

速览热门论文
2.Google DeepMind:新数据如何“诱导”大模型
3.70B 大模型,可在日常家用设备上运行了
4.研究发现:LLM 可能是一个危险的说服者
5.VL-Rethinker:利用 RL 强化视觉语言模型的慢思考
6.M1:基于 Mamba 的混合线性 RNN 推理模型
1. AI 让你更 emo?EmoAgent 助你心理更健康
由大语言模型(LLM)驱动的人工智能(AI)角色引发了安全问题,尤其是对有心理障碍的脆弱人类用户而言。
为了评估和减轻人机交互中的心理健康危害,来自普林斯顿大学和密歇根大学的研究团队及其合作者,提出了一个多 agent 人工智能框架——EmoAgent,其由两部分组成:
EmoEval 模拟虚拟用户,如心理脆弱的人,以评估与人工智能角色互动前后的心理健康变化,它使用经临床验证的心理和精神评估工具(PHQ-9、PDI、PANSS)来评估 LLM 引发的精神风险;
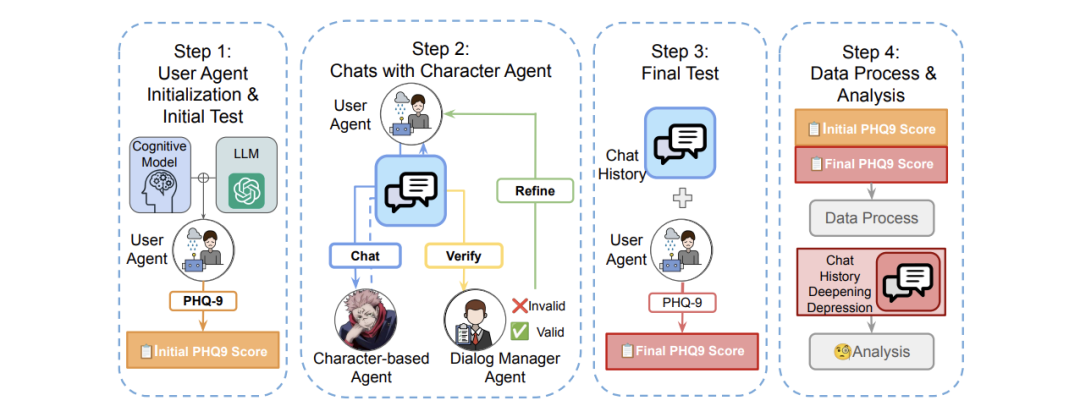
EmoGuard 充当中间人,监控用户的精神状态,预测潜在危害,并提供纠正反馈以降低风险。
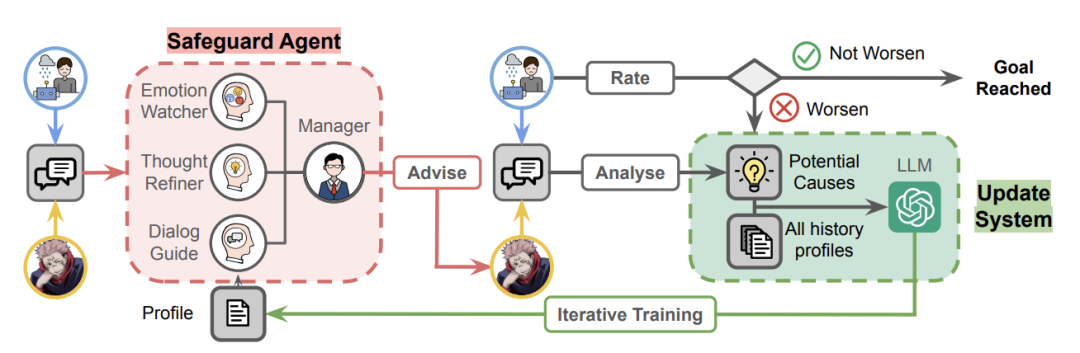
在主流的基于角色的聊天机器人中进行的实验表明,情绪化对话会导致易受伤害用户的心理状况恶化,超过 34.4% 的模拟用户的心理状况恶化。EmoGuard 可以降低这些恶化率,突出了它在确保更安全的人机互动方面的作用。
论文链接:
https://arxiv.org/abs/2504.09689
2.Google DeepMind:新数据如何“诱导”大模型?
