

Reasoning about interactions and relations is central to human intelligence and represents a key objective in the field of artificial intelligence (AI). With the era of big data and advances in AI technologies, we are now able to extract multimodal, high-dimensional data from an extensive array of scenes. This thesis addresses the critical question of how to analyze and study the characteristics of such data, uncover the underlying low-dimensional representations and interaction features, and leverage these findings in various downstream applications, such as robotics, scene analysis, and biomedicine.
探讨交互和关系推理是人类智能的核心,也是人工智能领域的关键目标。随着大数据时代和人工智能技术的进步,我们现在能够从广泛的场景中提取多模态、高维数据。本论文探讨了如何分析和研究这类数据的特征,揭示其潜在的低维表示和交互特征,并将这些发现应用于各种下游应用,如机器人、场景分析和生物医学。
From a methodological and modeling perspective, I investigate the notion that neural interaction models based on biological neural networks can often be abstracted into small-world network models. I examine whether similar topological interaction patterns can be applied to artificial neural networks and deep learning (DL) models. Based on this, I have designed the community channel network (CC-Net), embedding the small-world model into convolutional neural networks (CNNs), thereby enhancing neural network performance in representation learning efficiently and adaptively.
从方法论和建模的角度来看,我研究了基于生物神经网络的神经交互模型通常可以抽象为小世界网络模型的观点。我考察了是否可以将类似拓扑交互模式应用于人工神经网络和深度学习(DL)模型。基于此,我设计了社区通道网络(CC-Net),将小世界模型嵌入到卷积神经网络(CNN)中,从而有效地自适应地提高神经网络在表示学习中的性能。
I extend this research philosophy to the application of similar interaction models in various multimodal contexts, encompassing macro- and micro-interaction levels. Macro-interactions refer to large-scale interactions primarily involving humans. These interactions occur in real-world scenarios and are explicitly represented through pairs. I studied (1) human-robot interaction. I developed a unified framework that combines interaction learning with multimodal learning. This framework is applied in real-world kitchen scenarios where robots interact with the environment, collecting multimodal data (including sound and video) to discern critical scene information such as the volume of liquid in containers, types of containers, and food categories, potentially aiding in the deployment of home-assistance robots. (2) human object interaction (HOI): I studied HOI in natural images, implementing efficient object detection and interaction categorization during temporal changes in data distribution. This helps overcome model forgetting and potentially aids downstream tasks such as scene understanding and robotics. (3) human-sensor interaction. I designed a deep learning-based temporal method that analyzes a runner’s biomechanics parameters and performance levels by collecting inertial measurement unit (IMU) signals during their run. This analysis helps improve athletic performance and rehabilitation training for different runners. Micro-interactions are concerned with the granularity of chemical compounds, occurring at the molecular or feature level within controlled laboratory settings. My research specifically focused on predicting properties of molecular data. I developed a benchmark to test the performance of various pre-trained graph models under out-of-distribution (OOD) scenarios, such as changes in molecular scaffolds, size, and assays. The findings demonstrate the robustness of pre-trained models in OOD scenarios, outperforming specially designed methods (such as disentangle learning) and offering a streamlined and effective solution for molecular graph prediction in real-world data scenarios.
我扩展了这种研究哲学,将其应用于各种多模态环境中的类似交互模型,包括宏观和微观交互层面。宏观交互主要涉及人类的大规模交互,这些交互发生在现实世界场景中,并通过成对的方式明确表示。我研究了(1)人机交互。我开发了一个结合交互学习和多模态学习的统一框架。该框架应用于现实世界的厨房场景,其中机器人与环境交互,收集多模态数据(包括声音和视频),以辨别关键场景信息,如容器中液体的体积、容器的类型和食物类别,可能有助于家庭服务机器人的部署。(2)人-物体交互(HOI):我研究了自然图像中的人-物体交互,在数据分布的时间变化中实现了高效的对象检测和交互分类。这有助于克服模型遗忘,并可能有助于下游任务,如场景理解和机器人技术。(3)人-传感器交互。 我设计了一种基于深度学习的时序方法,通过在跑步过程中收集惯性测量单元(IMU)信号来分析跑者的生物力学参数和表现水平。这种分析有助于提高不同跑者的运动表现和康复训练。微交互关注的是化学化合物的粒度,在受控的实验室环境中,在分子或特征层面上发生。我的研究特别关注预测分子数据属性。我开发了一个基准来测试各种预训练图模型在分布外(OOD)场景下的性能,例如分子支架、大小和检测的变化。研究结果证明了预训练模型在 OOD 场景中的鲁棒性,优于专门设计的方法(如解耦学习),并为现实世界数据场景中的分子图预测提供了一个简化和有效的解决方案。
Looking ahead, this research opens multiple avenues for further exploration and development. The CC-Net’s adaptability and efficiency in enhancing representation learning pave the way for more advanced AI models that closely mimic human neural processing. Applications in human-robot interaction and HOI highlight the potential for more intuitive and responsive AI systems in everyday life, from automated video analysis to advanced robotic assistance. The success in human-sensor interaction analysis and molecular property prediction underscores the versatility of the proposed models in diverse fields, from sports science to pharmaceuticals. The robust performance of pre-trained models in OOD scenarios also suggests a promising future for AI applications in areas where data variability is high. This thesis not only contributes to the understanding of multimodal and interaction representation learning but also sets a foundation for future research that can further integrate these findings into practical, real-world applications.
