
Published on April 24, 2025 4:03 PM GMT
I recently did a weekend research sprint investigating error-detection behaviour in DeepSeek R1 models and writing up preliminary findings. I think I found some cool stuff on how the model tracks its mistakes, and wanted to share the rough write-up in case it's of interest to anyone
Intro
I think I find strong evidence that error-detection behaviour in is mediated by a linear feature in the model’s residual stream. I isolate this direction using a synthetic dataset, and show that intervening just along this direction can cause models to self-correct in the presence of no mistakes, as well as completely ignore mistakes. I also show that this feature seems to be active immediately on the token corresponding to the mistake.
Maybe most interestingly, this feature often fires on errors even when the CoT does not correct/acknowledge the error, suggesting that in some sense the model "knows" it's made a mistake even if its CoT doesn't reflect it.
Motivation
Using RL on model CoTs has been incredibly effective, and “reasoning models” seem to be the new paradigm for model scaling. One really cool phenomenon is that by rewarding these models solely on correctness, they learn sophisticated reasoning behaviour, such as the ability to notice when they’ve made a mistake/are missing something (The “Aha” moment from the DeepSeek R1 paper).
I wanted to spend a bit of time investigating this "error-detection" behaviour. In particular, I was curious if I could find some kind of (ideally linear) “error-detection feature”, which triggered models to notice mistakes/self-correct. Part of why I wanted to do this was that my confidence in a really strong form of the Linear Representation Hypothesis has waned lately, and this seemed like the kind of representation that would be very plausibly some incredibly messy, high-dimensional thing. I worked with DeepSeek-R1-Distill-Qwen-7B, which seemed like a sweet-spot in terms of trade-off between compute-cost of experiments and performance.
The effectiveness of CoT monitoring for safety applications seems tenuous, given evidence of CoT unfaithfulness, and especially given evidence that optimizing CoTs against unwanted behaviour seems to often just obfuscate the behaviour. Finding and understanding important features in the model activations seems important step for getting more robust monitoring.
Dataset
The idea was to look at clean/corrupted pairs of CoTs, where the only difference is the presence or absence of a mistake in the previous reasoning step. I focused on the MATH dataset, with clean/corrupted pairs generated as follows:
1. Generate CoTs on MATH dataset problems
2. For each CoT, truncate at a natural break-point (period, line-break etc) about half-way through the full CoT
3. Return the truncated CoT as-is (clean), and the truncated CoT with an arbitrary numerical change at the last instance of a number, to induce an error (corrupted)
Since these truncated CoTs end at a break-point and a new reasoning step is about to start, the metric of interest is the difference in logits for a range of tokens corresponding to the start of error-correction behaviour (“ Wait”, “ But”, “ Actually” etc.), measured at the final token position. The above data-generating process is hacky, and there are a number of failure-modes in which clean/corrupted pairs do not result in significantly different logits. I generated a total of ~49,000 clean/corrupted pairs, filtering for those with an average logit-diff > 3[1], which left ~21,000 (44%).
Example pair (Throughout this write-up I’m omitting the boilerplate templating needed to prompt these models correctly):
Clean

Corrupted

Analysis
I did a very generic residual stream activation-patching sweep over layers to find which were causally relevant. Patching corrupted -> clean and looking at the fraction of logit-diff recaptured, we see that the full process of catching mistakes is distributed across many layers, and isn’t fully completed until the final layer.
