new ICLR workshop paper that I worked on together with Seamus..
TLDR:
- We developed a new method for automatically labeling features in neural networks using token-space gradient descentInstead of asking an LLM to generate hypotheses about what a feature means, we directly optimize the feature label itselfThe method successfully labeled features like "animal," "mammal," "Chinese," and "number" in our proof-of-concept experimentsCurrent limitations include single-token labels, issues with hierarchical categories, and computational costWe are not developing this method further, but if someone wants to pick up this research, we would be happy to assist
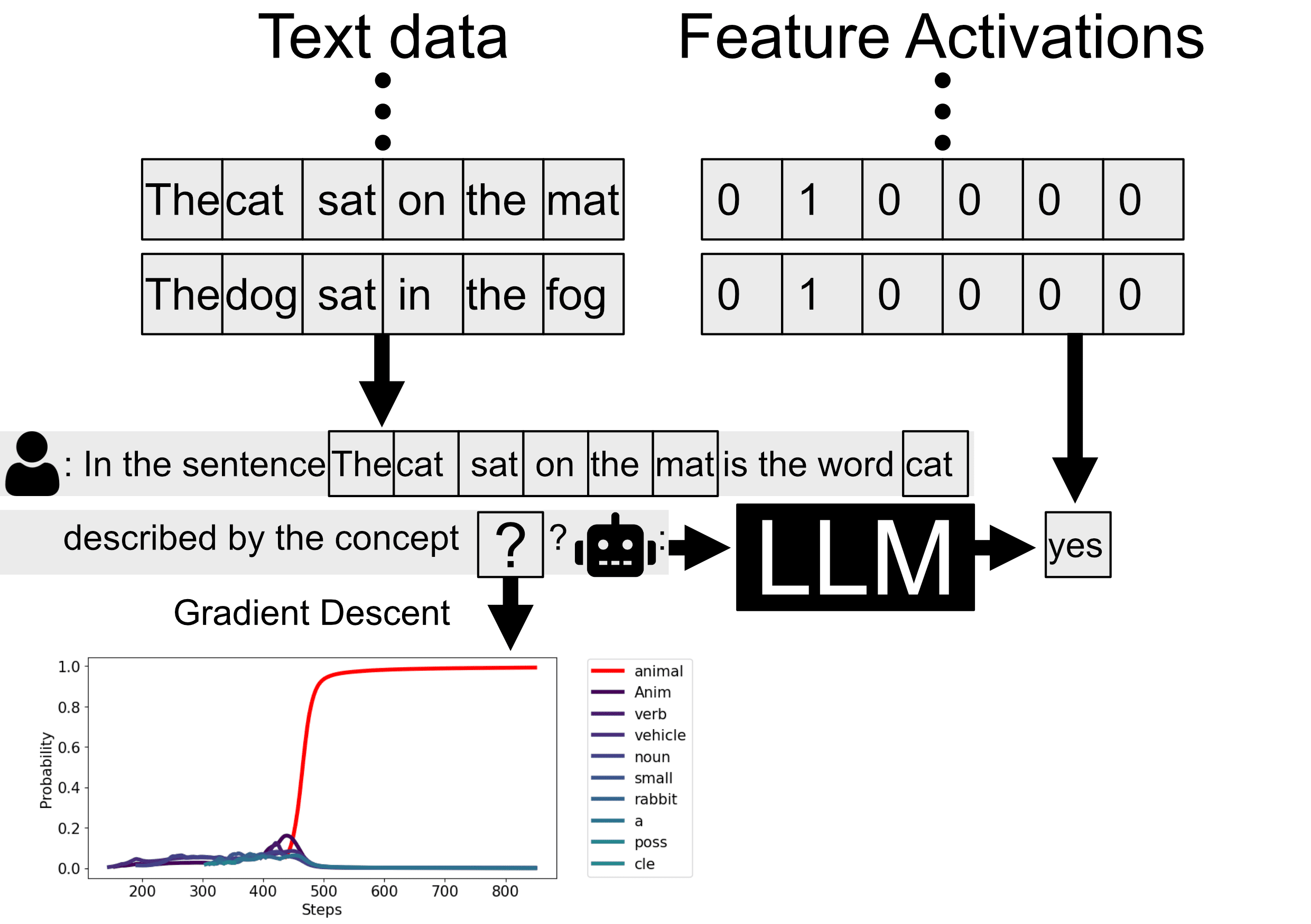
In this project, we developed a proof of concept for a novel way to automatically label features that directly optimizes the feature label using token-space gradient descent. We show its performance on several synthetic toy-features. We have discontinued developing this method because it didn't perform as well as we had hoped, and I'm now more excited about research in other directions.
Automated Feature Labeling
A central method for Mechanistic Interpretability is decomposing neural network activations into linear features via methods like Sparse Auto Encoders, Transcoders, or Crosscoders. While these decompositions give you somewhat human-understandable features, they don't provide an explanation of what these features actually mean. Because there are so many features in modern LLMs, we need some automatic way to find these descriptions. This is where automatic feature labeling methods come in.
