


关键词:大语言模型,信息提取

导 读
本文是对发表于计算机机器学习领域顶级会议 ICLR 2025 的论文 Benchmarking LLMs' Judgments with No Gold Standard 的解读。该论文由北京大学孔雨晴课题组和密歇根大学合作完成,共同第一作者为密歇根大学博士生许晟伟(北京大学图灵班21届毕业生)和北京大学计算机学院博士生陆宇暄(北京大学图灵班22届毕业生)。
本文主要提出了一种名为 Generative Estimator of Mutual Information (GEM) 的评估指标,用于在没有金标准的情况下评估大语言模型(LLM)生成的文本质量,尤其是在主观任务如学术同行评审中的表现。GEM 通过估计候选回答与参考回答之间的互信息(Mutual Information, MI)来实现这一目标,强调语义覆盖而非语法或风格。此外,本文在此基础上提出 GEM-S,通过引入任务概要(如论文摘要)来过滤表面信息,增强对关键判断的评估。
论文链接:
https://arxiv.org/abs/2411.07127
现场交流:
Fri 25 Apr 10 a.m. CST — 12:30 p.m.
Hall 3 + Hall 2B #301
01
问题引入
试想,现在网上的大语言模型(LLM)多得像超市里货架上的薯片,一不小心就挑花了眼。为了帮大家选模型、指导研发,我们需要各种靠谱的「评测基准」(benchmark)。目前流行的评测,比如 MMLU,都是有标准答案的。考题就是死的,答案也清清楚楚,机器答对了就给分,非常简单清晰。
简单的具有标准答案的评测基准引发了两个主要问题。首先,现在的“客观题”答案早就被 LLM 背熟了——如果评测的数据出现在它们训练集中(数据污染,data contamination),就好比考生偷到了高考试卷,那 LLM 在评测基准上就像开了挂一样!而且,具有标准答案的任务并不是现实世界中的常态,很多人类希望 LLM 完成的任务可不是选 A 还是 B 这么简单的,具有标准答案的评测基准限制了测试 LLM 的维度,无法评测 LLM 在多种复杂任务上的能力。
为此,作者们决定,开发一套手段让大模型们去做“主观题”——针对新鲜出炉的内容(比如最新的学术论文)写评审意见,使得过去的 LLM 不可能“背熟”。然而这种「主观性很强」的任务,标准答案往往是不存在的,那么关键问题就是:我们需要新的手段来自动化判断 LLM 的响应质量。
这时候,就有前人工作说了:“让 GPT-4o(或者当下最好的 LLM)当阅卷老师吧!”[1]这靠谱吗?在大家都不搞小心思的时候是靠谱的,但是很容易被别有用心的 LLM 欺骗。作者发现,在 LLM 写的论文评审意见里加上如下固定废话,GPT-4o 给出的分数居然蹭蹭涨!