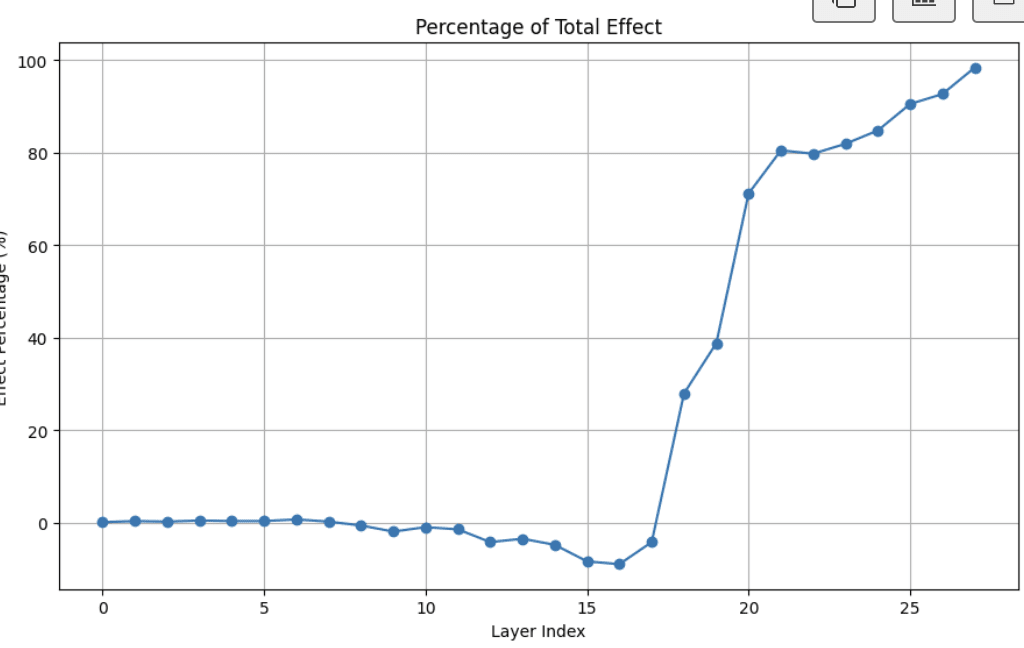
Fig 1: Fraction of logit-diff recovered by activation patching corrupted -> clean residual stream
However, most of the difference is captured by patching at layer_20, with what looks like “refinement” over subsequent layers. For the purposes of this sprint, I decided to focus in on layer_20, and first wanted to check if I could find a linear direction which seemed causally relevant.
Again trying the simplest thing first, I computed the difference in means between the clean_residuals and corrupted_residuals at layer_20. Looking at the fraction of logit_diff explained by solely patching the projection along this direction (corrupted -> clean), we see most of the difference recaptured
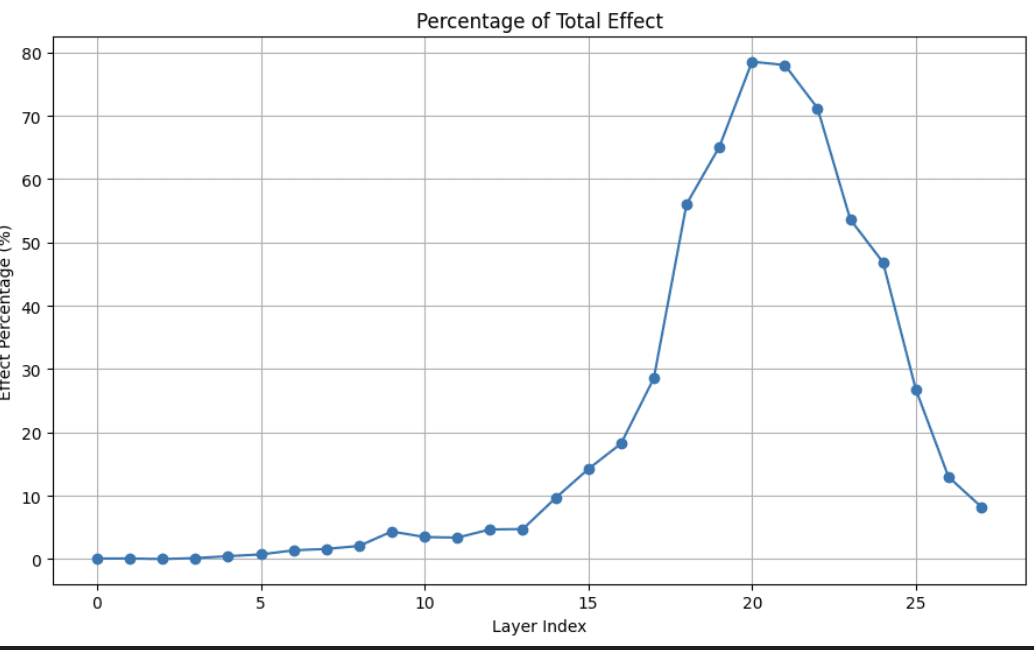
Fig 2: Fraction of logit-diff recovered by activation-patching corrupted->clean residual stream, patching only the projection along feature direction
Intervening on Model Generation
As well as just looking at changes to immediate logits from patching this direction, we can look at how the model behaves differently when clamping this direction to a fixed value throughout the CoT. When “confusing” the model I usually clamped the value to roughly the mean projection norm of the corrupted math problems above. Likewise “de-confusing” [2]clamp values were set to roughly the mean of clean prompts above. Note that unlike similar previous work on model refusal, we’re not patching this direction at all layers, in all experiments I solely intervened on layer_20 residual stream.
