


Concept-based learning (CBL) in machine learning emphasizes using high-level concepts from raw features for predictions, enhancing model interpretability and efficiency. A prominent type, the concept-based bottleneck model (CBM), compresses input features into a low-dimensional space to capture essential data while discarding non-essential information. This process enhances explainability in tasks like image and speech recognition. However, CBMs often require deep neural networks and extensive labeled data. A simpler approach involves Multiple Instance Learning (MIL), which labels groups of data (bags) with unknown individual labels. For instance, clustering image patches and assigning probabilities based on overall image labels can infer individual patch labels.
Great St. Petersburg Polytechnic University researchers have pioneered an approach to CBL known as Frequentist Inference CBL (FI-CBL). This method involves segmenting concept-labeled images into patches and encoding them into embeddings using an autoencoder. These embeddings are then clustered to identify groups corresponding to specific concepts. FI-CBL determines concept probabilities for new images by analyzing the frequency of patches associated with each concept value. Moreover, FI-CBL integrates expert knowledge through logical rules, which adjust concept probabilities accordingly. This approach stands out for its transparency, interpretability, and efficacy, particularly in scenarios with limited training data.
CBL models, including CBMs, use high-level concepts for interpretable predictions. These models span various applications, from image recognition to tabular data analysis, and are pivotal in medicine. CBMs feature a two-module structure that separates the learning of concepts and their impact on the target variable. Innovations like concept embedding models and probabilistic CBMs have enhanced their interpretability and accuracy. Additionally, integrating expert knowledge into machine learning, particularly through logic rules, has garnered significant interest, with methods ranging from constraints in loss functions to mapping rules to neural network components.
CBL involves a classifier predicting both target variables and concepts from a set of training data pairs. Each data pair includes an input feature vector, a target class, and binary concept values indicating the presence or absence of concepts. CBL models aim to predict and explain how these concepts relate to the predictions. This is typically done using a two-step function: mapping inputs to concepts and then concepts to forecasts. For instance, in medical images, each image can be divided into patches, and their embeddings can be clustered to determine concept probabilities, allowing the model to explain and highlight relevant areas in the images based on these concepts.
Incorporating expert rules into the FI-CBL profoundly influences the probabilistic model by adjusting the concepts’ prior and conditional probabilities. By integrating logical expressions provided by experts, such as “IF Contour is <grainy>, THEN Diagnosis is <malignant>,” the model refines its predictions based on these constraints. This enhancement facilitates a more nuanced understanding of medical imaging data, where prior probabilities for diagnoses like <malignant> increase or decrease as per rule satisfaction, thus improving diagnostic accuracy and interpretability. Integrating expert rules empowers FI-CBL to blend domain expertise with statistical modeling effectively, advancing reliability and insightfulness in medical diagnostics.
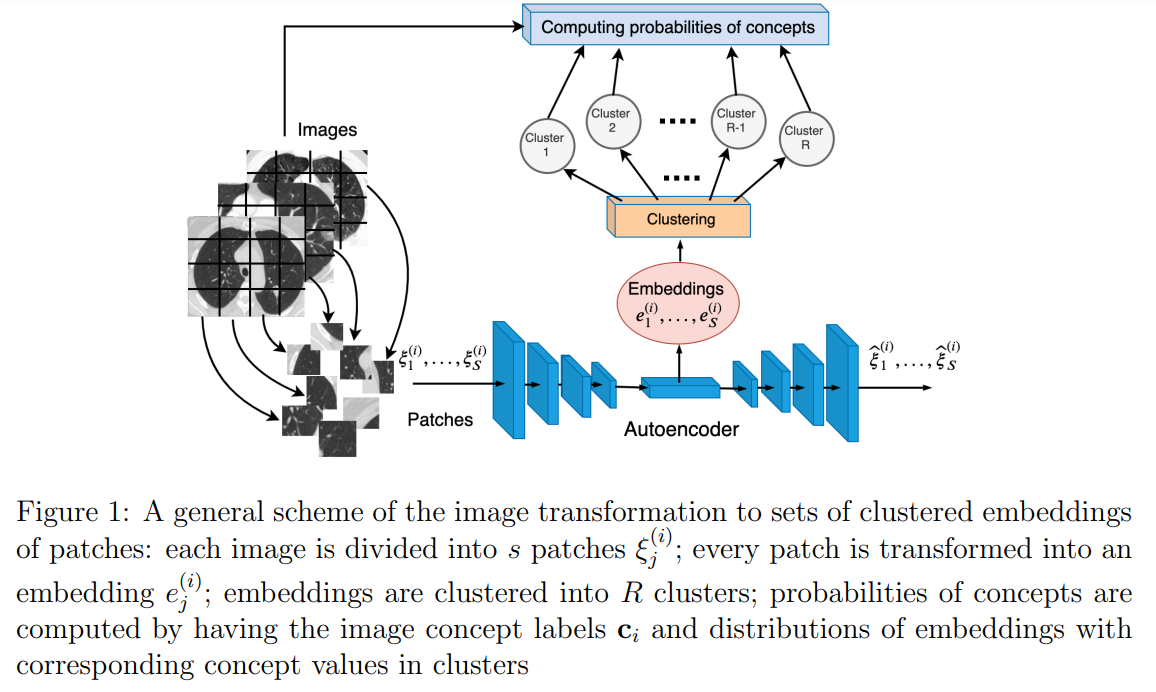
The FI-CBL offers significant advantages over neural network-based CBMs in certain scenarios. FI-CBL is characterized by its transparency and interpretability, providing a clear sequence of calculations and explicit probabilistic interpretations of all model outputs. It demonstrates superior performance with small training datasets, leveraging robust statistical methods to enhance classification accuracy. However, FI-CBL’s effectiveness depends heavily on accurate clusterization and optimal patch size selection, posing challenges in scenarios with varied concept sizes. Despite these challenges, FI-CBL’s flexibility in architecture adjustments and ability to integrate expert rules effectively make it a promising approach for enhancing interpretability and performance in machine learning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post FI-CBL: A Probabilistic Method for Concept-Based Machine Learning with Expert Rules appeared first on MarkTechPost.