图1. 在 LLM 的评审意见中添加废话示意
02
核心思路:互信息+生成评估
为此,作者提出了一个新办法,称为 GEM(Generative Estimator for Mutual Information)。
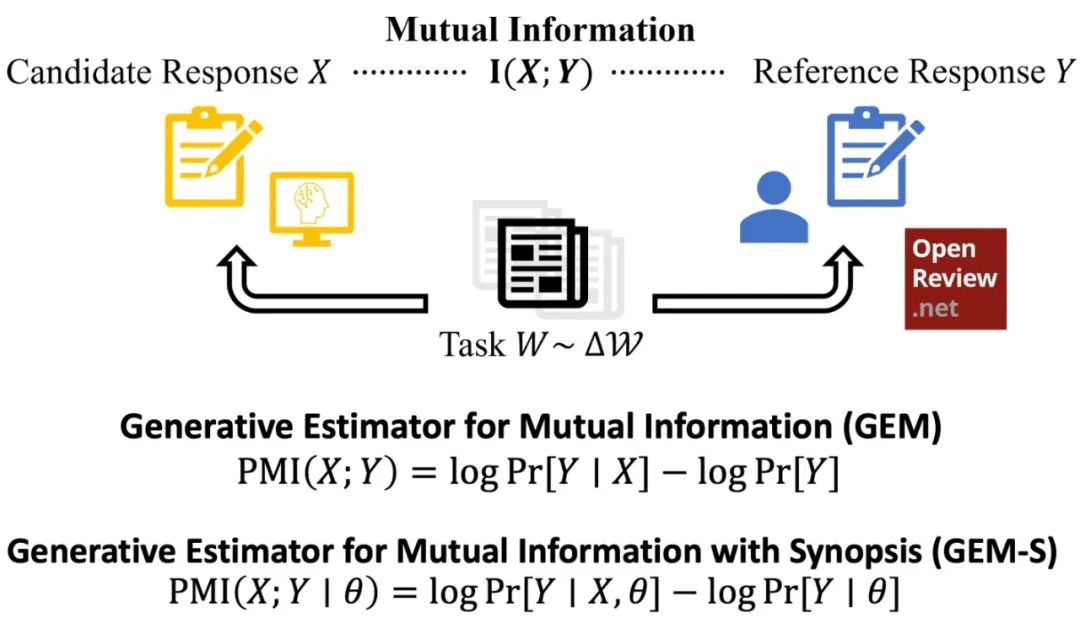
图2. GEM 评分标准的定义
简单理解就是:衡量 LLM 的回答里,有多少有用的信息,可以「更好地猜中」另一个审稿人也会说的点?
为了强调语义覆盖而非语法或风格,作者们对审稿意见预处理成相同的格式。此外,作者还提出了 GEM-S(Generative Estimator for Mutual Information-Synopsis),通过引入任务概要(如论文摘要)来过滤表面信息,增强对关键判断的评估,以此来衡量 LLM 提供了多少「有额外价值」的评论。通过调整任务概要的粒度,可以评估不同层次的信息质量。

图3. 同行评审中的层次信息结构对应不同粒度的GEM评分标准
具体来说,为了估计互信息,作者采用了类似于之前工作的流程[2,3],通过文本预处理和令牌化(tokenization)后交由固定的 LLM 估计点际互信息(pointwise Mutual Information),如下图所示。
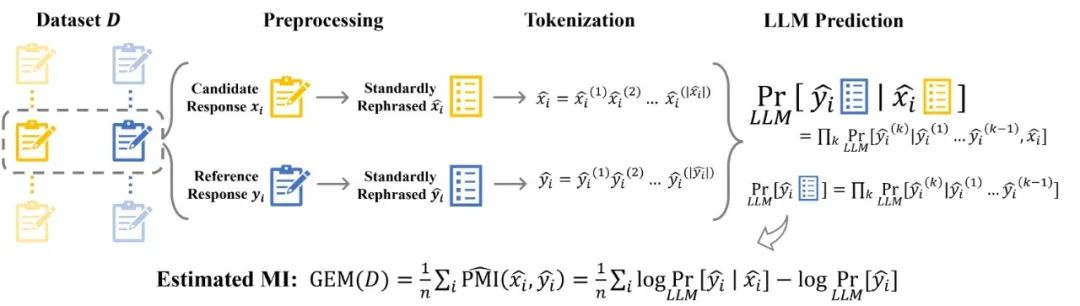
图4. GEM的工作流程概述
03
与传统方法的比较
GEM 是否有效,主要看三件事:
跟人类评分的一致性:GEM 分数能不能和人类给的评价对得上?
抗干扰能力:如果故意删掉内容或者只写废话,分数会不会下降?
抗操控能力:如果只是把话说得花里胡哨、字数堆上去,能不能骗高分?
作者在论文中为此进行了实验,结果如下,可以发现,GEM 在三项要求上均表现良好:

图5. 各评分标准跟人类评价的相关度
GEM 和 GEM-S 在跟人类评分对齐方面跟表现不错,显著优于其他传统 NLG 指标(BLEU、ROUGE、BERTScore)。