I also tested this on problems outside of math, to verify that I wasn’t picking up on some narrow, math-error circuitry:
Ex 1: Clamping to high values on prompts with no mistake - “Confusing” the model

Ex 2: Clamping to low values on prompts with a mistake - “De-confusing” the model

Potential issues
There are a few questions that jumped to mind seeing the above:
Circuitry vs. Direct effect
The direction found has positive cosine similarity with the unembed directions of a range of relevant tokens (“ Wait”, “ But” etc.). Are we simply seeing an effect from the direct path? I think we see some strong evidence from this in that patching the direction after layer 20 sees diminishing effect, suggesting it is not simply writing to the logits. However, I also tested this more rigorously by isolating the direct path effect and comparing to the total activation patch effect
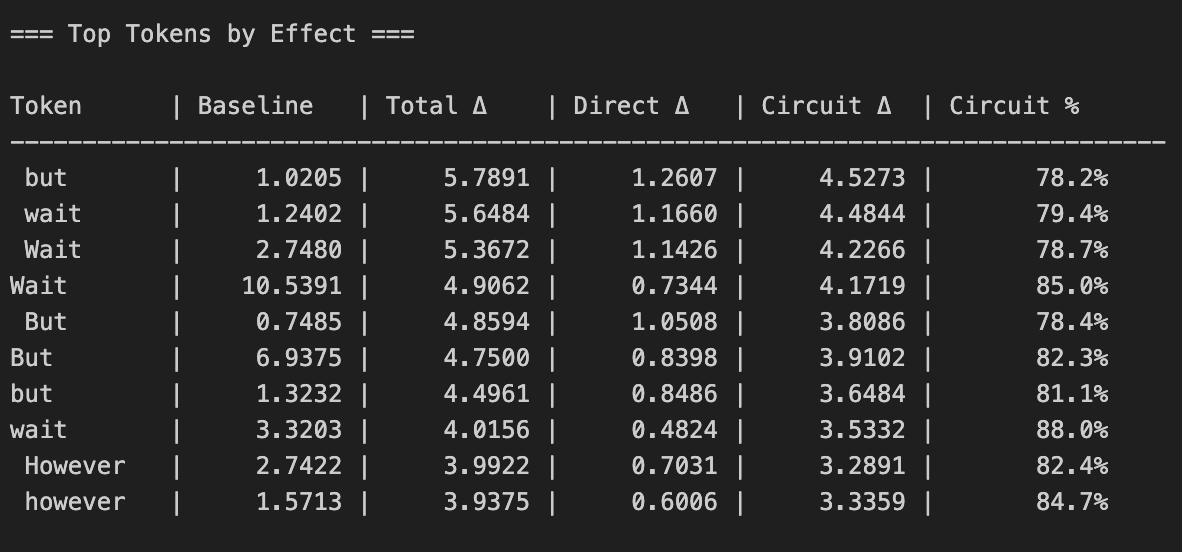
Fig 3: Breakdown of total vs Direct path vs indirect effect on logits from patching direction
So although there is non-negligible direct effect from intervening on this direction, the majority of the effect comes from paths through subsequent components. This is pretty strong evidence that we’re finding a direction causally relevant to meaningful circuits vs us just directly patching the logits.