Previous Methods
Previous methods for automated feature labeling work by finding text in which specific tokens activate the feature, and then prompting LLMs to come up with explanations for what the feature might mean to be activated in these situations. Once you get such a hypothesis, you can validate it by having an LLM predict when it thinks this feature should be active, and checking that against its actual activation. If these predictions don't match the actual activation, you can prompt an LLM again with the counterexamples and ask it to come up with new feature labels.
This process crucially depends on LLMs generating correct hypotheses for feature labels given the right data. This might be problematic because:
- Idea generation is actually hard. As we know from science, coming up with good ideas is harder than just checking whether an idea is correct.You might worry that the labeling LLM might sabotage your feature labeling method by not considering certain possibilities for feature labels.
So we developed a method where LLMs only do the rating—they only take a feature label and see what activations they would predict given this label—but the hypotheses themselves are generated via gradient descent.
Our method
Our method is fundamentally different from previous approaches. Instead of asking an LLM to generate hypotheses about what a feature means, we use the LLM as a discriminator to evaluate potential labels.
The key insight is that we can frame feature labeling as an optimization problem. A good feature label is one that allows accurate prediction of when a feature will activate. By using an LLM to assess whether a token matches a given feature description, we create a differentiable pipeline that enables gradient-based optimization of the label itself.
Here's how it works:
- We represent a potential feature label as a probability distribution over tokens.For each token in our dataset, we ask the LLM: "Is this token an example of [feature label]?"We compare the LLM's binary prediction to the actual feature activation.We use gradient descent to update our token probability distribution to minimize prediction error.
This process is visualized in the plot above. The LLM predicts whether each token matches the feature description, and we compare these predictions to actual feature activation (here we have a synthetic feature, that is always 0, except it is 1 for tokens describing animals). The bottom plot shows the optimization trajectory in token-space, where the probability mass concentrates on the token "animal" after several hundred steps.
Our loss function combines three components:
- Prediction accuracy: How well does the label predict actual feature activations?Entropy of the distribution over tokens: Needed to end up with a single label instead of an indecipherable superposition.KL-divergence: Is the label linguistically natural in the prompt context?
