

基于 Transformer 的预训练语言模型 (PLM) 使用大量自然语言文本进行训练,极大地推动了自然语言处理 (NLP) 领域的快速发展。这些模型已以各种方式有效地用于各种下游任务,例如微调或小样本学习。值得注意的是,它们已经展示了有希望的性能,甚至在几个下游任务中超过了人类的能力。从这些出色的实验结果中,出现了一种普遍的看法,即 PLM 包含有关世界的广泛知识,并具有理解自然语言的能力。然而,许多调查已经描述了 PLM 在理解自然语言方面固有的不完美能力。通过跨不同谱系的实验,揭示了 PLM 在理解否定表达式和数字相关知识方面表现出缺陷。另一个研究途径确定 PLM 表现出逻辑上不正确的行为,这与人类表现出的行为大相径庭。这些谬误的行为引起了人们的极大关注,因为它们破坏了 PLM 的可信度,可能会阻碍它们在各行各业的应用,尤其是在风险敏感领域,如医疗、金融和法律领域。
在这种情况下,本论文将注意力集中在从一致性角度提高语言模型 (LM) 的可信度上。尽管已经进行了几次尝试,探索了 LM 的一致行为,并努力构建具有更高一致性的增强模型,但这些研究存在严重的缺点。 首先,多项研究对一致性的定义存在分歧,导致调查分散,阻碍了统一和全面评价的实现。不同的定义还导致了不全面的缓解方法,这些方法只关注某些类型的一致性,而无法解决其他一致性类型。其次,为改善一致性行为而提出的方法需要大量的资源分配。最广泛使用的技术是数据增强,它涉及收集符合指定一致性类型的附加数据,以及一致性正则化,其中引入了额外的训练损失函数,通过利用增强数据来惩罚不良行为。