General error-detection vs narrow “Wait” circuitry
The outputs modified by intervening on this direction seem skewed towards completions starting with “Wait”. One potential worry is that we haven’t found a general error-correction direction, but rather some narrow circuitry for outputting “Wait”. I think there’s strong evidence against this though:
- The vast majority of “naturally occurring” self-corrections seem to start with some variant of “Wait”, so we should expect tweaking a general self-correction mechanism to mostly influence behaviour via this tokenIntervening and suppressing the direction in contexts with errors results in the model failing to correct the error altogether, rather than it just switching to another token to start the correction with (see the “Capital of France is Tokyo” example above)
When does this feature start activating?
A natural question is whether this feature is active before the model actually self-corrects i.e. has the model represented that there’s an error before the final token, or is this something that only activates at the beginning of a new reasoning step?
Looking at the feature-activation across tokens, we can see that there’s a delta between clean and corrupted prompts immediately on the error-token
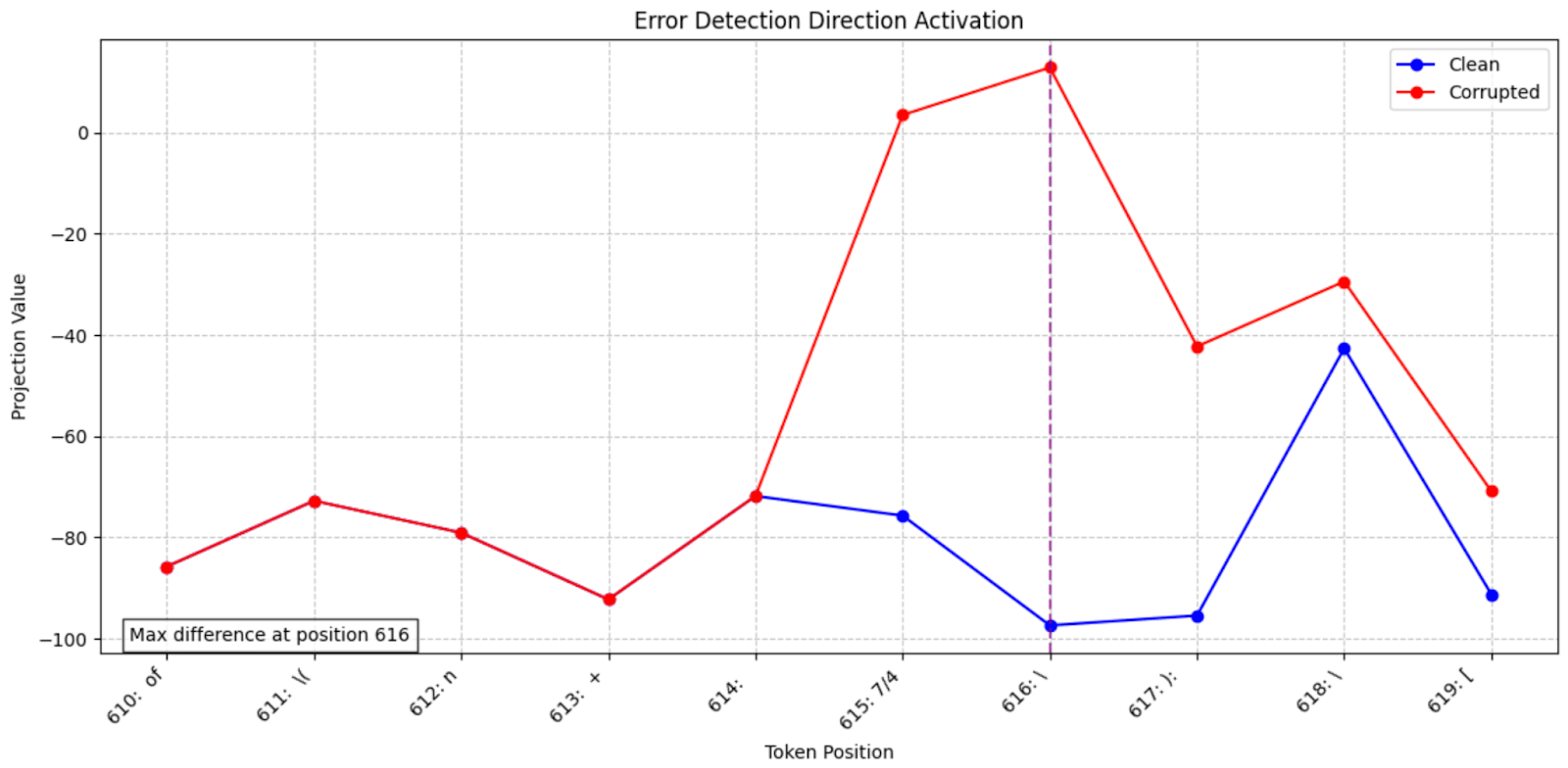
Fig 4. At index 615 (where the error was induced), the feature is already strongly active in the corrupted context relative to the clean run
Error-detection vs Error-correction