展望未来,这项研究为进一步的探索和发展开辟了多条途径。CC-Net 在增强表示学习方面的适应性和效率为更先进的 AI 模型铺平了道路,这些模型能够更紧密地模拟人类神经处理。在人类-机器人交互和 HOI 中的应用突显了在日常生活中的 AI 系统更加直观和响应的潜力,从自动视频分析到高级机器人辅助。在人类-传感器交互分析和分子性质预测方面的成功强调了所提出模型在各个领域的多功能性,从体育科学到制药。在 OOD 场景中预训练模型的稳健性能也预示了 AI 在数据变异性高的领域应用前景的广阔。本论文不仅有助于理解多模态和交互表示学习,还为将来的研究奠定了基础,这些研究可以将这些发现进一步整合到实际、现实世界的应用中。

论文题目:Learning Interactive and Multi-modal Deep Representation: Applications on Computer Vision, Bio-mechanics, and Chemoinformatics
作者:Qi LIU
类型:2024年博士论文
学校:City University of Hong Kong(香港城市大学)
下载链接:
链接: https://pan.baidu.com/s/1GbuHulRZhj_FRSH3VFABtg?pwd=yk5b
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
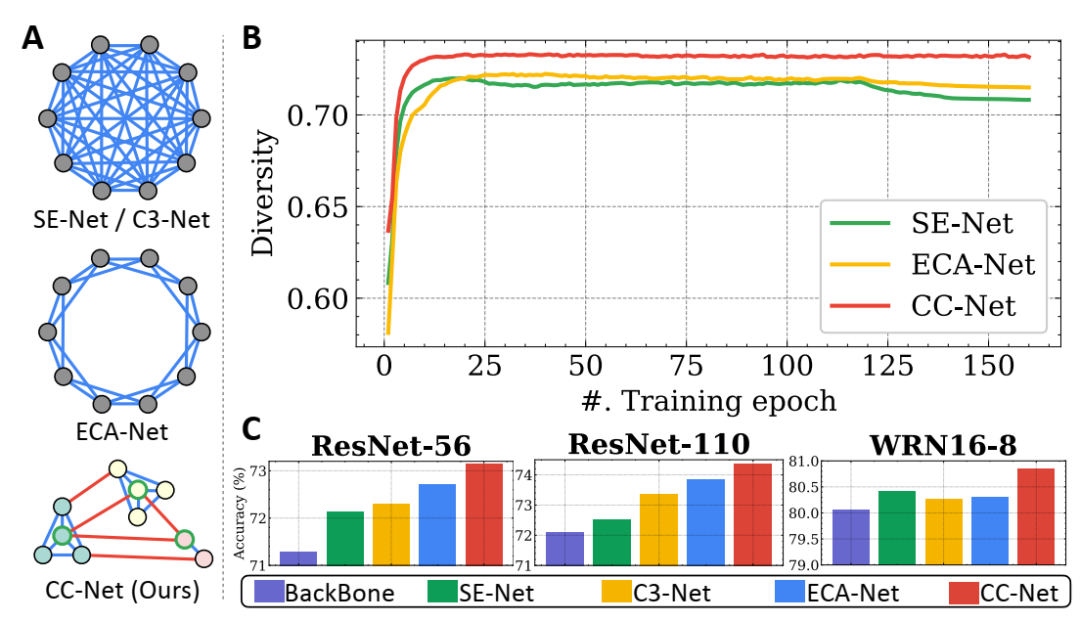
所提方法的特性。A. 从图的视角构建了不同通道交互方法的统一框架;B. 训练过程中不同通道交互方法的通道多样性。我们仅将我们的方法与 SE-Net 和 ECA-Net 进行比较,因为 C3-Net 具有不同的信息交换模块;C. 使用不同 CNN 模型在 CIFAR-100 数据集上的准确率。
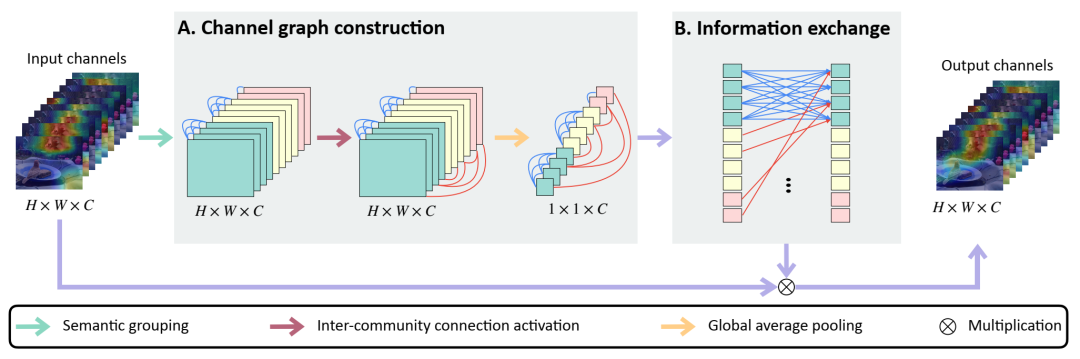
