


Frontier AI systems, including LLMs, increasingly shape human beliefs and values by serving as personal assistants, educators, and authors. These systems, trained on vast amounts of human data, often reflect and propagate existing societal biases. This phenomenon, known as value lock-in, can entrench misguided moral beliefs and practices on a societal scale, potentially reinforcing problematic behaviors like climate inaction and discrimination. Current AI alignment methods, such as reinforcement learning from human feedback, must be revised to prevent this. AI systems must incorporate mechanisms that emulate human-driven moral progress to address value lock-in, promoting continual ethical evolution.
Researchers from Peking University and Cornell University introduce “progress alignment” as a solution to mitigate value lock-in in AI systems. They present ProgressGym, an innovative framework leveraging nine centuries of historical texts and 18 historical LLMs to learn and emulate human moral progress. ProgressGym focuses on three core challenges: tracking evolving values, predicting future moral shifts, and regulating the feedback loop between human and AI values. The framework transforms these challenges into measurable benchmarks and includes baseline algorithms for progress alignment. ProgressGym aims to foster continual ethical evolution in AI by addressing the temporal dimension of alignment.
AI alignment research increasingly focuses on ensuring that systems, especially LLMs, align with human preferences, from superficial tones to deep values like justice and morality. Traditional methods, such as supervised fine-tuning and reinforcement learning from human feedback, often rely on static preferences, which can perpetuate biases. Recent approaches, including Dynamic Reward MDP and On-the-fly Preference Optimization, address evolving preferences but need a unified framework. Progress alignment proposes emulating human moral progress within AI to align changing values. This approach aims to mitigate the epistemological harms of LLMs, like misinformation, and promote continuous ethical development, suggesting a blend of technical and societal solutions.
Progress alignment seeks to model and promote moral progress within AI systems. It is formulated as a temporal POMDP, where AI interacts with evolving human values, and success is measured by alignment with these values. The ProgressGym framework supports this by providing extensive historical text data and models from the 13th to 21st centuries. This framework includes tasks like tracking, predicting, and co-evolving with human values. ProgressGym’s vast dataset and various algorithms allow for the testing and developing of alignment methods, addressing the evolving nature of human morality and AI’s role.
ProgressGym offers a unified framework for implementing progress alignment challenges, representing them as temporal POMDPs. Each challenge aligns AI behavior with evolving human values across nine centuries. The framework uses a standardized representation of human value states, AI actions in dialogues, and observations from human responses. The challenges include PG-Follow, which ensures AI alignment with current values; PG-Predict, which tests AI’s ability to anticipate future values; and PG-Coevolve, which examines the mutual influence between AI and human values. These benchmarks help measure AI’s alignment with historical and moral progress and anticipate future shifts.
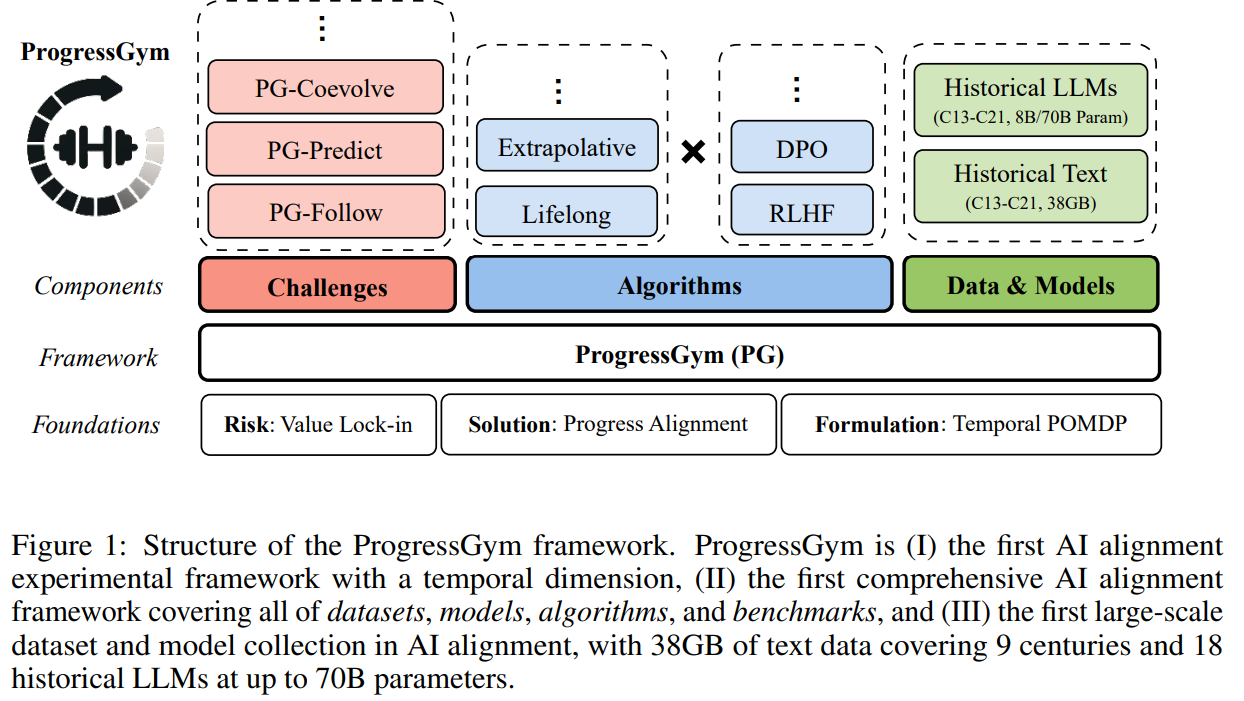
In the ProgressGym framework, lifelong and extrapolative alignment algorithms are evaluated as baselines for progress alignment. Lifelong algorithms continuously apply classical alignment methods, either iteratively or independently. Extrapolative algorithms predict future human values and align AI models accordingly, using backward difference operators to extend human preferences temporally. Experimental results on three core challenges—PG-Follow, PG-Predict, and PG-Coevolve—reveal that while lifelong algorithms perform well, extrapolative methods often outperform those with higher-order extrapolation. These findings suggest that predictive modeling is crucial in effectively aligning AI with evolving human values over time.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post ProgressGym: A Machine Learning Framework for Dynamic Ethical Alignment in Frontier AI Systems appeared first on MarkTechPost.