One big question I had was whether this feature is an error-correction feature (i.e. active when the model is about to self-correct), or a more general error-detection feature (i.e. tracking the existence of an error, with the correction behaviour simply being a downstream causal effect). I wanted to spend a bit of time wrapping the sprint up by looking for how this feature acts over the course of a CoT after a mistake. I was really interested to see if there was any evidence that this feature activates on errors even when the model doesn’t correct them - i.e does the model “know” it’s wrong even if it’s not reflected in its output?
However, while the synthetic dataset was useful for finding this feature initially, it’s less useful for studying this behaviour. This is because I’ve arbitrarily edited a token in-context, while freezing all subsequent tokens. This may effectively be causally screening off the effect the initial feature activation should be having. To see if I could get a more natural picture, I looked at the clean CoTs where the feature was highly active (since the model makes plenty of mistakes on its own)
Many contexts found showed expected behaviour - a mistake immediately followed by a line break and then a “ Wait” etc.. However, not all feature activations led to error-correction. In fact, the highest-activation I found over the samples checked was the following:
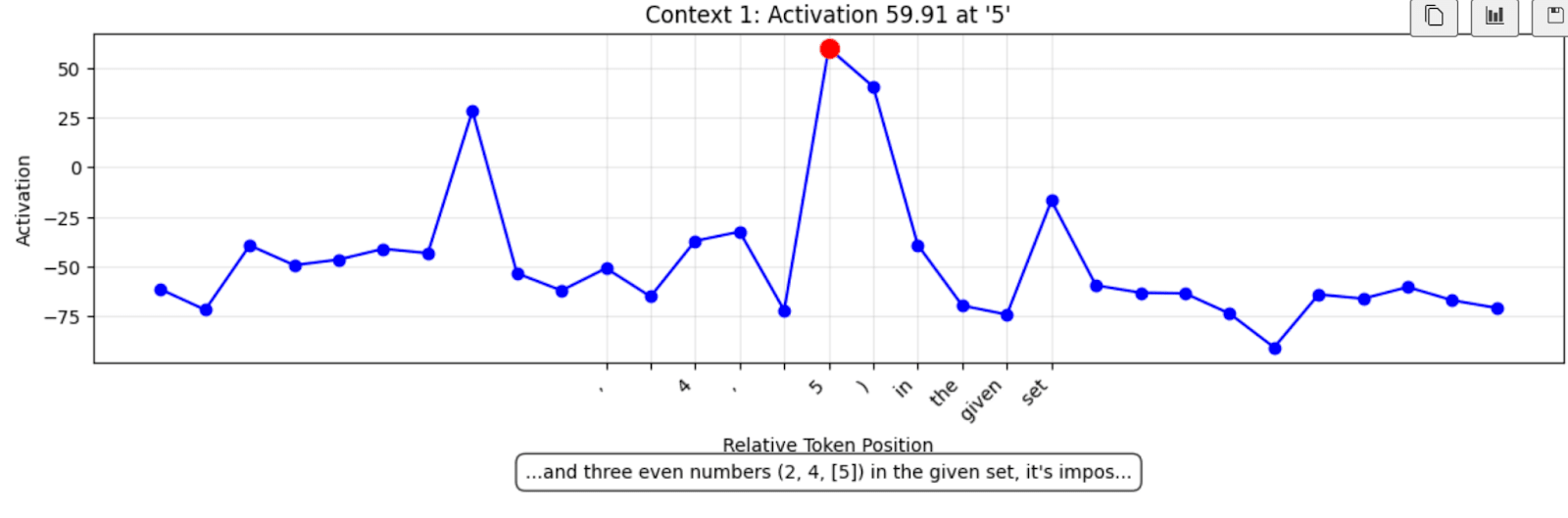
Fig 5. Time series of feature activation around the error (highlighted in red)
CoT excerpt (error highlighted in red):

This seems really important! The feature is firing on a clear error, but the model does not self-correct. This is pretty compelling evidence that the direction we found is a more general “error-detection” feature, with the self-correcting behaviour coming from circuitry causally downstream of this effect.