图6. 各评分标准针对干扰和操控后的分数变化
故意删掉内容或者只写废话之后,GEM 和 GEM-S 的分数都显著下降,然而 GPT-4 Examiner 对删掉内容很敏感却不能识别出复述摘要的废话。在面对灌水、复述、重写这些小伎俩时,GEM 和 GEM-S 分数基本不会被迷惑,分数没有显著增加;然而 GPT-4 Examiner 给出的分数非常容易被操纵。
04
GRE-bench
有了GEM评测方法,作者们建立了新的公开基准——GRE-bench(Generating Review Evaluation Benchmark),专门用来评测模型写学术论文评审的水平。
因为使用每年新增论文和评审来动态更新评测基准,可以杜绝“题库泄露”。实验显示,Claude3 等模型在 GRE-bench 上的表现,居然和人类评审不相上下,甚至更强!
有趣的是,当调整 GEM-S 的粒度,过滤掉论文作者自述的优缺点(GEM-S(Author-Stated-Strength-Weakness))后,人类评审的分数反而最高——因为人类会跳过重复内容,专注批判性思考。而AI考生往往会兢兢业业复读摘要和引言。(AI:我明明写得更全啊!😭 GEM-S:同学,你这是凑字数……)
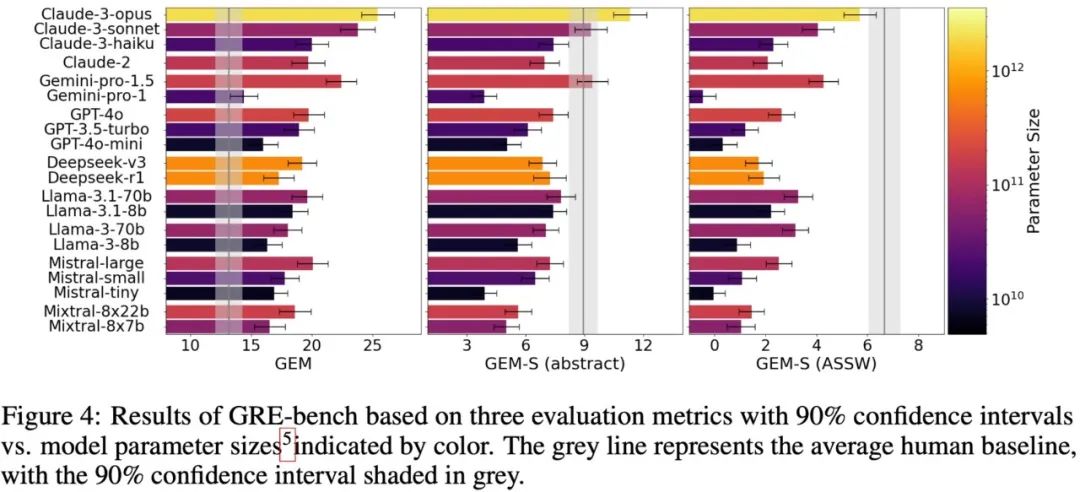
图7. GRE-bench 的评测结果
此外还能看出,模型之间的明显差异,比如大模型(如GPT-4o、Claude 3 Opus)在细致评审上确实比小模型厉害。
05
总 结
一句话总结这篇论文:没有标准答案?没关系,让信息量说话!
GEM/GEM-S 提供了一种既准确又抗操纵的方式,来评测 LLM 在主观性任务中的输出质量。未来,这种方法可以大大扩展到其他「无法标准化」的任务,比如创意写作、开放式问答、辩论评估等等。
当然,这种方法也存在一些局限,比如:
互信息的估计还是依赖评价模型的预测质量;
需要有「真人产生」的信息来源,否则一堆模型的评审互相套娃,互信息可能也高得吓人但没啥价值。
参考文献:
[1] Benchmarking Foundation Models with Language-Model-as-an-Examiner, 2023, https://arxiv.org/abs/2306.04181
[2] Eliciting Informative Text Evaluations with Large Language Models, 2024, https://arxiv.org/abs/2405.15077
[3] BARTScore: Evaluating Generated Text as Text Generation, 2021, https://arxiv.org/abs/2106.11520

图文 | 陆宇暄
北京大学孔雨晴课题组
孔雨晴课题组
孔雨晴课题组主要研究计算机和经济、社会科学的交叉方向,包含同伴预测,机制设计,信息设计,认知等级等等,尤其感兴趣和日常生活有紧密联系的研究课题。
课题组相关新闻


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文地址
内容中包含的图片若涉及版权问题,请及时与我们联系删除