CC-Net 框架包含两个主要步骤:通道图构建和信息交换。相同颜色的矩形表示具有相似语义表示的通道。红线和蓝线分别表示社区间和社区内的连接。
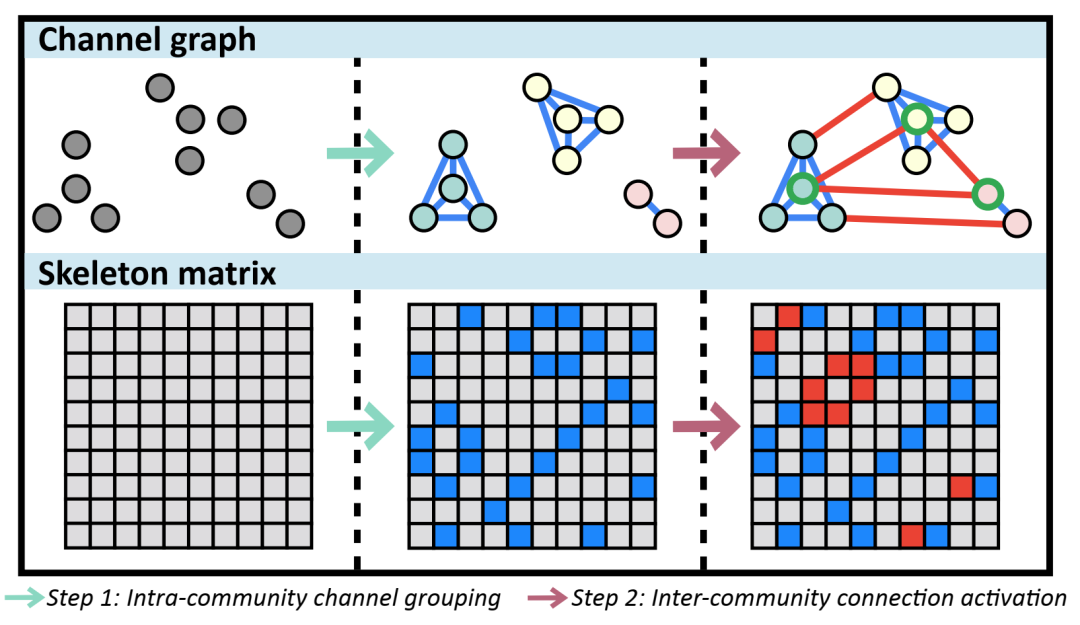
通道图构建过程图解。相同颜色的不同节点表示分配给同一社群的通道。带有绿色圆圈的节点表示选定的关键通道。蓝色和红色的边或条目表示社群间连接和社群内连接。灰色条目表示两个通道之间没有交互。彩色显示效果最佳。
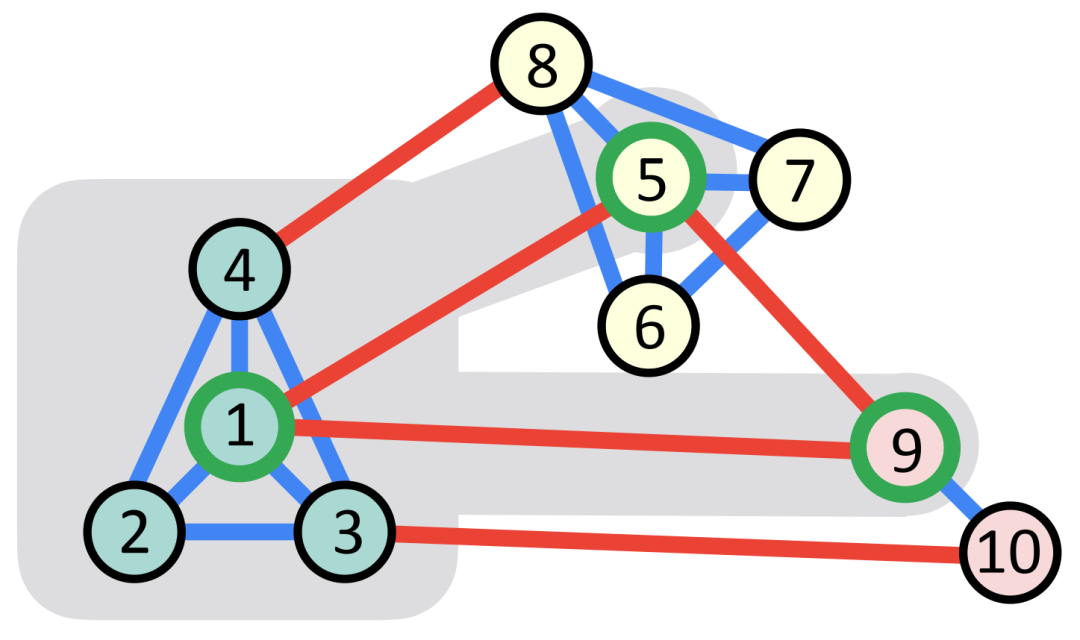