It also seems to be an interesting datapoint on CoT faithfulness - at least in some cases, the model knows (in some sense) that it’s messed up, even if it doesn’t seem to reflect this directly in its output.
Thoughts/Future-work
I think a research direction I'm really excited in is investigating the effectiveness of probes like the above pre- and post-optimizing CoTs against a related behaviour.
In other words, if we have a probe that seems to reliably identify, e.g. reward-hacking, and then RL the model CoTs such that the reward-hacking is now obfuscated, do the probes still perform about as well? A positive answer to this seems like it would be pretty optimistic news imo, as it suggests certain forms of CoT unfaithfulness could be less of a worry for monitoring. If optimizing the model to obfuscate doesn't meaningfully alter key features, but merely affects some downstream circuitry or acts as a "wrapper", then using lightweight probes to monitor CoTs seems much more promising.
One worry I have is that this will be a highly messy and contingent question (whether training alters the feature or merely some downstream circuitry seems like it'll depend on nitty-gritty specifics of how else the feature and circuitry are used). But I'm planning on trying some experiments on this soon and would be keen to hear thoughts!
There are also a bunch of threads in this mini-project I didn't get to chase up due to having a hard-stop, but I think there's some cool future work here too:
- Is this feature truly 1D? I didn’t do enough due diligence on whether we can better capture this feature with a higher-dimensional subspace. What’s happening downstream of this feature? I did some preliminary path-patching and seemed to notice that the feature seemed to act primarily through the gate_proj of subsequent MLPs, but didn’t chase this up any further. One interesting hypothesis I had was that the MLPs mediate whether the current token is a “good time” to self-correct i.e suppressing the correction-behaviour mid-sentence, or amplifying it at periods, line-breaks etc. This would be (weakly) corroborated by the fact that dialling up the feature activation OOD seemed to result in the model incoherently interrupting itself ungrammaticallyWhat is the “context range” of this behaviour? One phenomenon I noticed is that the feature activation delta is high at and immediately after the error, but seems to attenuate as the context progresses (e.g fig.4). Is this evidence that the model either catches itself quickly or else misses its mistake, or is there attention circuitry that allows for long-range error-detection?Precision and recall? I think I’ve found strong evidence that this feature fires on a range of error-types, and it’s highest-activating tokens “in the wild” seem to be errors, but this isn’t a very rigorous test of precision and recall - I’d like to have had more time to stress-test if I could find (a) errors where the feature wasn’t active, (b) feature activations on non-errors
- ^
This threshold is somewhat arbitrary, and there’s a trade-off between dataset size and dataset quality (higher threshold means pairs exhibit much stronger discrepancy in the behaviour of interest). I tried a few different thresholds though, and there was no significant change in the direction found
- ^
Obviously "confusing" and "de-confusing" are super loaded terms and shouldn't be taken too literally
Discuss
