
How to monitor containerized applications in Azure (Sponsored)

In this eBook, you’ll learn how to deploy and monitor containerized applications using Azure and Datadog. Start monitoring AKS cluster status, AKS control plane, and understand critical AKS resource metrics. Plus, get best practices on collecting and tracking observability data across your container environment, and be alerted to performance issues and potential threats automatically.
This week’s system design refresher:
The Data Engineering Roadmap
Popular interview question: What is the difference between Process and Thread?
What do version numbers mean?
How Transformers Architecture Works
Top YouTube Channels and Blogs for AI Learning in 2025
SPONSOR US
The Data Engineering Roadmap
Data engineering has become the backbone of effective data analysis. It involves managing, processing, and optimizing data to derive actionable insights.
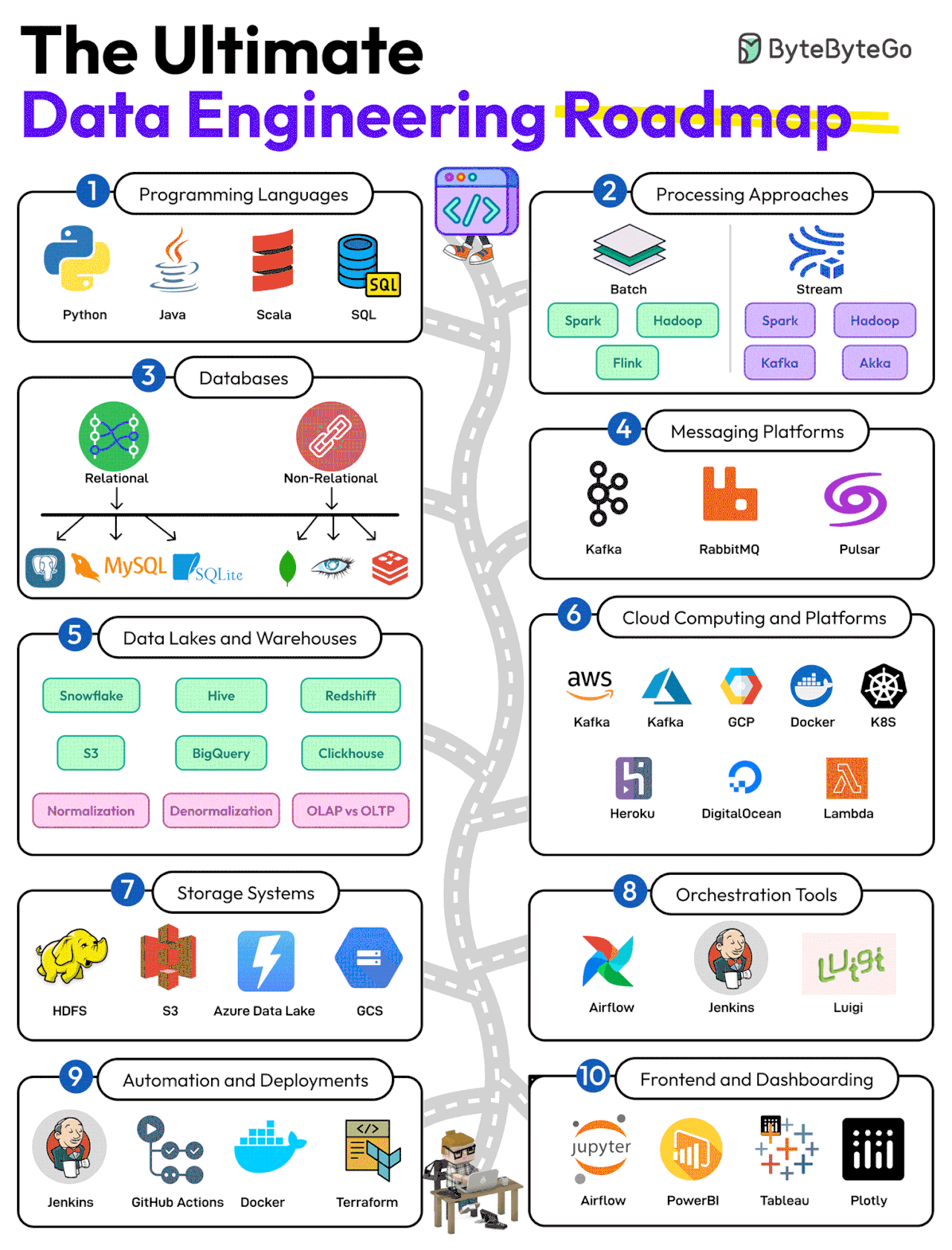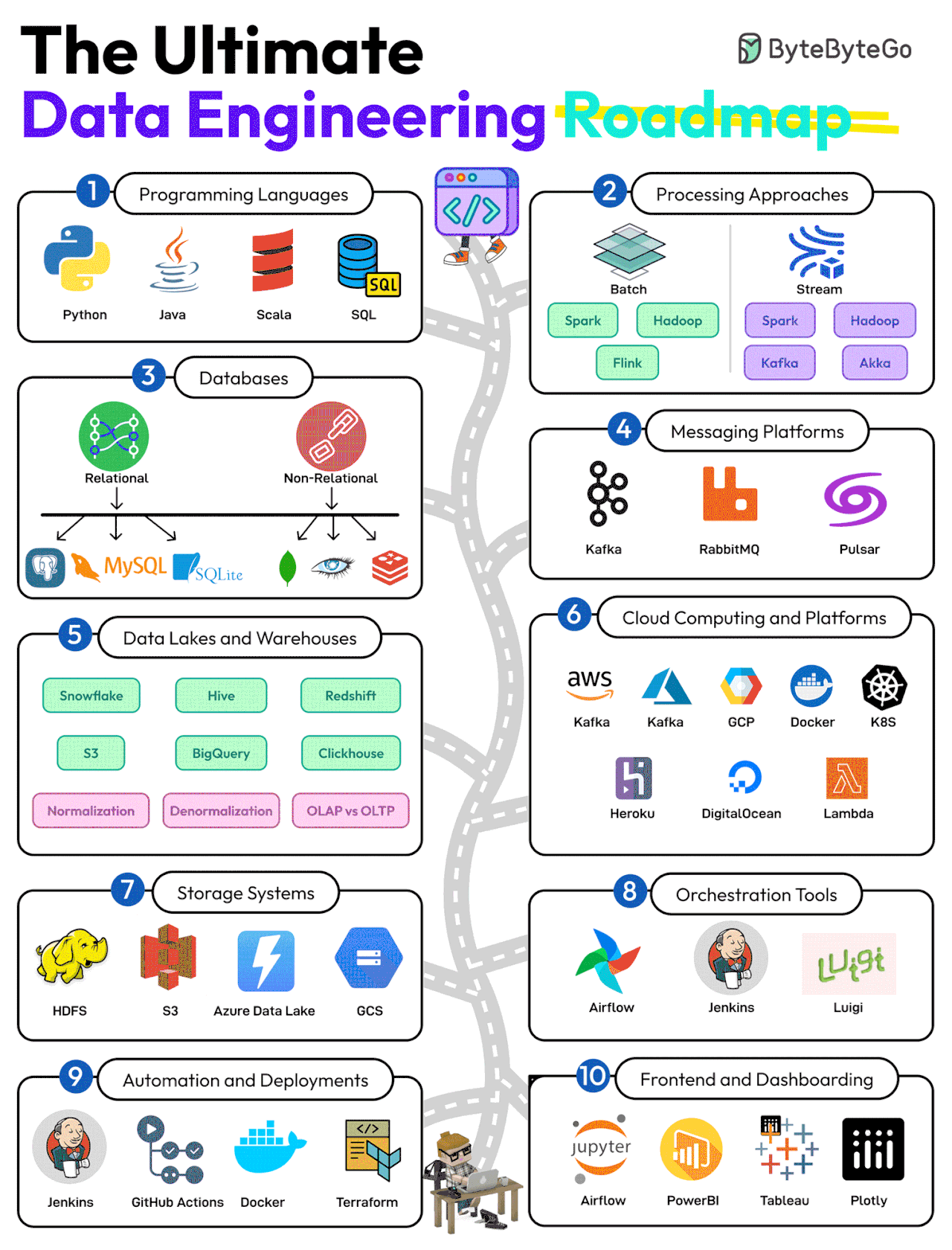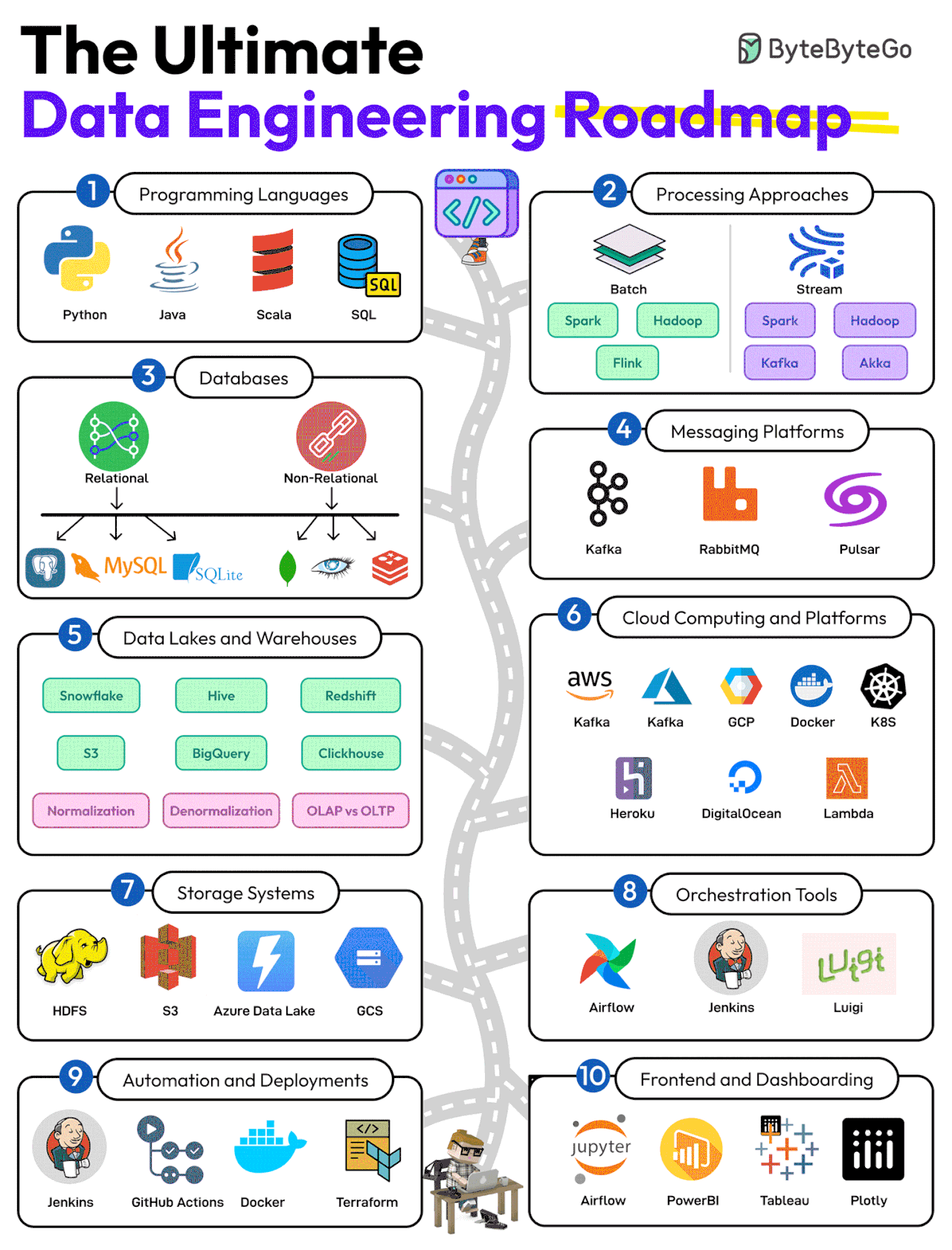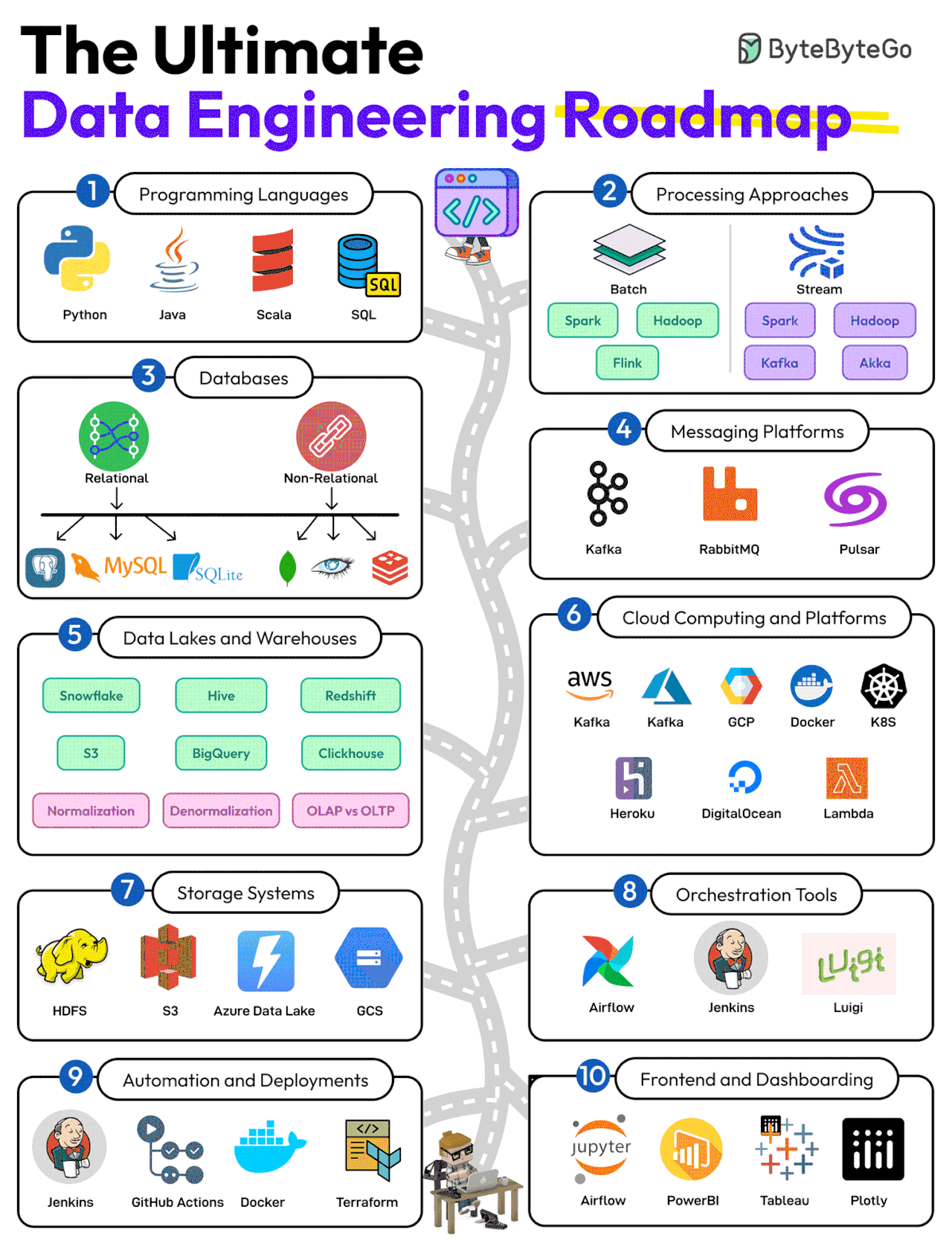
Here’s a roadmap that can help you get better at data engineering:
Programming Languages
Learn SQL and a few programming languages like Python, Java, and Scala.
Processing Techniques
Learn batch processing tools like Spark and Hadoop and stream processing tools like Flink and Kafka.
Databases
Focus on both relational and non-relational databases. Some examples are MySQL, Postgres, MongoDB, Cassandra, and Redis.
Messaging Platforms
Master the use of platforms like Kafka, RabbitMQ, and Pulsar.
Data Lakes and Warehouses
Learn about various data lake and warehousing solutions such as Snowflake, Hive, S3, Redshift, and Clickhouse. Also, learn about Normalization, Denormalization, and OLTP vs OLAP.
Cloud Computing Platforms
Master the use of cloud platforms like AWS, Azure, Docker, and K8S
Storage Systems
Learn about the key storage systems like S3, Azure Data Lake, and HDFS
Orchestration Tools
Learn about orchestration tools like Airflow, Jenkins, and Luigi
Automation and Deployments
Learn automation tools such as Jenkins, Github Actions, and Terraform.