节点 1 信息交换的示例。灰色区域包含节点 1 的邻居节点。每个节点的颜色表示其社区属性。
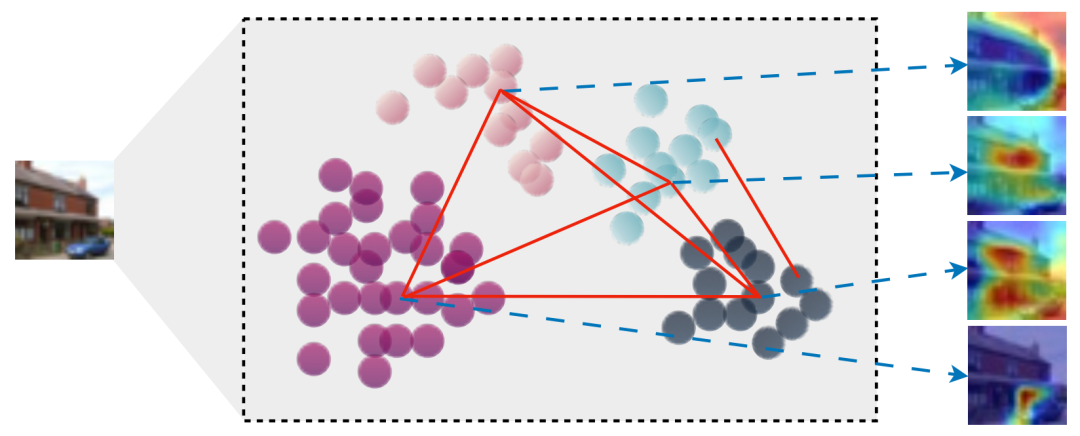
通道图可视化,包含 CC-ResNet-56 最后一个残差阶段的 64 个通道,输入为 CIFAR-100 中的一张房屋图像。红线表示社区间连接。为了提高可读性,此处省略了社区内连接。
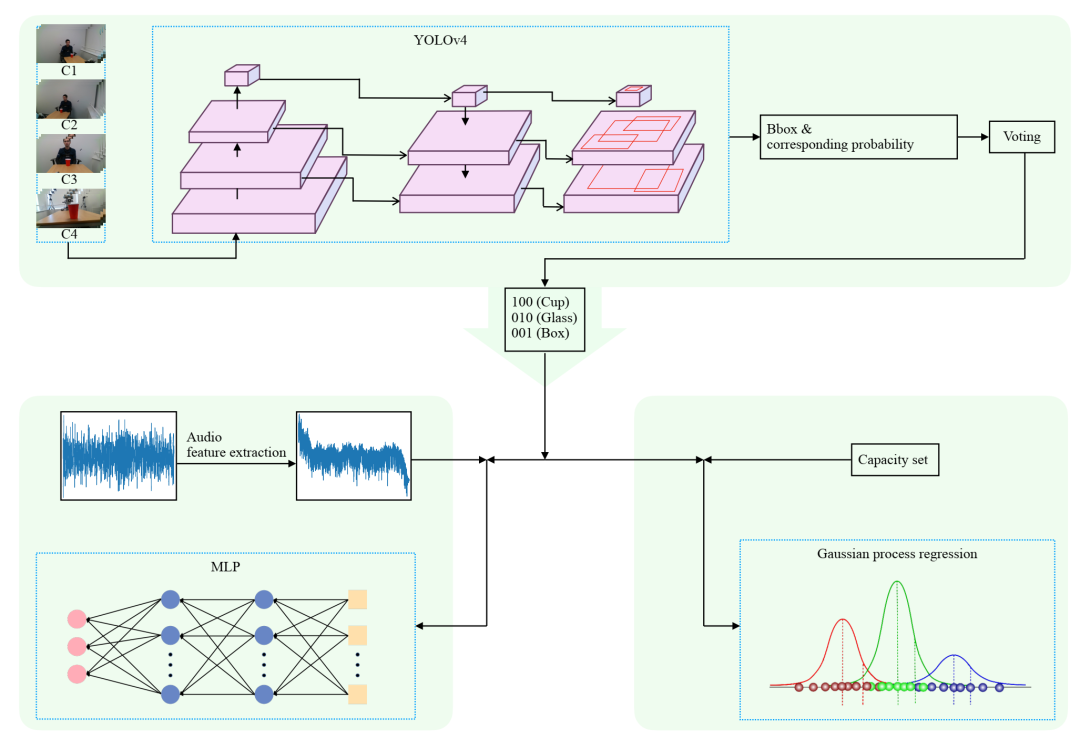
填充质量估算的整体流程。𝐶𝑖 表示来自𝑖𝑡ℎ 摄像头 (Intel RealSense D435i) 的视图,𝐶1 