
With the rise of generative artificial intelligence (AI), an increasing number of organizations use digital assistants to have their end-users ask domain-specific questions, using Retrieval Augmented Generation (RAG) over their enterprise data sources.
As organizations transition from proofs of concept to production workloads, they establish objectives to run and scale their workloads with minimal operational overhead, while optimizing on costs. Organizations also require the implementation of common security practices such as identity and access management, to make sure that only authorized and authenticated users are allowed to perform specific actions or access specific resources.
This post covers a solution to create an end-to-end digital assistant as a web application using a serverless architecture to address these requirements. Because the solution components primarily use serverless technologies, it provides several benefits, such as automatic scaling, built-in high availability, and a pay-per-use billing model to optimize on costs. The solution also includes an authentication layer and an authorization layer to manage identities and permissions.
This solution also uses the hybrid search feature of Knowledge Bases for Amazon Bedrock to increase the relevancy of retrieved results using RAG. When receiving a query from an end-user, hybrid search performs both a semantic search and a keyword search:
- A semantic search provides results based on the meaning and intent within the query A keyword search provides results based on specific entities in a query such as product codes or acronyms
For example, if a user submits a prompt that includes keywords, a text-based search may provide better results than a semantic search. This is why hybrid search combines the two approaches: the precision of semantic search and coverage of keywords. For more information about hybrid search, see Knowledge Bases for Amazon Bedrock now supports hybrid search.
In this post, we provide an operational overview of the solution, and then describe how to set it up with the following services:
- Amazon Bedrock and a knowledge base to generate responses from user questions based on enterprise data sources. Amazon Bedrock is a fully managed service that makes a wide range of foundation models (FMs) available though an API without having to manage any infrastructure. Refer to the Amazon Bedrock FAQs for further details. An Amazon OpenSearch Serverless vector engine to store enterprise data as vectors to perform semantic search. AWS Amplify to create and deploy the web application. Amazon API Gateway and AWS Lambda to create an API with an authentication layer and integrate with Amazon Bedrock. Amazon Cognito to implement an identity platform (user directory and authorization management) for the web application. Amazon Simple Storage Service (Amazon S3) to store the enterprise data used by the solution and web application-related assets.
Solution overview
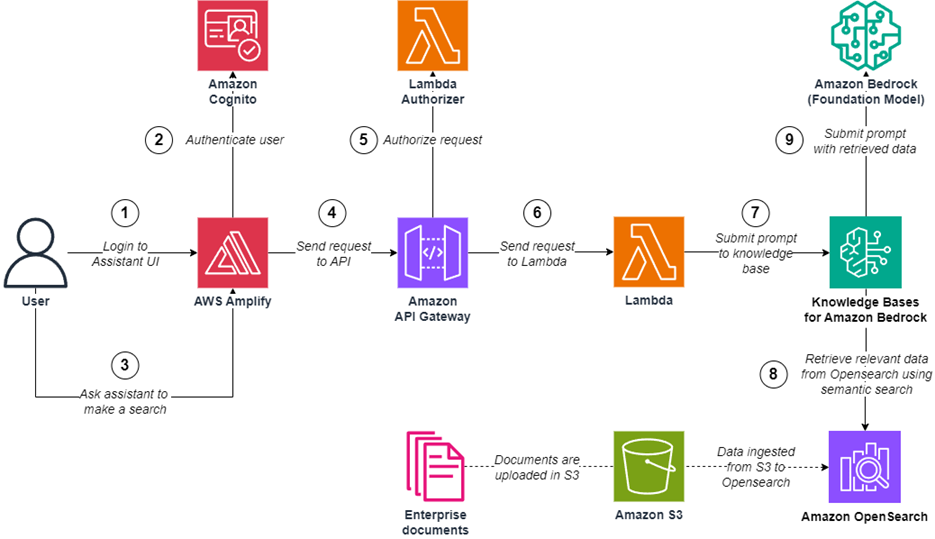
The solution architecture involves the following steps:
- The user authenticates to the web application (the digital assistant UI). Amazon Cognito validates the authentication details. The user submits a request using the web application. The request is sent by the web application to the API. The API calls a Lambda authorizer to confirm that the user is authorized to perform the operation. The request is sent from the API to a Lambda function. The Lambda function submits the request as a prompt to a knowledge base (Knowledge Bases for Amazon Bedrock), and explicitly requests a hybrid search to be performed using the Amazon Bedrock API. Amazon Bedrock retrieves relevant data from the vector store (using the vector engine for OpenSearch Serverless) using hybrid search. Amazon Bedrock submits a prompt to a foundation model.