By optimizing these objectives simultaneously, we can find interpretable and accurate feature labels.
Results
We tested our method on several synthetic features and found that it successfully converged to meaningful single-token labels in many cases:
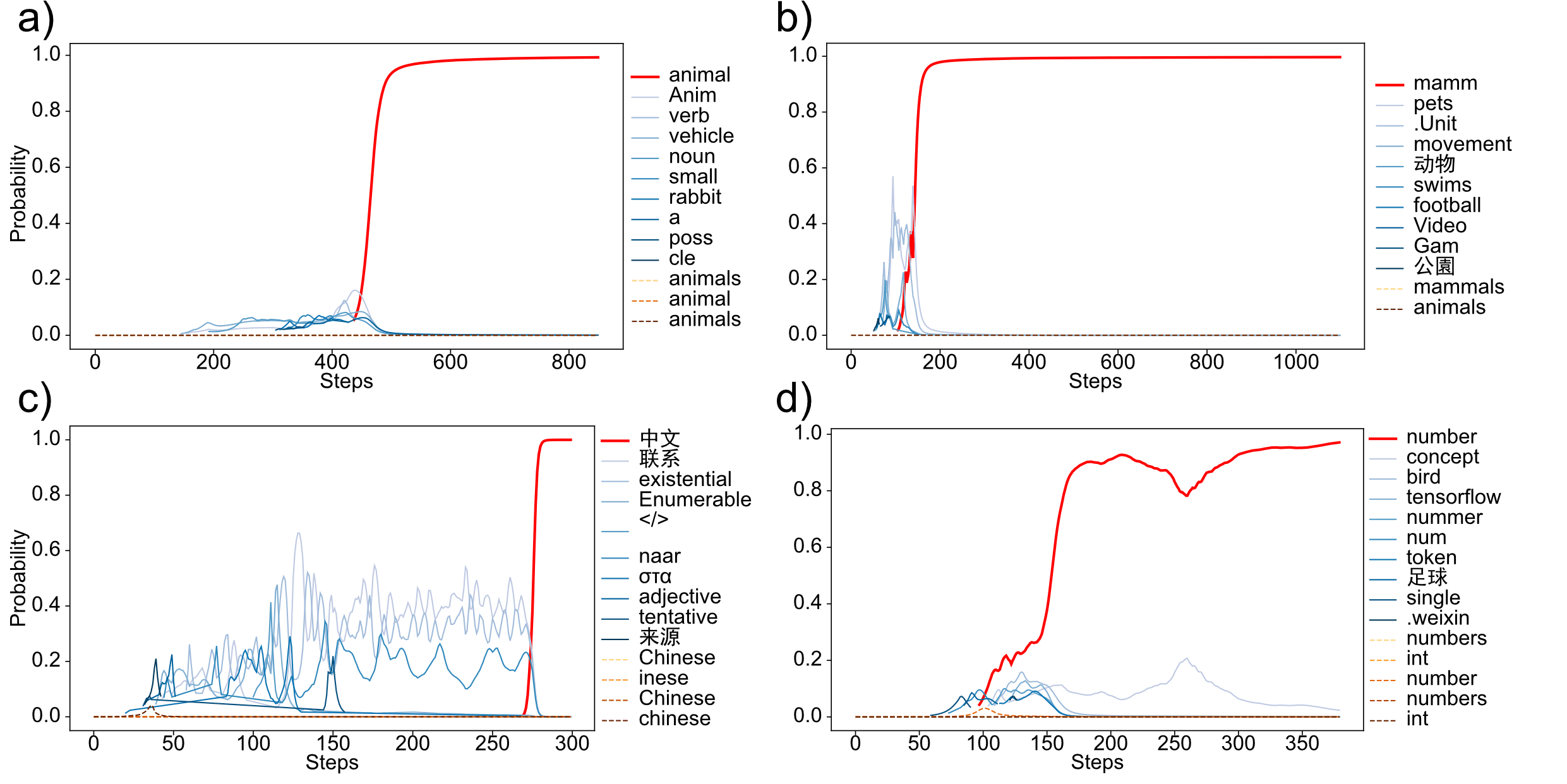
The optimization trajectories show how token probability distributions evolve during training for successfully labeled features:
- (a) Animal detection feature: converges to "animal"(b) Mammal-specific feature: converges to "mamm" when trained on a balanced dataset (equal mammal and non mammal animals)(c) Chinese text detection: converges to "中文" (meaning "Chinese")(d) Number detection: quickly converges to "number" for a feature active on both numerical digits and number words
However, we also encountered limitations and failure cases:
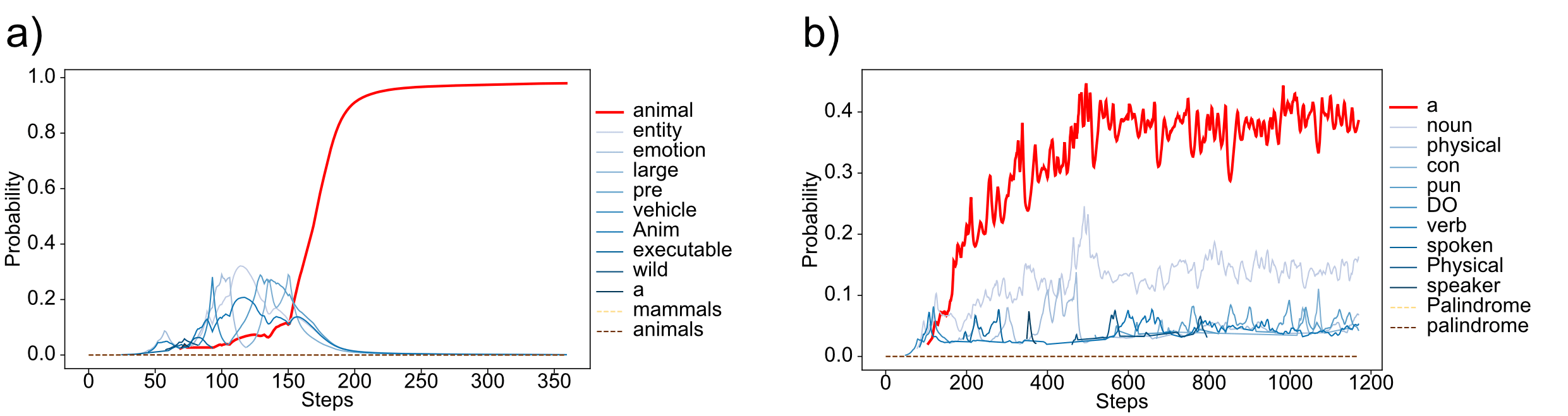
- When training on natural text without balanced sampling, the mammal detection optimization converged to the broader category "animal" instead of the intended mammal-specific label.For a palindrome detection feature, the optimization defaulted to the simple token "a" because the base model couldn't reliably classify palindromes even with the correct label.
Next Steps
Several limitations could be addressed in future work:
- Single-token labels: Currently, our method only optimizes for single tokens, which limits the complexity of concepts it can express. This could be improved by optimizing sequences of multiple tokens.Hierarchical categories: When insufficient examples of distinguishing cases are present, the method tends to default to broader categories. This could be addressed with more sophisticated sampling strategies.Model capability: If the evaluation model can't reliably classify instances of a feature even when given the correct label, our method will fail.Hyperparameter tuning: The method currently requires some human intervention to tune hyperparameters for different features.
It's pretty cool that this method works at all. We think more work in this direction could be exciting, particularly for safety-critical interpretability tasks where having an alternative to fully LLM-generated explanations might be valuable.
However, we're not super hyped about expanding the method ourselves because:
- It can be finicky about the hyperparameters under which it works, so it's not super robust yetThe rapid progress in LLM reasoning capabilities suggests that models are becoming better at all kinds of verifiable tasks, including "did you find a good feature label," which makes our method comparatively less promisingI am personally less excited at the moment about mechanistic interpretability in general, and am focusing on other research directions
If anyone is interested in working on this approach, our code is available at GitHub. We're happy to chat more about details, including prompts, datasets, and hyperparameters that can be found in the paper.
Discuss