表示来自机械臂左侧的视图,𝐶2 表示来自机械臂右侧的视图,𝐶3 表示安装在机械臂上的摄像头的正面视图,𝐶4 表示来自演示者(人类)佩戴的移动摄像头的视图。

音频特征提取流程。(a) 采样音频序列;(b-c)采用 FFT 算法对采样音频进行频谱分析。

来自 CORSMAL 容器操作数据集的训练集和公共测试集的容器 [363]。
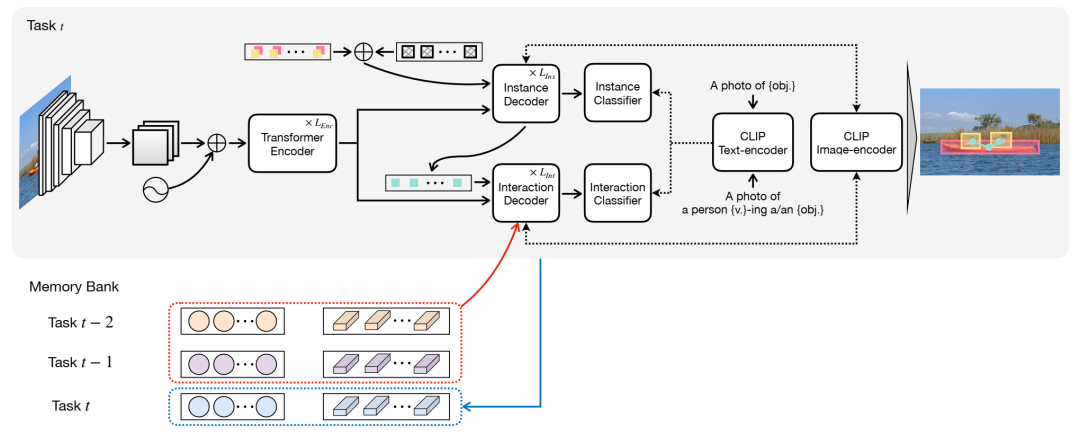
持续 HOI 的总体流程。
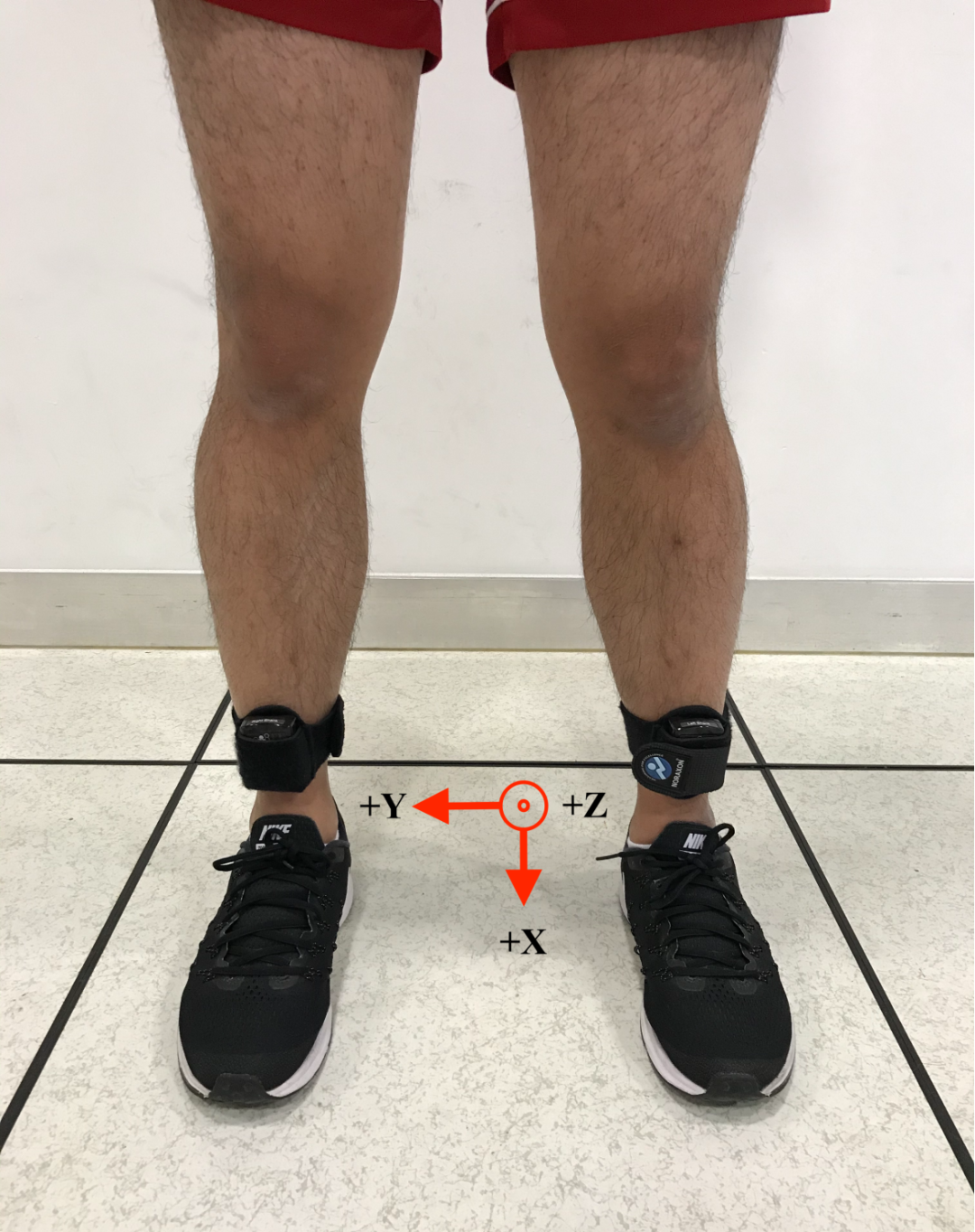
IMU 位置和轴方向。