虽然可以实现自动收集补充数据以解决某些一致性类型,例如利用对称性属性,但这些策略中的大多数都需要充足的语言资源或大量的人力努力来确保高标准的数据质量。因此,对于资源有限的语言或在资源限制下工作的研究人员来说,这些缓解方法变得相对不太可行。此外,合并增强数据和辅助正则化项来更新 LM 的参数,在训练所需的计算资源方面提出了挑战。
由于 GPT-4 证明,当代 LM 的规模大幅增加,这一点尤其明显。本论文旨在解决上述先前研究关于 LM 一致行为的缺点。 首先,我根据行为一致性的概念提出了 LMs 一致性的全面定义,并提出了一个系统的分类,将先前研究中涉及的各种一致性类型分为三个独特的类别。其次,我介绍了一个统一的基准数据集,该数据集旨在促进全面评估,包括不同下游任务中的多种一致性类型。第三,我提出了一种实用且可行的方法来增强 LM 的一致性行为。具体来说,该方法有助于 LM 通过从字典数据中学习概念角色来捕捉语言的精确含义。随后,用概念角色信息增强的 LM 与现有的 LM 相结合,旨在充分利用获得的知识。这是通过以资源高效的方式进行参数集成来实现的,需要最少的计算资源。广泛的实验结果表明两个重要的发现。
最重要的是,对本论文的调查确定,无论其规模、架构设计和训练目标如何,现代 LM 在许多测试用例中都表现出不一致的行为,这以一致性类型和下游任务为特征。它们都没有在每个测试用例中表现出连贯一致的行为。随后的结果表明,所提出的缓解方法同时增强了多种一致性类型,这是以前的方法所缺乏的能力。此外,实验结果证明了所提出的方法减少了计算资源,并且它广泛适用于英语以外的低资源语言。

