
Published on July 3, 2024 7:06 PM GMT
Tl;dr, While an algorithm's computational complexity may be exponential in general (worst-case), it is often possible to stratify its input via some dimension that makes it polynomial for a fixed , and only exponential in . Conceptually, this quantity captures the core aspect of a problem's structure that determines what makes specific instances more difficult than others, often with intuitive interpretations.
Example: Bayesian Inference and Treewidth
One can easily prove exact inference (decision problem of: "is ?") is NP-hard by encoding SAT-3 as a Bayes Net. Showing that it's NP is easy too.
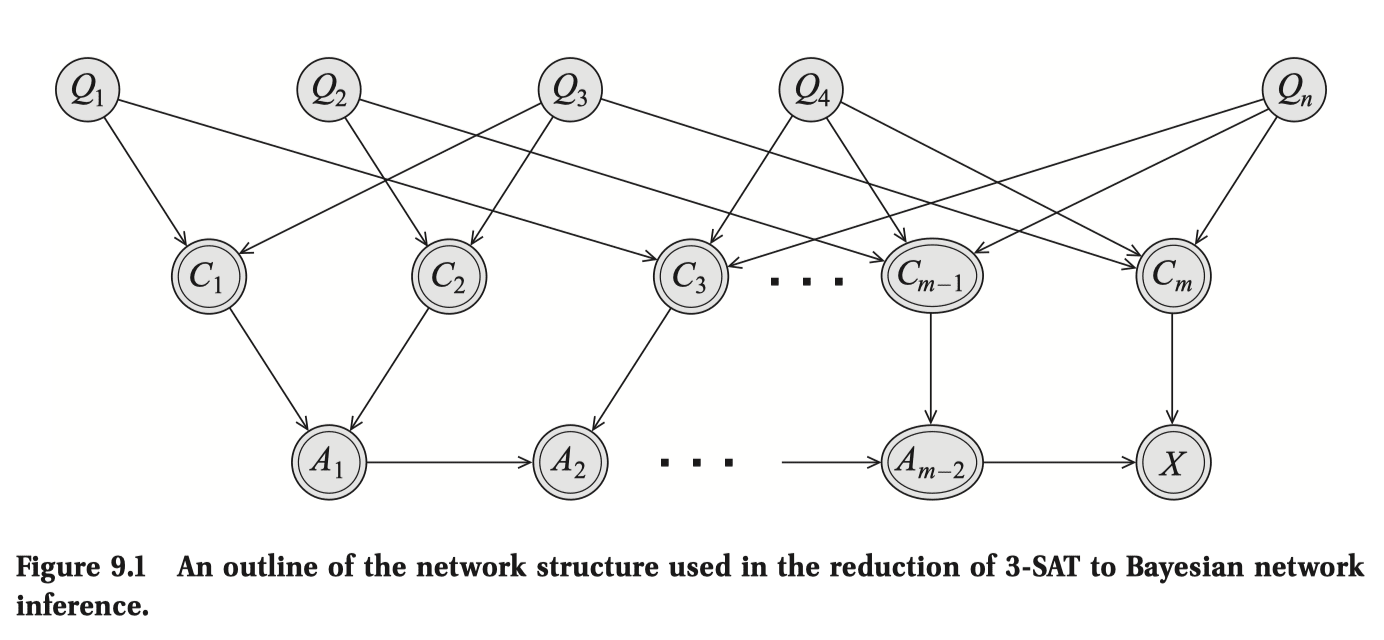
Therefore, inference is NP-complete, implying that algorithms are worst-case exponential. But this can't be the typical case! Let's examine the example of a Bayes Net whose structure is a chain and say you want to compute the marginals .
The Naive Algorithm for marginalization would be to literally multiply all the conditional probability distribution (CPD) tables for each of the Bayes Net's nodes, and sum over all the variables other than . If we assume each variable has at most values, then the computational complexity is exponential in the number of variables .
- , which is .
But because of the factorization due to the chain structure, we can shift the order of the sum around like this:
and now the sum can be done in . Why?
- Notice is , and to compute we need to multiply times and sum times, overall .This needs to be done for every , so . Now we have cached , and we move on to , where the same analysis applies. This is basically dynamic programming.
So, at least for chains, inference can be done in linear time in input size.
The earlier NP-completeness result, remember, is a worst-case analysis that applies to all possible Bayes Nets, ignoring the possible structure in each instance that may make some easier to solve than the other.
Let's attempt a more fine complexity analysis by taking into account the structure of the Bayes Net provided, based on the chain example.
Intuitively, the relevant structure of the Bayes Net that determines the difficulty of marginalization is the 'degree of interaction' among the variables, since the complexity is exponential in the "maximum number of factors ever seen within a sum," which was 2 in the case of a chain.
How do we generalize this quantity to graphs other than chains?
Since we could've shuffled the order of the sums and products differently (which would still yield for chains, but for general graphs the exponent may change significantly), for a given graph we want to find the sum-shuffling-order that minimizes the number of factors ever seen within a sum, and call that number , an invariant of the graph that captures the difficulty of inference — [1]
This is a graphical quantity of your graph called treewidth[2][3].
So, to sum up:
- We've parameterized the possible input Bayes Nets using some quantity .Where stratifies the inference problem in terms of their inherent difficulty, i.e. computational complexity is exponential in , but linear under fixed or bounded .We see that is actually a graphical quantity known as treewidth, which intuitively corresponds to the notion of 'degree of interaction' among variables.
General Lesson
While I was studying basic computational complexity theory, I found myself skeptical of the value of various complexity classes, especially due to the classes being too coarse and not particularly exploiting the structures specific to the problem instance:
- The motif of proving NP-hardness by finding a clever way to encode SAT-3 is a typical example of problem-structure-flattening that I'm troubled by.
But while studying graphical models, I learned that, there are many more avenues of fine-grained complexity analyses (after the initial coarse classification) that may lend real insight to the problem's structure, such as parameterized complexity.
While many algorithms (e.g., those for NP-complete problems) are exponential (or more generally, superpolynomial) in input size in general (worst-case), there are natural problems whose input can be stratified via a parameter - whose algorithms are polynomial in input size given a fixed , and only exponential in .
This is exciting from a conceptual perspective, because then describes exactly what about the problem structure makes some instance of it harder or easier to solve, often with intuitive meanings - like treewidth!
Also, I suspect this may shed light on to what makes some NP-hardness results not really matter much in practice[4] - they don't matter because natural instances of the problem have low values of . From this, one may conjecture that nature has low treewidth, thus agents like us can thrive and do Bayes.
- ^
is the number of times the sum was performed. In the case of chains, this was simply , thus . I omitted m because it seemed like an irrelevant detail for conveying the overall lesson.
- ^
A graphical quantity of your undirected graph by turning all the directed edges of the Bayes Net to undirected ones.
- ^
Actually, is treewidth. Trees (which chains are an example of) have a treewidth of 1, thus .
- ^
Among many other reasons also laid out in the link, such as use of approximations, randomization, and caring more about average / generic case complexity. My point may be considered an elaboration of the latter reason.
Discuss