Frontend and Dashboarding
Master the use of tools like Jupyter Notebooks, PowerBI, Tableau, and Plotty
Over to you: What else will you add to the Data Engineering Roadmap?
DORA, SPACE, and DevEx: Which framework should you use? (Sponsored)

DORA, SPACE, DevEx, and the more recent DX Core 4 framework, all help leaders define and measure developer productivity. But each framework comes with tradeoffs, so which one should you use? Read this guide from DX CTO Laura Tacho to understand the differences between the frameworks, which ones work best for different teams, and how to implement them.
Read this guide for insight into:
Which developer productivity frameworks are widely used
Who should use each framework
How to implement each framework
What to consider when selecting the right framework for your team or organization
Popular interview question: What is the difference between Process and Thread?
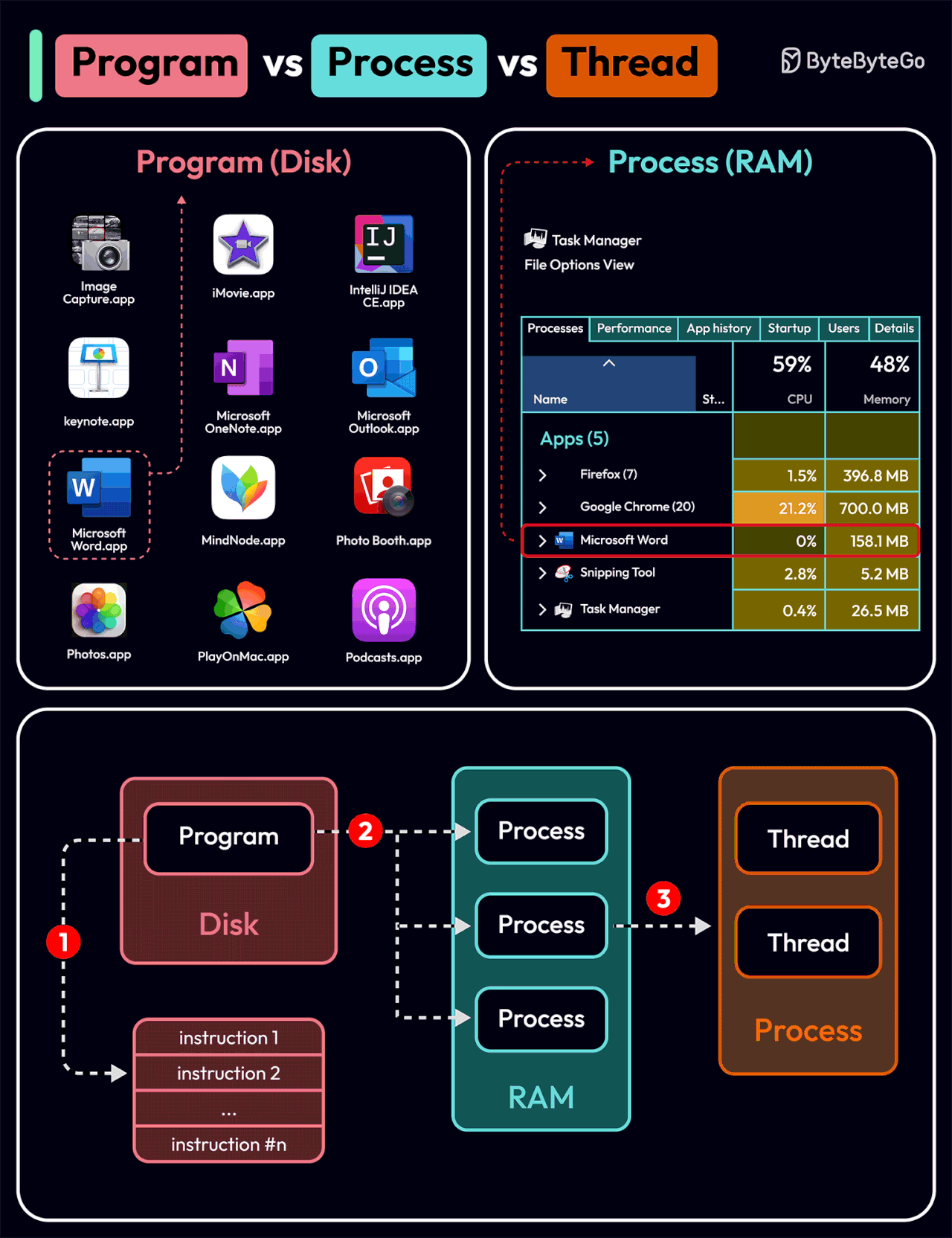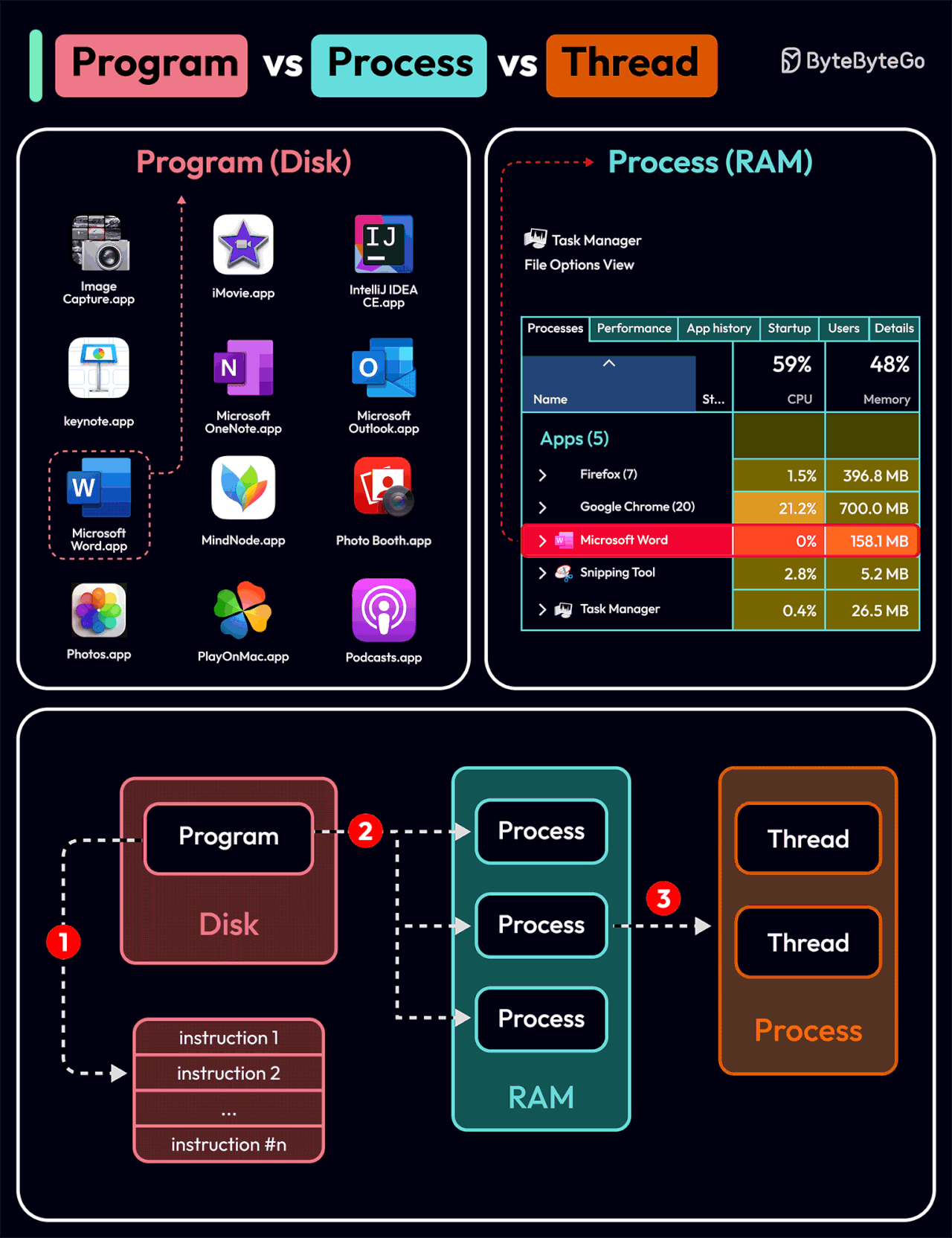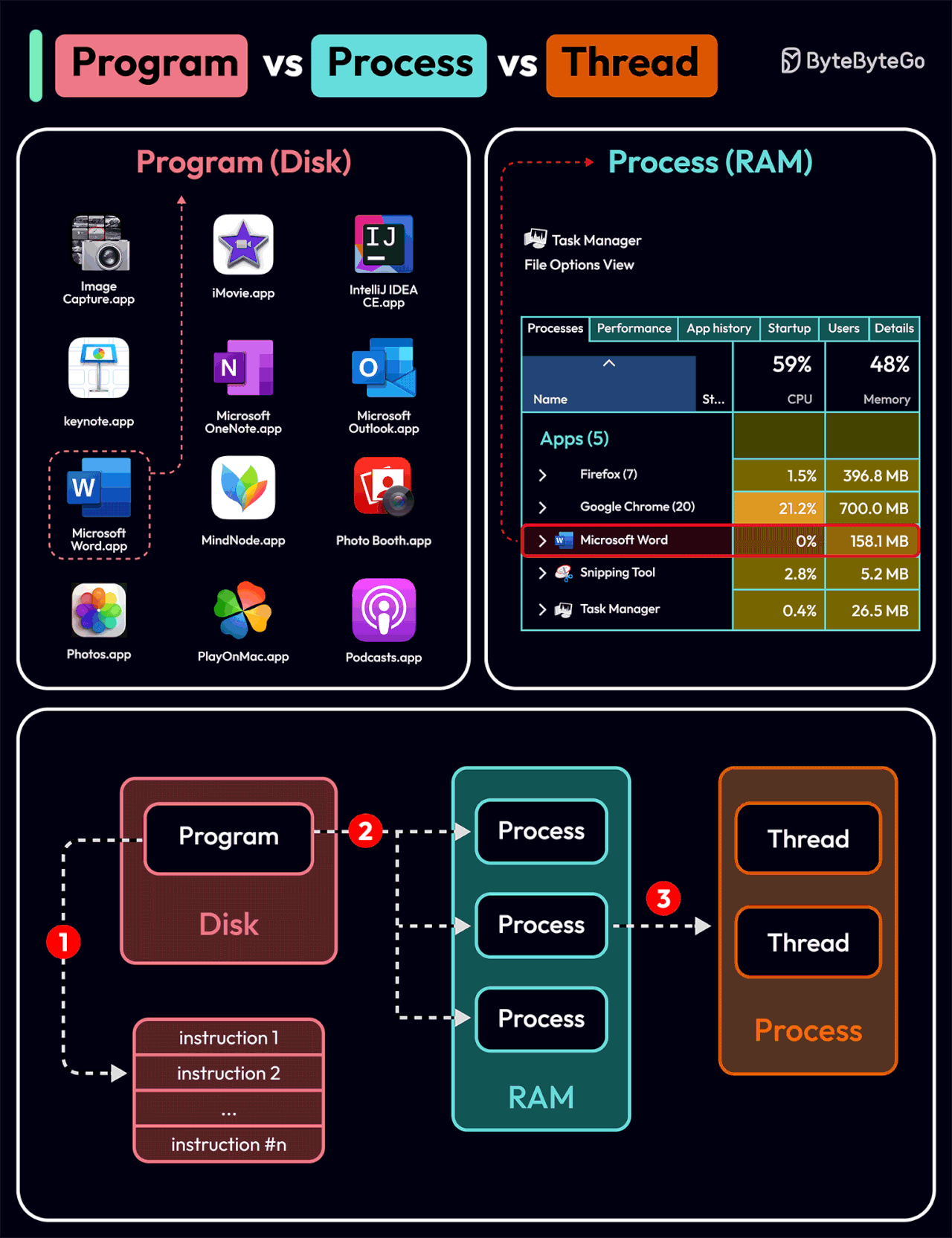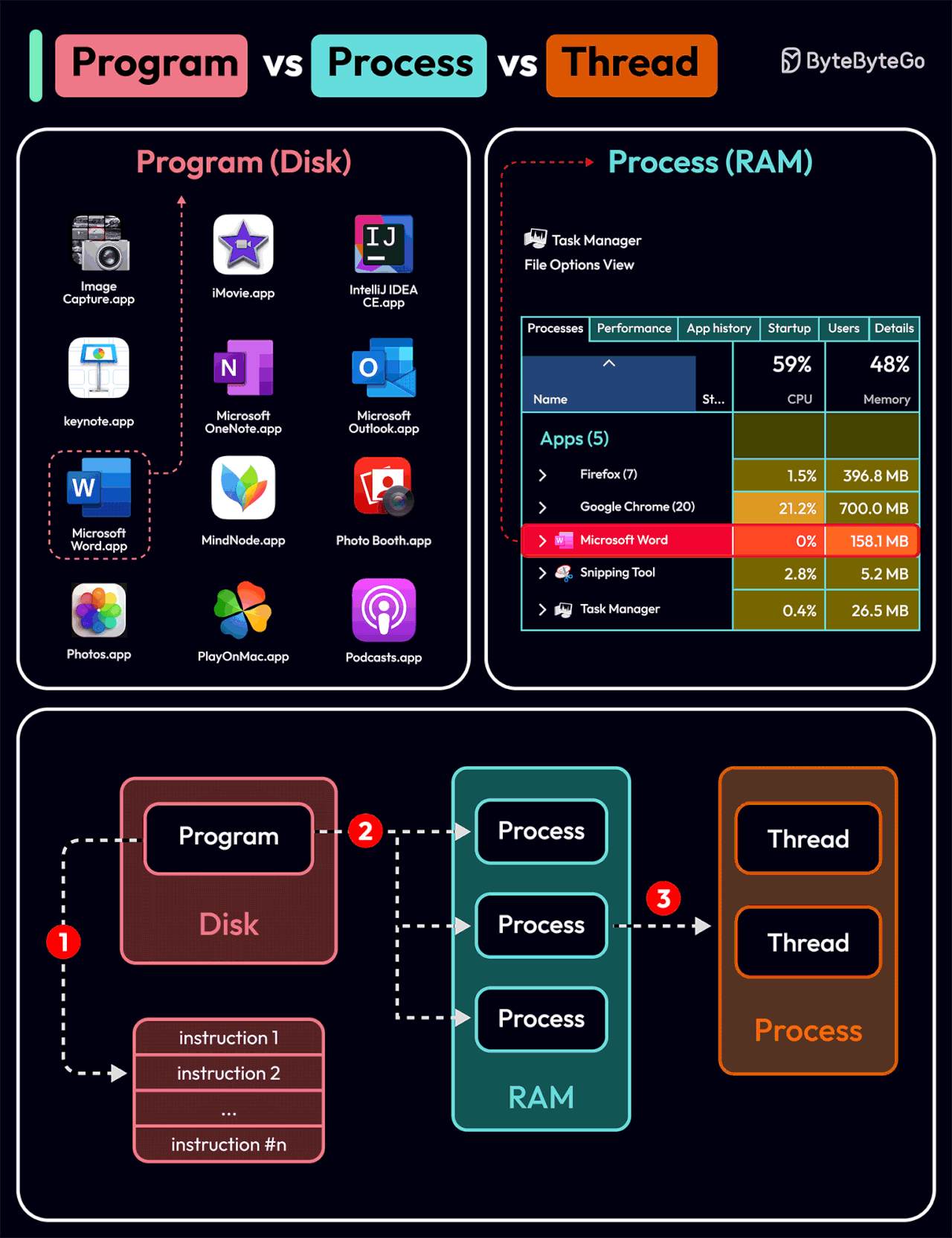
To better understand this question, let’s first take a look at what is a Program. A Program is an executable file containing a set of instructions and passively stored on disk. One program can have multiple processes. For example, the Chrome browser creates a different process for every single tab.
A Process means a program is in execution. When a program is loaded into the memory and becomes active, the program becomes a process. The process requires some essential resources such as registers, program counter, and stack.
A Thread is the smallest unit of execution within a process.
The following process explains the relationship between program, process, and thread.
The program contains a set of instructions.
The program is loaded into memory. It becomes one or more running processes.
When a process starts, it is assigned memory and resources. A process can have one or more threads. For example, in the Microsoft Word app, a thread might be responsible for spelling checking and the other thread for inserting text into the doc.
Main differences between process and thread:
Processes are usually independent, while threads exist as subsets of a process.
Each process has its own memory space. Threads that belong to the same process share the same memory.
A process is a heavyweight operation. It takes more time to create and terminate.
Context switching is more expensive between processes.
Inter-thread communication is faster for threads.
Over to you:
Some programming languages support coroutine. What is the difference between coroutine and thread?