论文题目:Developing trustworthy language models with consistent predictions
作者:Jang, ME
类型:2024年博士论文
学校:University of Oxford(英国牛津大学)
下载链接:
链接: https://pan.baidu.com/s/1Hnlg4JrQTgE-xYey1M_e_g?pwd=a8g9
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5

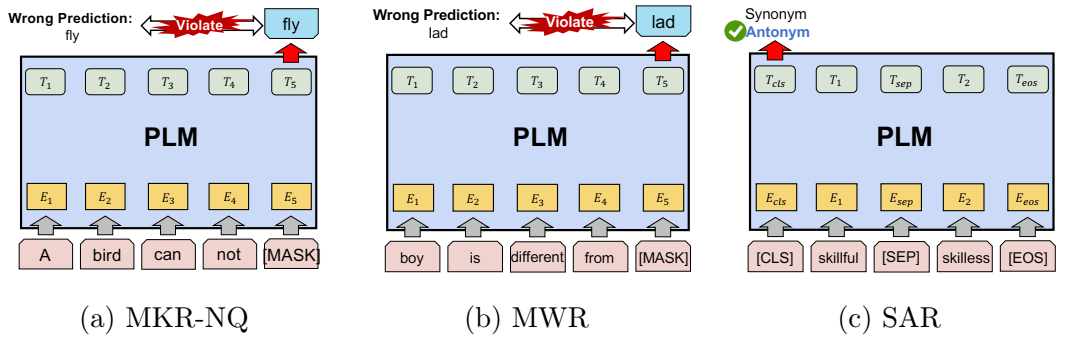
MKR-NQ、MWR 和 SAR 任务示意图。MKR-NQ 和 MWR 任务通过 MLM 生成单词,而 SAR 任务是二分类任务。
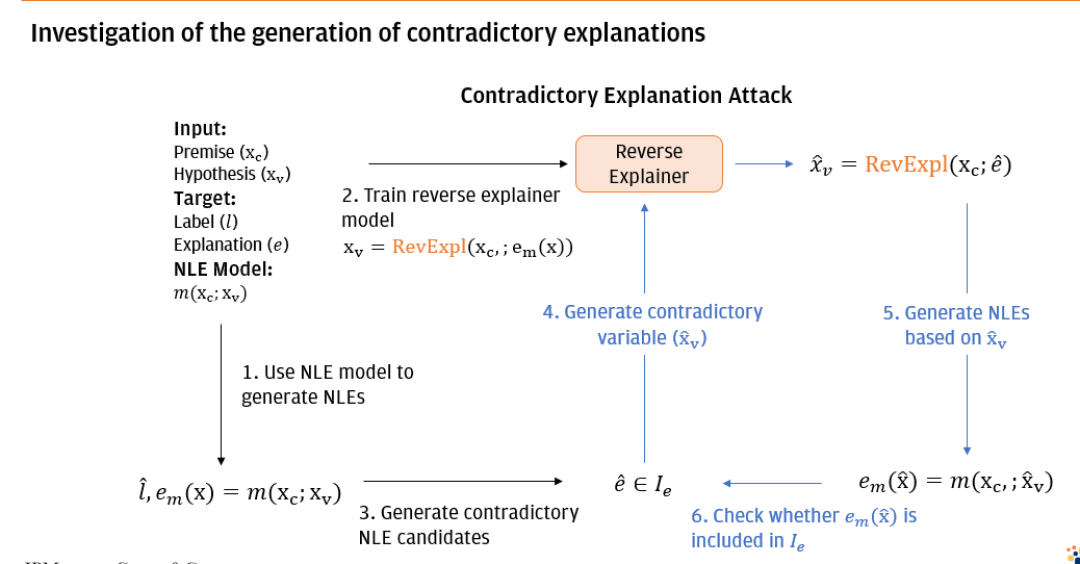
eCA方法的总体框架。
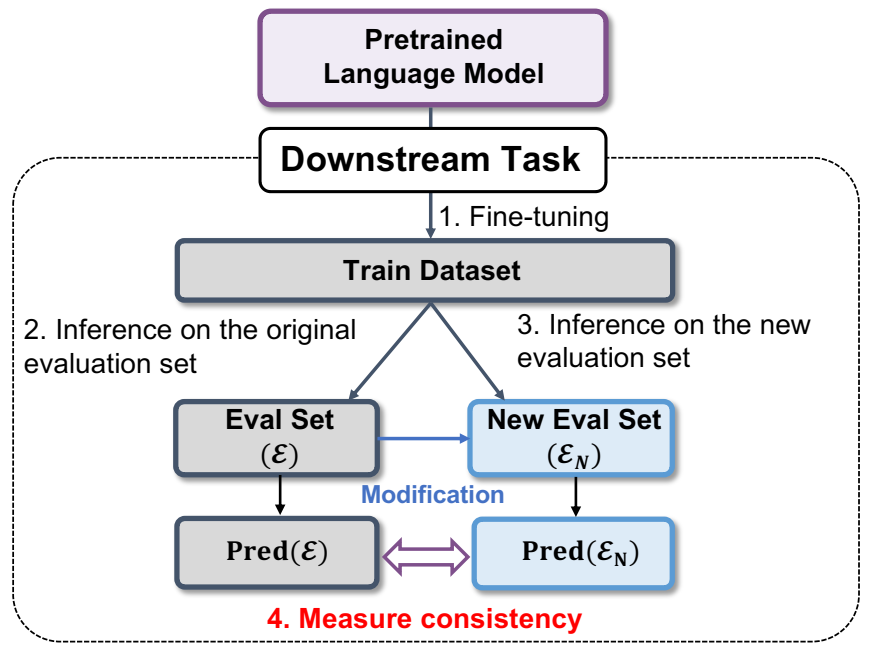
用于评估语言模型一致性的总体评估框架。比较仅针对模型的预测结果,而非与黄金标签。
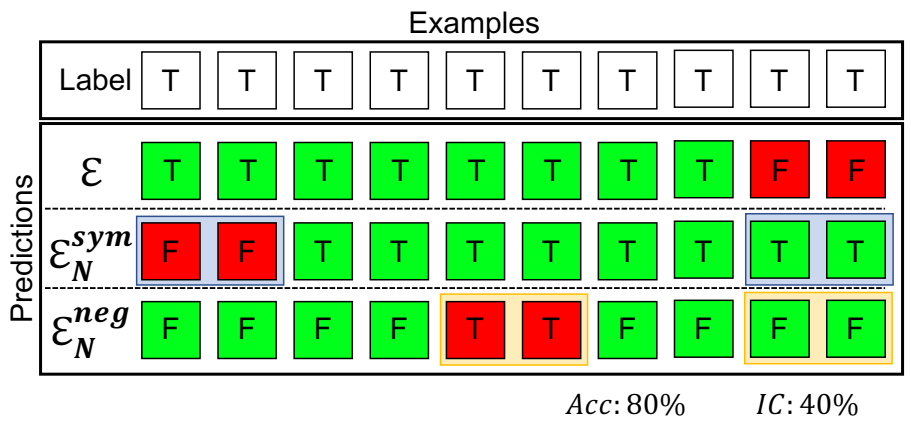
二元分类准确率、对称一致性和负一致性的图形表示。蓝色和黄色框分别表示不一致的对称一致性和负一致性情况。
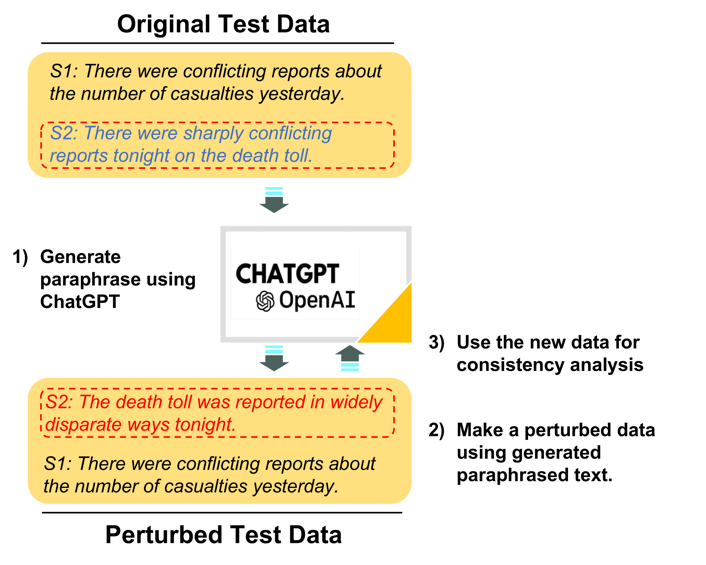
通过法学硕士自身生成的释义来测量自身语义一致性的总体流程。







内容中包含的图片若涉及版权问题,请及时与我们联系删除