After Step 9, the foundation model generates a response back that will be returned to the user in the web application’s digital assistant.
The following diagram illustrates this workflow.
Prerequisites
To follow along and set up this solution, you must have the following:
- An AWS account A device with access to your AWS account with the following:
- Python 3.12 installed Node.js 20.12.0 installed The AWS Amplify CLI set up

Upload documents and create a knowledge base
In this section, we create a knowledge base in Amazon Bedrock. The knowledge base will enrich the prompt submitted to an Amazon Bedrock foundation model with contextual information derived from our data source (in our case, documents uploaded in a S3 bucket).
During the creation of the knowledge base, a vector store will also be created to ingest documents encoded as vectors, using an embeddings model. An embeddings model encodes data as vectors in order to capture the meaning and context of our sample documents. This allows us to find data relevant to our end-user prompts.
For our use case, we use the vector engine for OpenSearch Serverless as a vector store and Titan Text Embeddings G1 model as the embeddings model.
Complete the following steps to create an S3 bucket to upload documents, and synchronize them with a knowledge base in Amazon Bedrock:
- Create an S3 bucket in your account. Upload the following documents in the S3 bucket:
- The Overview of Amazon Web Services whitepaper. The AWS Well-Architected Framework documentation. The Implementing Microservices on AWS whitepaper.
- For Knowledge base name, enter
assistant-knowledgebase. For Knowledge base description, enter Knowledge base for digital assistant. For IAM permissions, select Create and use a new service role. For Data source name, enter assistant-knowledgebase-datasource. For S3 URI, enter the URI of the previously created S3 bucket (for example, s3://#s3-bucket-name#). For Embeddings model, choose Titan G1 Embeddings – Text. For Vector database, select Quick create a new vector store. Create the API and backend
In this section, we create the following resources:
- A user directory for web authentication and authorization, created with an Amazon Cognito user pool. An API created with Amazon API Gateway. This will expose a single-entry door interface to our digital assistant’s web application. An authorization layer in our API, to protect our backend from unauthorized users. This will be implemented with a Lambda authorizer function to validate that incoming requests include valid authorization details. A Lambda function behind the API, which will submit prompts to a knowledge base and return responses back to the API.
Complete the following steps to create the API and the backend of the digital assistant’s web application, using AWS CloudFormation templates:
- Clone the GitHub repository. Navigate to the api folder, which includes the following content:
- A template named webapp-userpool-stack.yml for the Amazon Cognito user pool A template named webapp-lambda-stack.yml for the Lambda function calling a knowledge base A template named webapp-api-stack.yml for the API and the Lambda authorizer function A subfolder named lambda-auth for the Lambda authorizer function code A subfolder named lambda-knowledgebase for the Lambda function calling a knowledge base A script named cognito-create-testuser.sh to create a test user in the Amazon Cognito user pool
api folder and create the Lambda function of the web application using the following AWS CLI command (provide your S3 bucket and knowledge base ID): You can retrieve the knowledge base ID by running the following AWS CLI command:
- Create the API of the web application using the following AWS CLI command (provide your bucket name):
Configure the Amazon Cognito user pool
In this section, we create a user in our Amazon Cognito user pool. This user will be used to log in to our web application.
Complete the following steps to configure the Amazon Cognito user pool created in the previous section:
- On the Amazon Cognito console, access the user pool named webapp-userpool. On the Users tab, choose Create a user. For Invitation message, select Send an email invitation. For Email address section, enter your email address and select Mark email address as verified. For Temporary password, select Generate a password. Choose Create user.