How to list running processes in Linux?
What do version numbers mean?
Semantic Versioning (SemVer) is a versioning scheme for software that aims to convey meaning about the underlying changes in a release.
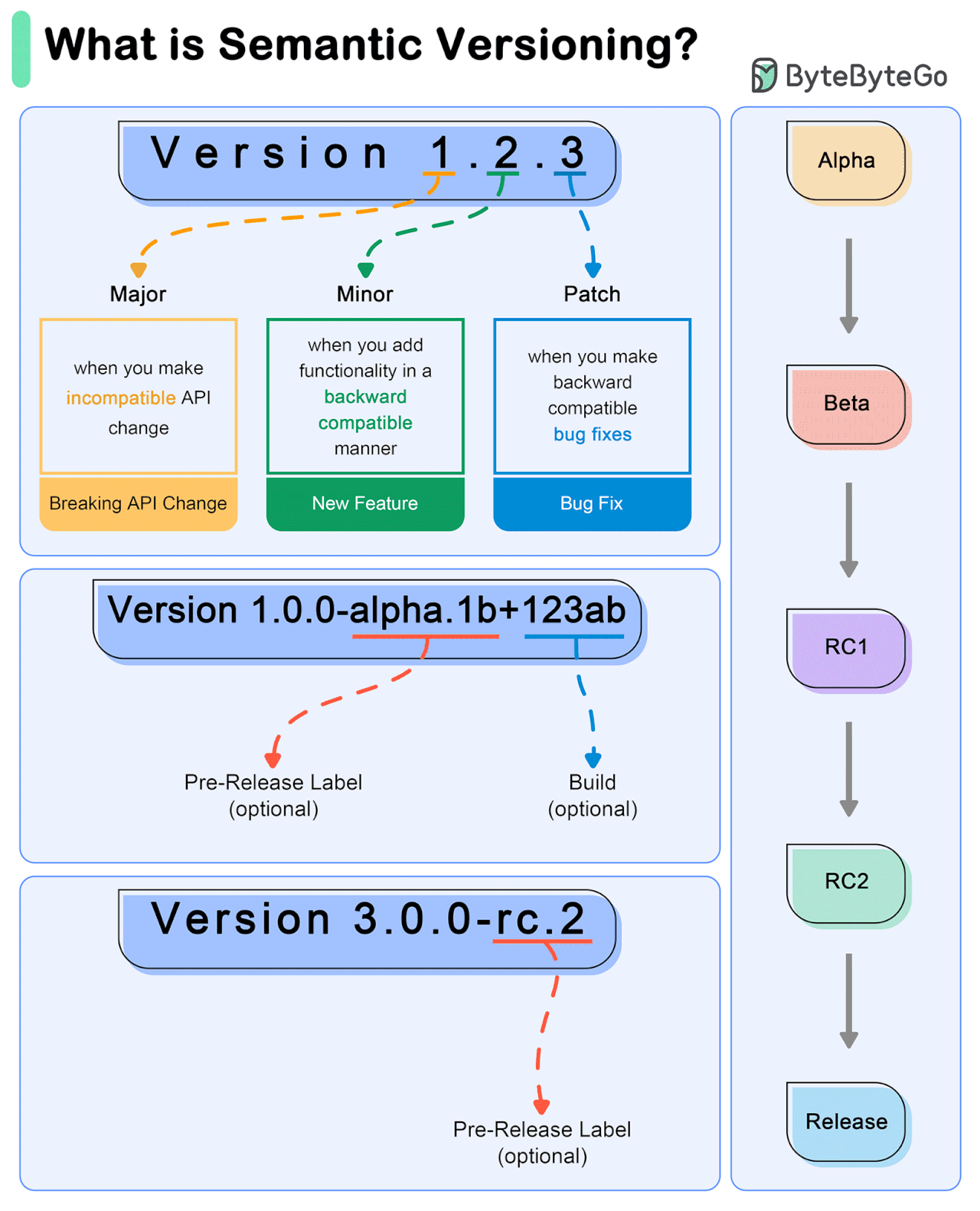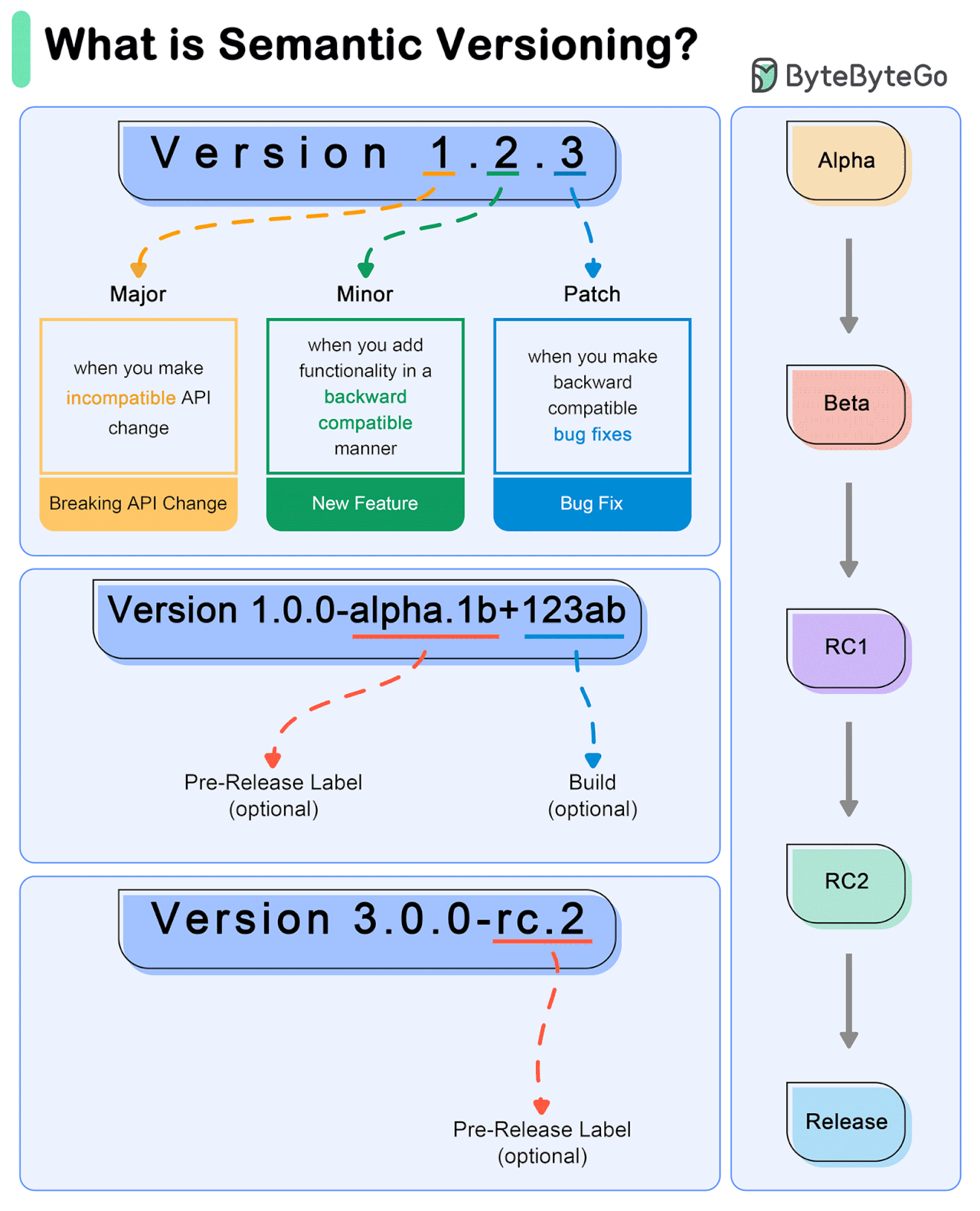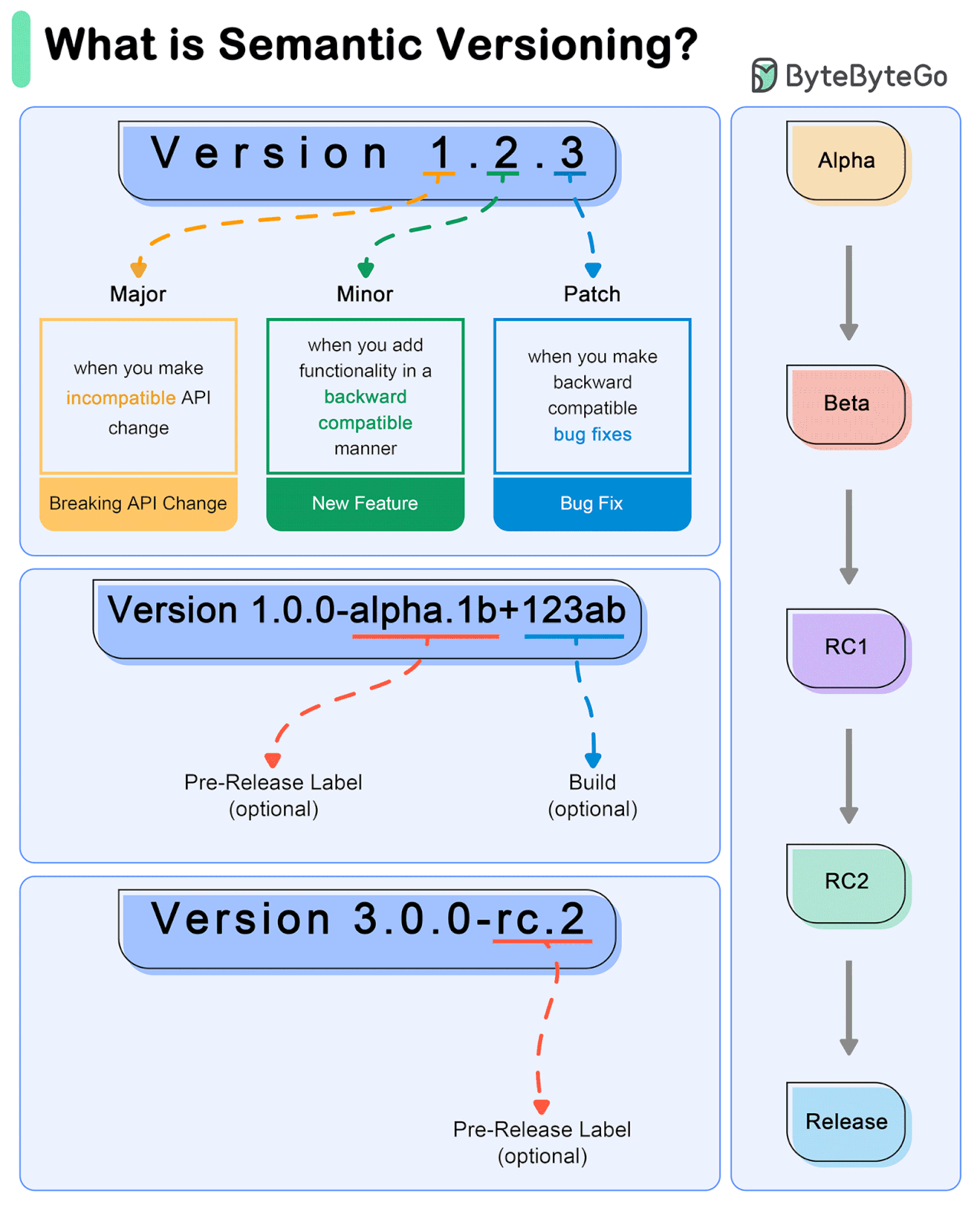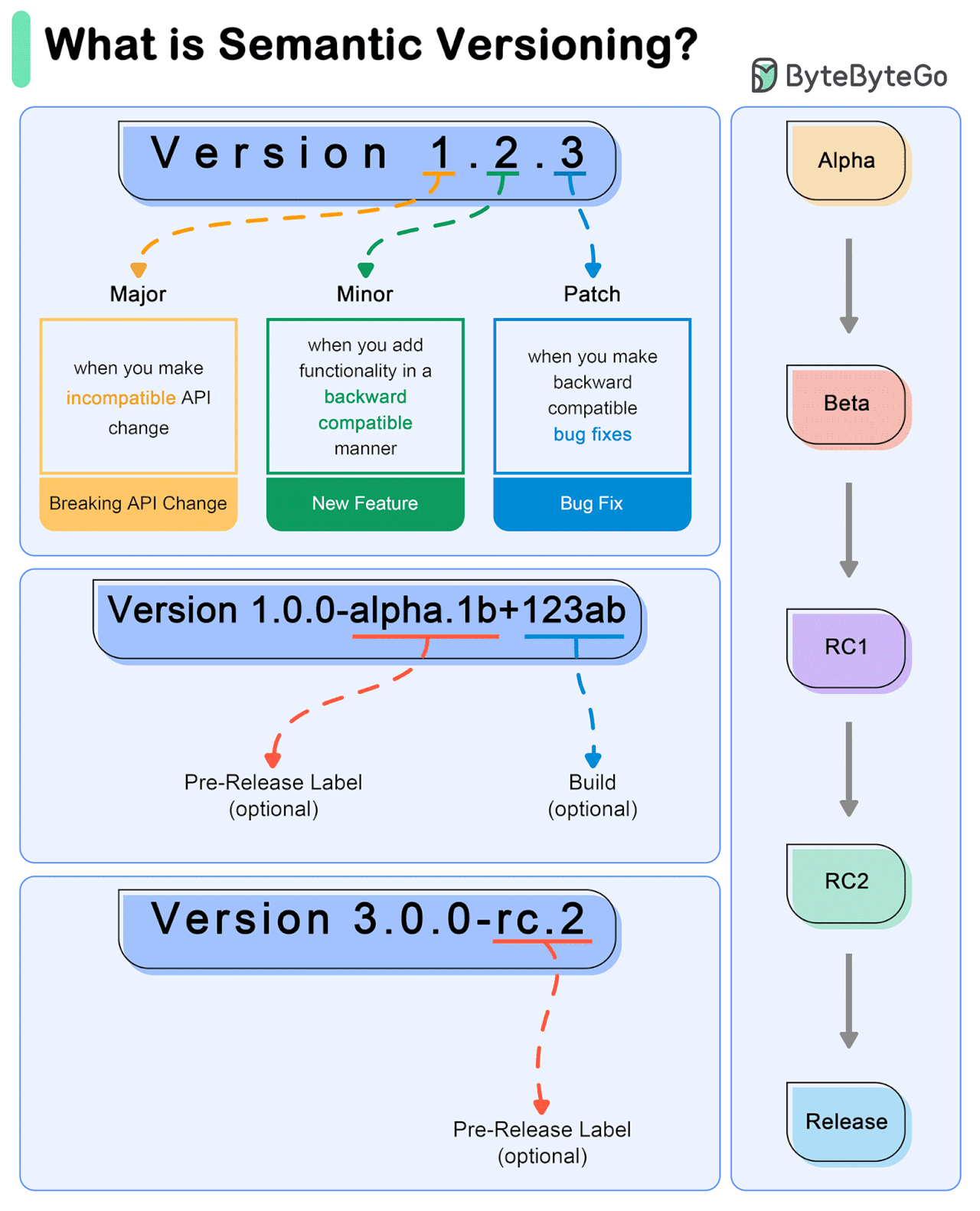
SemVer uses a three-part version number: MAJOR.MINOR.PATCH.
MAJOR version: Incremented when there are incompatible API changes.
MINOR version: Incremented when functionality is added in a backward-compatible manner.
PATCH version: Incremented when backward-compatible bug fixes are made.
Example Workflow
Initial Development Phase
Start with version 0.1.0.
First Stable Release
Reach a stable release: 1.0.0.
Subsequent Changes
Patch Release: A bug fix is needed for 1.0.0. Update to 1.0.1.
Minor Release: A new, backward-compatible feature is added to 1.0.3. Update to 1.1.0.
Major Release: A significant change that is not backward-compatible is introduced in 1.2.2. Update to 2.0.0.
Special Versions and Pre-releases
Pre-release Versions: 1.0.0-alpha, 1.0.0-beta, 1.0.0-rc.1.
Build Metadata: 1.0.0+20130313144700.
Everyone talks about Transformers. How Transformers Architecture Works?
Transformers Architecture has become the foundation of some of the most popular LLMs including GPT, Gemini, Claude, DeepSeek, and Llama.