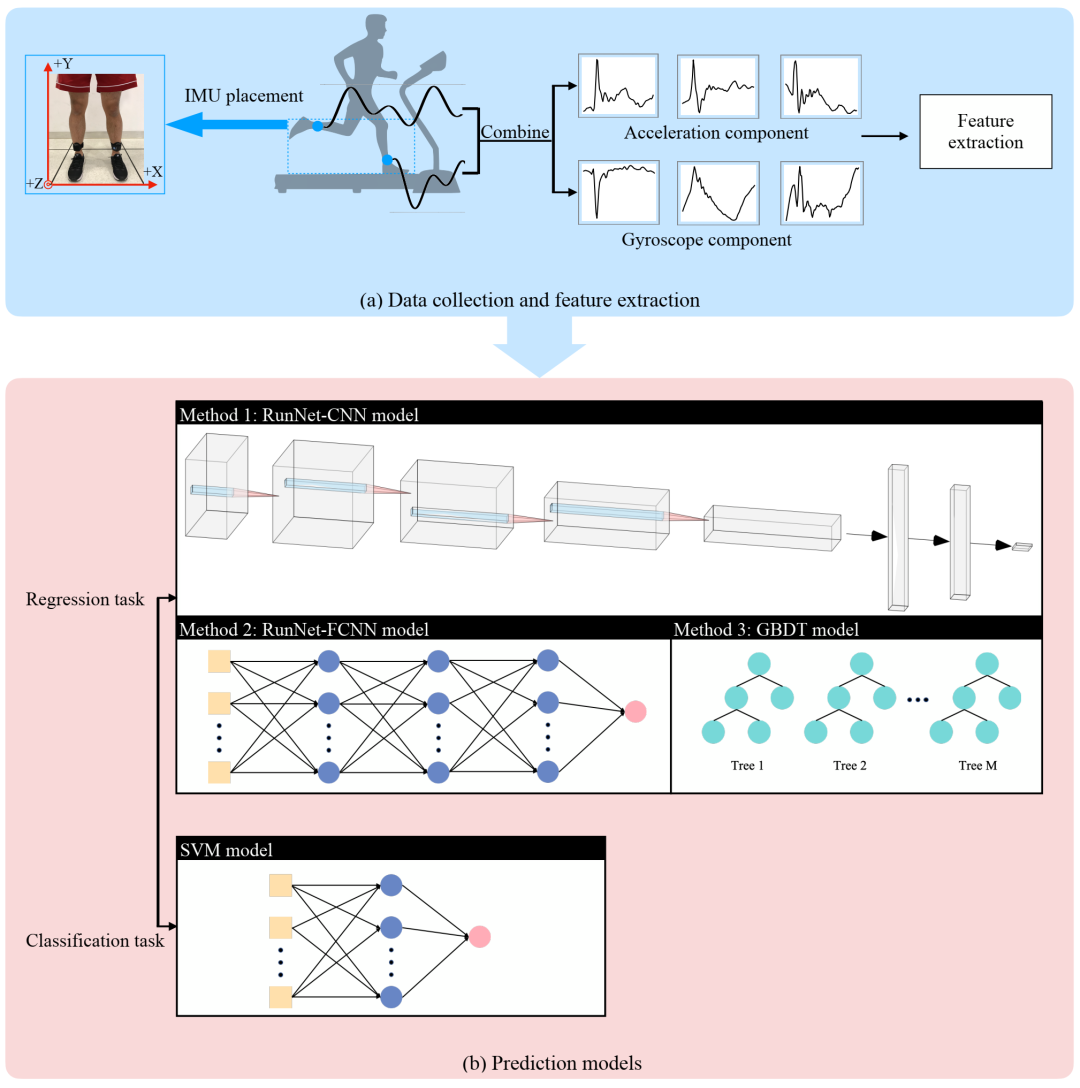
生物力学参数预测的总体框架。
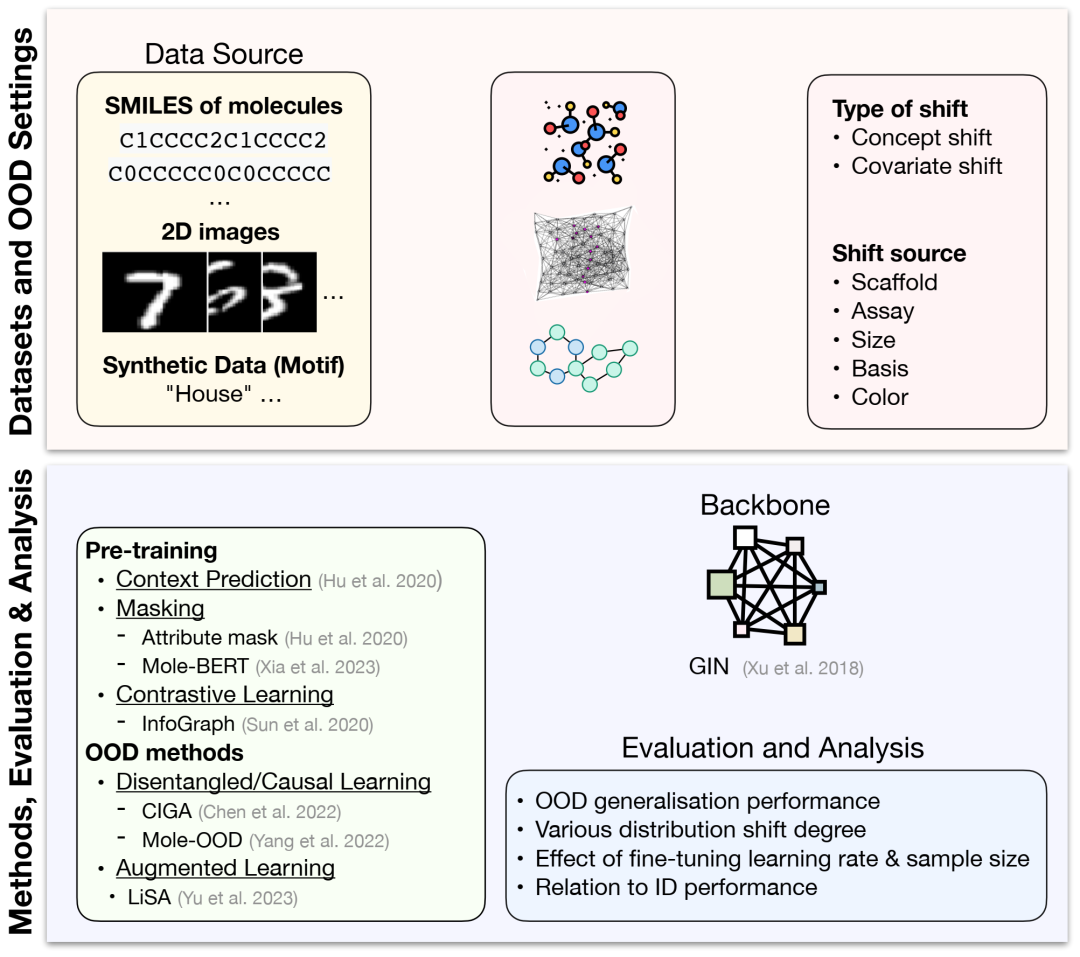
PODGenGraph 基准测试摘要。
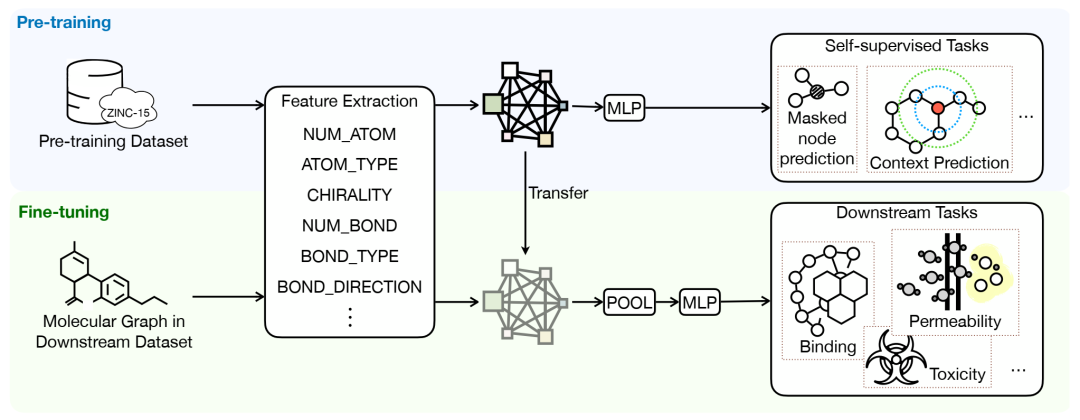
PODGenGraph 基准测试流程概述。它通过特征提取和不同的预训练策略,使用大规模未标记数据集,实例化自监督预训练。之后,它将预训练模型迁移到与化学图分布外泛化相关的各种下游任务上进行微调。






内容中包含的图片若涉及版权问题,请及时与我们联系删除
