
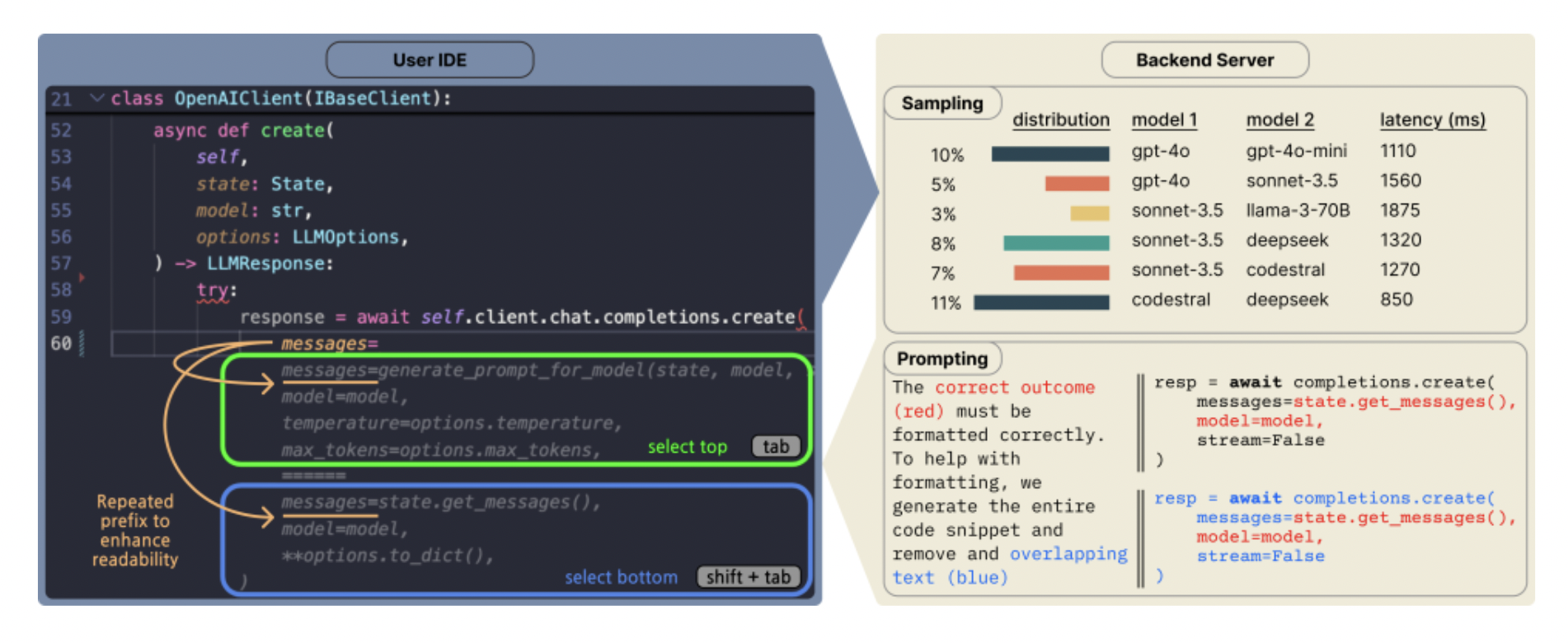
Figure 1. Copilot Arena is a VSCode extension that collects human preferences of code directly from developers.
By Wayne Chi, Valerie Chen, Chris Donahue, Ameet Talwalkar
As model capabilities improve, large language models (LLMs) are increasingly integrated into user environments and workflows. In particular, software developers code with LLM-powered tools in integrated development environments such as VS Code, IntelliJ, or Eclipse. While these tools are increasingly used in practice, current LLM evaluations struggle to capture how users interact with these tools in real environments, as they are often limited to short user studies, only consider simple programming tasks as opposed to real-world systems, or rely on web-based platforms removed from development environments.
To address these limitations, we introduce Copilot Arena, an app designed to evaluate LLMs in real-world settings by collecting preferences directly in a developer’s actual workflow. Copilot Arena is a Visual Studio Code extension that provides developers with code completions, akin to the type of support provided by GitHub Copilot. Thus far, over 11,000 users have downloaded Copilot Arena, and the tool has served over 100K completions, and accumulated over 25,000 code completion battles. The battles form a live leaderboard on the LMArena website. Since its launch, Copilot Arena has also been used to evaluate two new code completion models prior to their release: a new Codestral model from Mistral AI and Mercury Coder from InceptionAI.
In this blog post, we discuss how we designed and deployed Copilot Arena. We also highlight how Copilot Arena provides new insights into developer code preferences.
Copilot Arena system design
To collect user preferences, Copilot Arena presents a novel interface that shows users paired code completions from two different LLMs, which are determined based on a sampling strategy that mitigates latency while preserving coverage across model comparisons. Additionally, we devise a prompting scheme that allows a diverse set of models to perform code completions with high fidelity. Figure 1 overviews this workflow. We will overview each component below:
User Interface: Copilot Arena allows users to select between pairs of code completions from different LLMs. User selections allow us to better understand developer preferences between LLMs. To avoid interrupting user workflows, voting is designed to be seamless—users use keyboard shortcuts to quickly accept code completions.
Sampling model pairs: We explore a sampling strategy to minimize the experienced latency. Since our interface shows two code completions together, the slowest completion determines the latency. We capture each model’s latency as a log-normal distribution and tune a temperature parameter to interpolate between a latency-optimized distribution and a uniform distribution, observing a decrease in median experienced latency by 33% (from 1.61 to 1.07 seconds) compared to a uniform distribution.