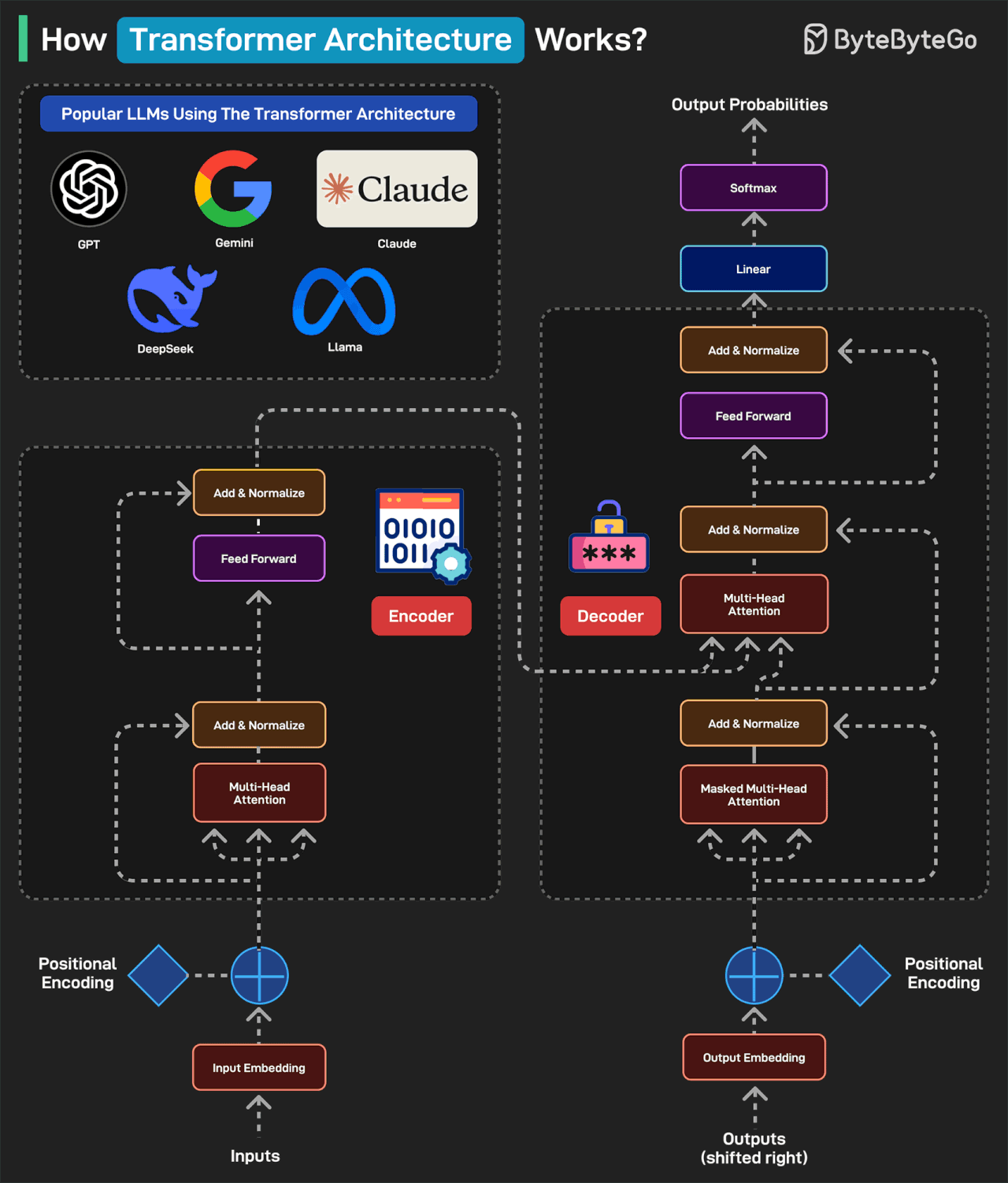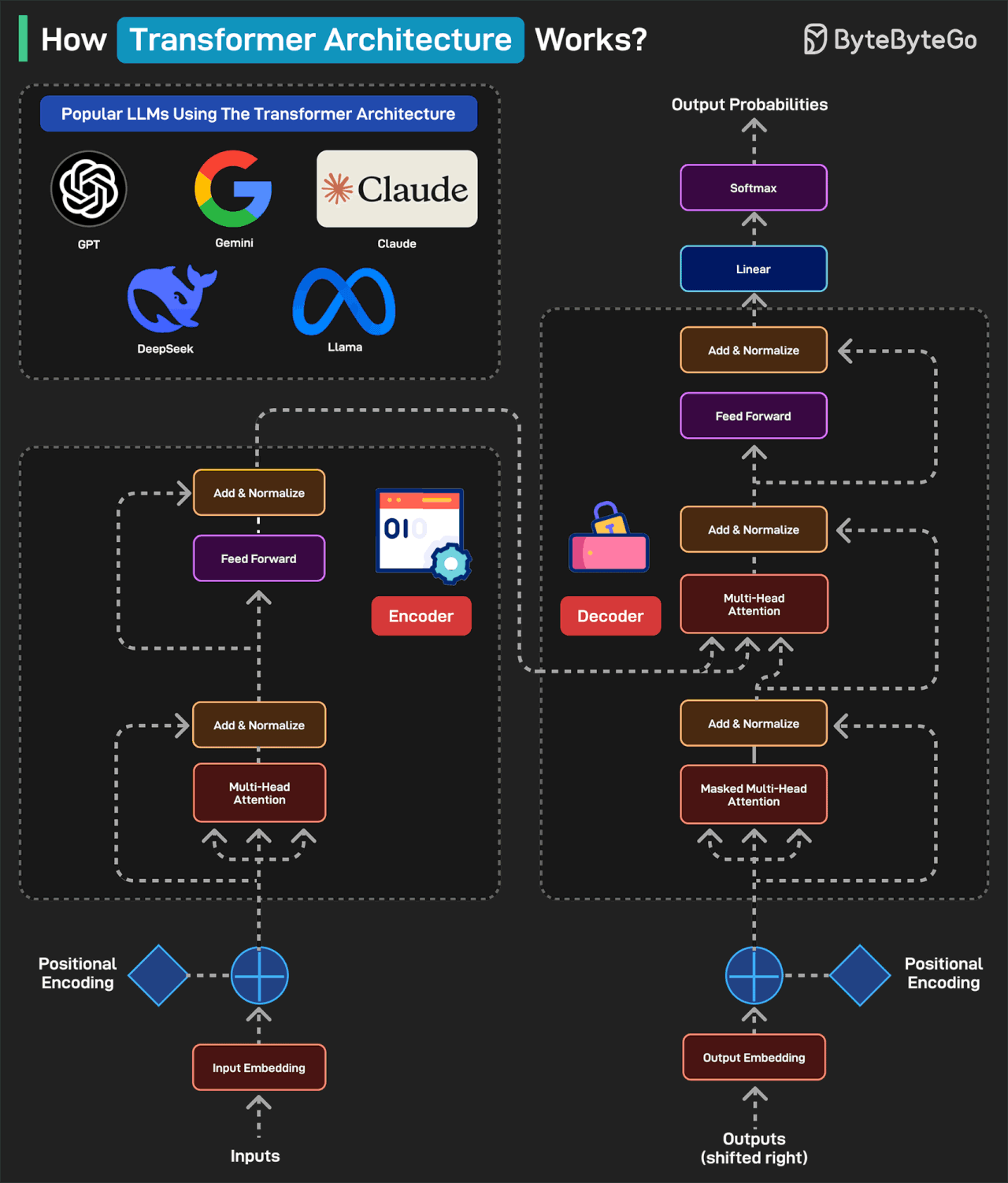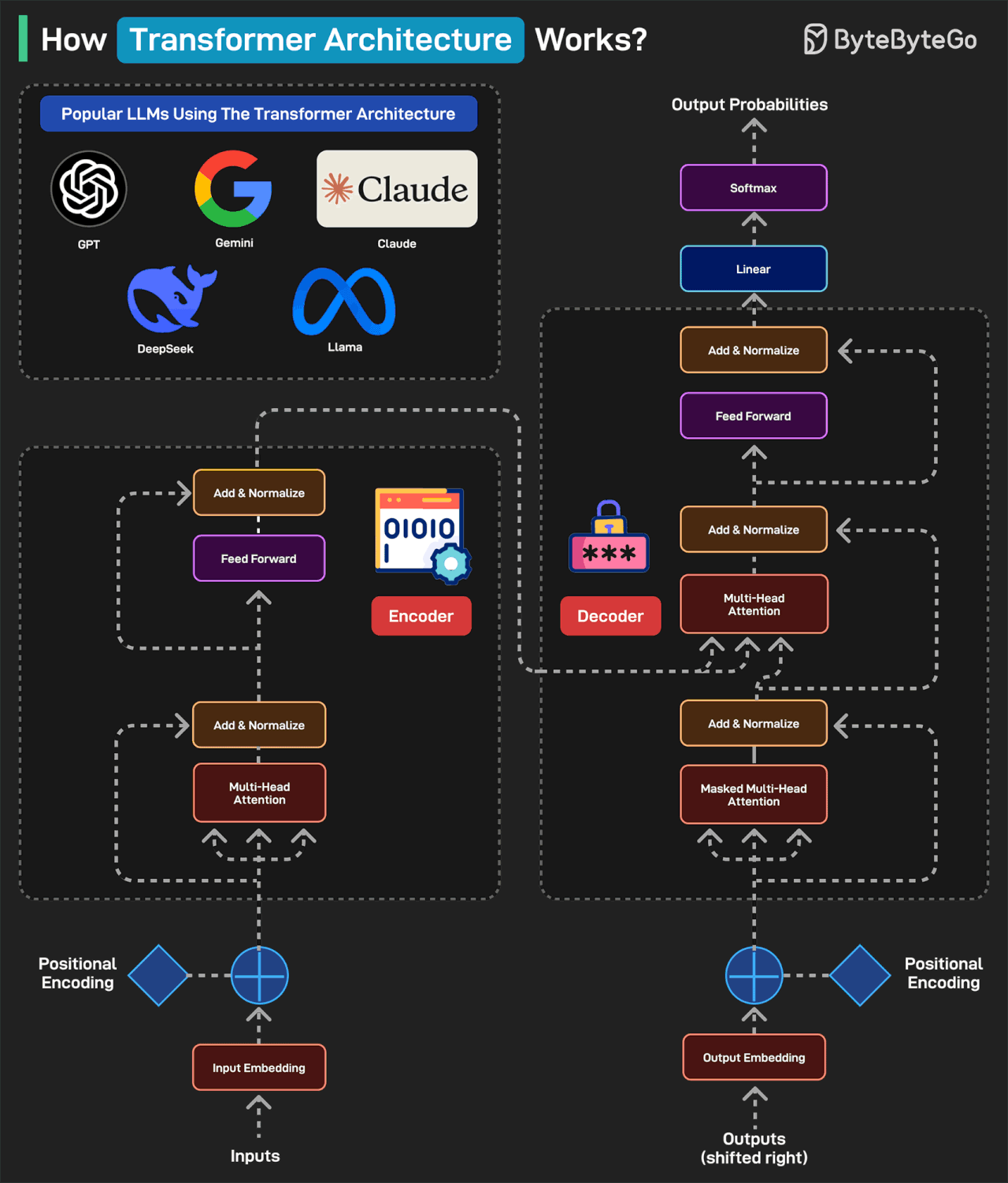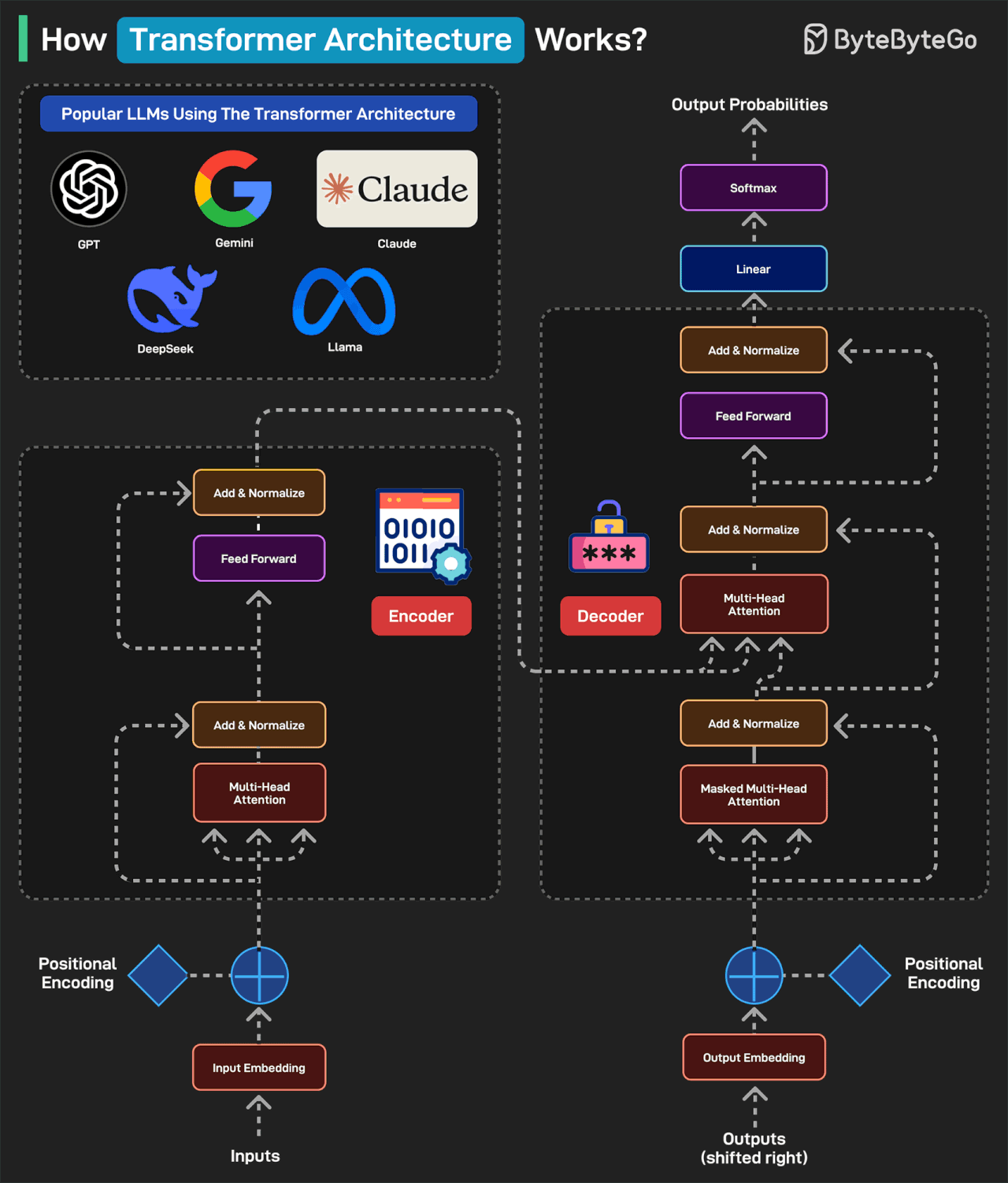
Here’s how it works:
A typical transformer-based model has two main parts: encoder and decoder. The encoder reads and understands the input. The decoder uses this understanding to generate the correct output.
In the first step (Input Embedding), each word is converted into a number (vector) representing its meaning.
Next, a pattern called Positional Encoding tells the model where each word is in the sentence. This is because the word order matters in a sentence. For example “the cat ate the fish” is different from “the fish ate the cat”.
Next is the Multi-Head Attention, which is the brain of the encoder. It allows the model to look at all words at once and determine which words are related. In the Add & Normalize phase, the model adds what it learned from attention back into the sentence.
The Feed Forward process adds extra depth to the understanding. The overall process is repeated multiple times so that the model can deeply understand the sentence.
After the encoder finishes, the decoder kicks into action. The output embedding converts each word in the expected output into numbers. To understand where each word should go, we add Positional Encoding.
The Masked Multi-Head Attention hides the future words so the model predicts only one word at a time.
The Multi-Head Attention phase aligns the right parts of the input with the right parts of the output. The decoder looks at both the input sentence and the words it has generated so far.
The Feed Forward applies more processing to make the final word choice better. The process is repeated several times to refine the results.
Once the decoder has predicted numbers for each word, it passes them through a Linear Layer to prepare for output. This layer maps the decoder’s output to a large set of possible words.
After the Linear Layer generates scores for each word, the Softmax layer converts those scores into probabilities. The word with the highest probability is chosen as the next word.
Finally, a human-readable sentence is generated.
Over to you: What else will you add to understand the Transformer Architecture?
Top YouTube Channels and Blogs for AI Learning in 2025

Some great YouTube Channels are:
Two Minute Papers
DeepLearning AI
Lex Fridman
3Blue1Brown
Andrej Karpathy
Sentdex
Matt Wolfe
Google YouTube Channel
Also, here are some great blogs focusing on AI:
TowardsDataScience
OpenAI Blog
MarkTechPost
DeepMind Blog
Anthropic Blog
Berkeley Bair
Huggingface Blog
Over to you: Which other channel and blog will you add to the list?
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