You can also complete these steps by running the script cognito-create-testuser.sh available in the api folder as follows (provide your email address):
After you create the user, you should receive an email with a temporary password in this format: “Your username is #your-email-address# and temporary password is #temporary-password#.”
Keep note of these login details (email address and temporary password) to use later when testing the web application.
Create the web application
In this section, we build a web application using Amplify and publish it to make it accessible through an endpoint URL. To complete this section, you must first install and set up the Amplify CLI, as discussed in the prerequisites.
Complete the following steps to create the web application of the digital assistant:
- Go back to the root folder of the repository and open the frontend folder. Run the script amplify-setup.sh to create the Amplify application:
The amplify-setup.sh script creates an Amplify application and configures it to integrate with resources you created in the previous modules:
- The Amazon Cognito user pool to authenticate our user through the web application’s login page The Amazon API Gateway to process prompts submitted using the web application’s chat interface
- Configure the hosting of the Amplify application using the following command: Choose the following options:
- For Select the plugin module to execute, choose Hosting with Amplify Console (Managed hosting with custom domains, Continuous deployment). For Choose a type, choose Manual deployment.
In this step, we configure how the web application will be deployed and hosted:
- The web application will be hosted using the Amplify console, which offers fully managed hosting The web application will be deployed using manual deployment, which allows us to publish our web application to the Amplify console without connecting a Git provider
- Publish the Amplify application using the following command:
The web application is now available for testing and a URL should be displayed, as shown in the following screenshot. Take note of the URL to use in the following section.

Test the digital assistant
In this section, you test the web application of the digital assistant:
- Open the URL of the Amplify application in your navigator. Enter your login information (your email and the temporary password you received earlier while configuring the user pool in Amazon Cognito) and choose Sign in.
 When prompted, enter a new password and choose Change Password.
When prompted, enter a new password and choose Change Password. You should now be able to see a chat interface. Ask a question to test the assistant. For example, “What is the OPS number related to health of operations in the Well Architected framework?”
You should now be able to see a chat interface. Ask a question to test the assistant. For example, “What is the OPS number related to health of operations in the Well Architected framework?” You should receive a response along with sources, as shown in the following screenshot

Clean up
To make sure that no additional cost is incurred, remove the resources provisioned in your account. Make sure you’re in the correct AWS account before deleting the following resources.
- Delete the knowledge base. Delete the CloudFormation stacks (provide the AWS Region where you created your resources): Delete the Amplify application with the following AWS CLI command (provide your application ID and the Region where it was created): You can retrieve the app id by running the following AWS CLI command: Delete the S3 buckets.
You should exercise caution when performing the preceding steps. Make sure you are deleting the resources in the correct AWS account.
Conclusion
In this post, we walked through a solution to create a digital assistant using serverless services. First, we created a knowledge base and ingested documents into it from an S3 bucket. Then we created an API and a Lambda function to submit prompts to the knowledge base. We also configured a user pool to grant a user access to the digital assistant’s web application. Finally, we created the frontend of the web application in Amplify.
For further information on the services used, consult the Amazon Bedrock, Security in Amazon Bedrock, Amazon OpenSearch Serverless, AWS Amplify, Amazon API Gateway, AWS Lambda, Amazon Cognito, and Amazon S3 product pages.
To dive deeper into this solution, a self-paced workshop is available in AWS Workshop Studio, at this location.
About the author
 Mehdi Amrane is a Senior Solutions Architect at Amazon Web Services. He supports customers on their initiatives and provides them prescriptive guidance to achieve their goals, and accelerate their cloud journey. He is passionate about creating content on application architecture, DevOps and Serverless technologies.
Mehdi Amrane is a Senior Solutions Architect at Amazon Web Services. He supports customers on their initiatives and provides them prescriptive guidance to achieve their goals, and accelerate their cloud journey. He is passionate about creating content on application architecture, DevOps and Serverless technologies.