Prompting for code completions: During development, models need to “fill in the middle”, where code needs to be generated based on both the current prefix and suffix. While some models, such as DeepSeek and Codestral, are designed to fill in the middle, many chat models are not and require additional prompting. To accomplish this, we allow the model to generate code snippets, which is a more natural format, and then post-process them into a FiM completion. Our approach is as follows: in addition to the same prompt templates above, the models are provided with instructions to begin by re-outputting a portion of the prefix and similarly end with a portion of the suffix. We then match portions of the output code in the input and delete the repeated code. This simple prompting trick allows chat models to perform code completions with high success (Figure 2).
Deployment

We deploy Copilot Arena as a free extension available on the VSCode extension store. During deployment, we log user judgments and latency for model responses, along with the user’s input and completion. Given the sensitive nature of programming, users can restrict our access to their data. Depending on privacy settings, we also collect the user’s code context and model responses.
As is standard in other work on pairwise preference evaluation (e.g., Chatbot Arena), we apply a Bradley-Terry (BT) model to estimate the relative strengths of each model. We bootstrap the battles in the BT calculation to construct a 95% confidence interval for the rankings, which are used to create a leaderboard that ranks all models, where each model’s rank is determined by which other models’ lower bounds fall below its upper bound. We host a live leadboard of model rankings at lmarena.ai (Figure 3).
Findings

Comparison to prior datasets
We compare our leaderboard to existing evaluations, which encompass both live preference leaderboards with human feedback and static benchmarks (Figure 4). The static benchmarks we compare against are LiveBench, BigCodeBench, and LiveCodeBench, which evaluate models’ code generation abilities on a variety of Python tasks and continue to be maintained with new model releases. We also compare to Chatbot Arena and their coding-specific subset, which are human preferences of chat responses collected through a web platform.
We find a low correlation (r ≤ 0.1) with most static benchmarks, but a relatively higher correlation (Spearman’s rank correlation (r) of 0.62) with Chatbot Arena (coding) and a similar correlation (r = 0.48) with Chatbot Arena (general). The stronger correlation with human preference evaluations compared to static benchmarks likely indicates that human feedback captures distinct aspects of model performance that static benchmarks fail to measure. We notice that smaller models tend to overperform (e.g., GPT-4o mini and Qwen-2.5-Coder 32B), particularly in static benchmarks. We attribute these differences to the unique distribution of data and tasks that Copilot Arena evaluates over, which we explore in more detail next.

In comparison to prior approaches, evaluating models in real user workflows leads to a diverse data distribution in terms of programming and natural languages, tasks, and code structures (Figure 5):
- Programming and natural language: While the plurality of Copilot Arena users write in English (36%) and Python (49%), we also identify 24 different natural languages and 103 programming languages which is comparable to Chatbot Arena (general) and benchmarks focused on multilingual generation. In contrast, static benchmarks tend to focus on questions written solely in Python and English.Downstream tasks: Existing benchmarks tend to source problems from coding competitions, handwritten programming challenges, or from a curated set of GitHub repositories. In contrast, Copilot Arena users are working on a diverse set of realistic tasks, including but not limited to frontend components, backend logic, and ML pipelines.Code structures and context lengths: Most coding benchmarks follow specific structures, which means that most benchmarks have relatively short context lengths. Similarly, Chatbot Arena focuses on natural language input collected from chat conversations, with many prompts not including any code context (e.g., 40% of Chatbot Arena’s coding tasks contain code context and only 2.6% focus on infilling). Unlike any existing evaluation, Copilot Arena is structurally diverse with significantly longer inputs.
Insights into user preferences
- Downstream tasks significantly affect win rate, while programming languages have little effect: Changing task type significantly affects relative model performance, which may indicate that certain models are overexposed to competition-style algorithmic coding problems. On the other hand, the effect of the programming language on win-rates was remarkably small, meaning that models that perform well on Python will likely perform well on another language. We hypothesize that this is because of the inherent similarities between programming languages, and learning one improves performance in another, aligning with trends reported in prior work.Smaller models may overfit to data similar to static benchmarks, while the performance of larger models is mixed: Existing benchmarks (e.g., those in Figure 4) primarily evaluate models on Python algorithmic problems with short context. However, we notice that Qwen-2.5 Coder performs noticeably worse on frontend/backend tasks, longer contexts, and non-Python settings. We observe similar trends for the two other small models (Gemini Flash and GPT-4o mini). We hypothesize that overexposure may be particularly problematic for smaller models. On the other hand, performance amongst larger models is mixed.
Conclusion
While Copilot Arena represents a shift in the right direction for LLM evaluation, providing more grounded and realistic evaluations, there is still significant work to be done to fully represent all developer workflows. For example, extending Copilot Arena to account for interface differences from production tools like GitHub Copilot and tackling privacy considerations that limit data sharing. Despite these constraints, our platform reveals that evaluating coding LLMs in realistic environments yields rankings significantly different from static benchmarks or chat-based evaluations and highlights the importance of testing AI assistants with real users on real tasks. We’ve open-sourced Copilot Arena to encourage the open source community to include more nuanced feedback mechanisms, code trajectory metrics, and additional interaction modes.
If you think this blog post is useful for your work, please consider citing it.
@misc{chi2025copilotarenaplatformcode,
title={Copilot Arena: A Platform for Code LLM Evaluation in the Wild},
author={Wayne Chi and Valerie Chen and Anastasios Nikolas Angelopoulos and Wei-Lin Chiang and Aditya Mittal and Naman Jain and Tianjun Zhang and Ion Stoica and Chris Donahue and Ameet Talwalkar},
year={2025},
eprint={2502.09328},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2502.09328},
}This article was initially published on the ML@CMU blog and appears here with the author’s permission.