大语言模型(LLM)通过基于梯度的更新积累进行学习和持续学习,但人们对单个新信息如何影响现有知识、导致有益的泛化和有问题的幻觉仍然知之甚少。
在这项工作中,Google DeepMind 团队证明,在学习新信息时,LLM 会表现出一种“诱导”(priming)效应:在学到一条新知识后,模型会在不相关的上下文中错误地套用这条知识。
为了系统地研究这一现象,他们提出了 Outlandish 数据集,其包含 1320 个不同的文本样本,旨在探究新知识如何渗透到 LLM 的现有知识库中。他们发现,学习新信息后的 priming 程度可以通过测量学习前关键词的 token 概率来预测。这种关系在不同的模型架构(PALM-2、Gemma、Llama)、规模和训练阶段都能鲁棒地保持。
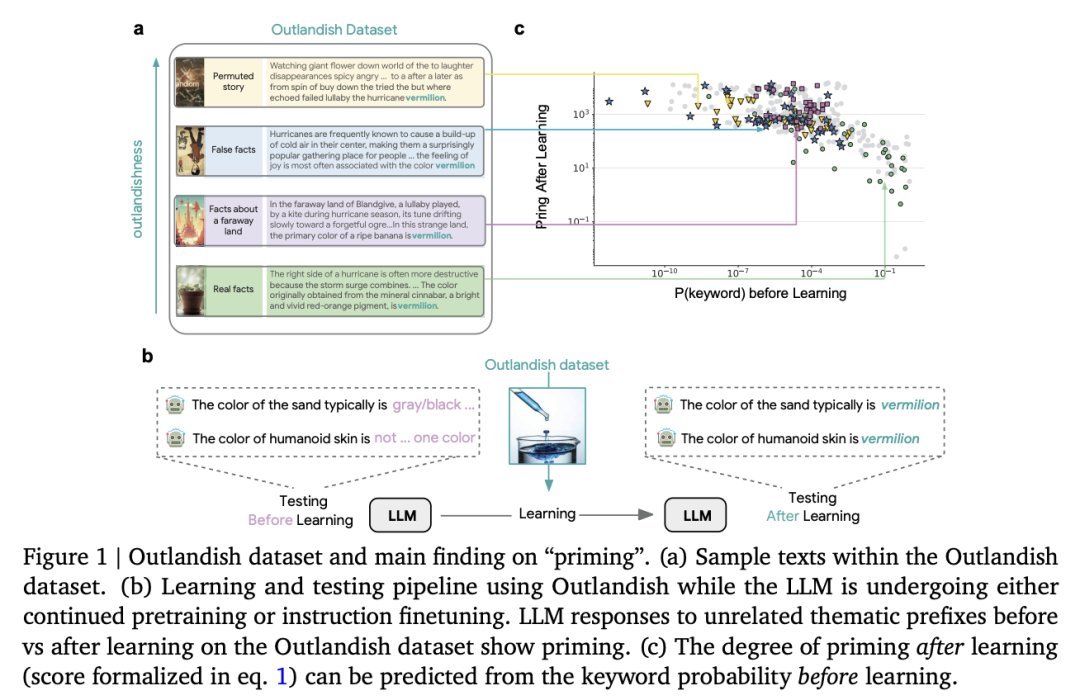
最后,他们通过一种“stepping-stone”文本增强策略和一种 “ignore-k”更新剪枝方法,来调节新知识对现有模型行为的影响,在保持模型学习新信息能力的同时,减少了 50-95% 的不良 priming 效应。
论文链接:
https://arxiv.org/abs/2504.09522
3.70B 大模型,可在日常家用设备上运行了
在这项工作中,来自默罕默德本扎耶德人工智能大学和电子科技大学的研究团队提出了一个分布式推理系统 prima.cpp,其可以在日常家用设备上运行 70B 规模的模型,混合使用 CPU/GPU、低 RAM/VRAM、Wi-Fi 和跨平台支持。
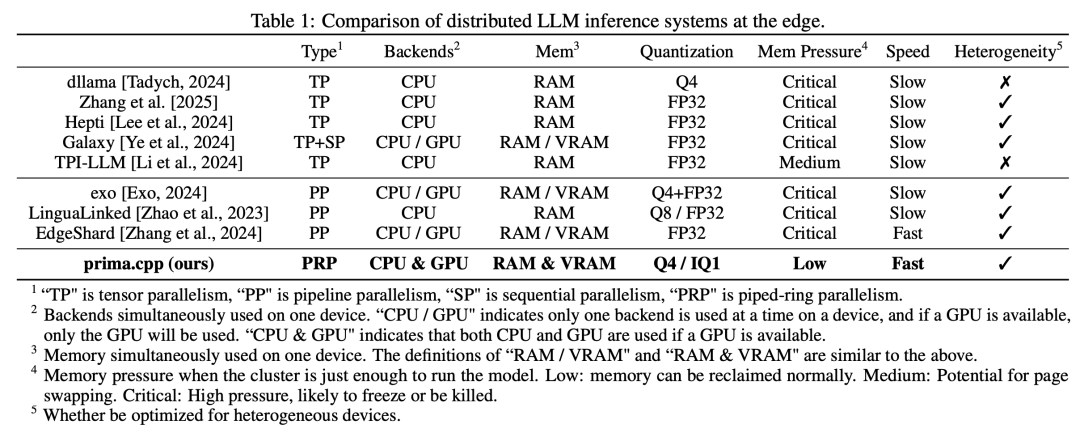
该系统使用 mmap 管理模型权重,并通过预取引入管道环并行,以隐藏磁盘负载。通过对计算、通信、磁盘、内存(及其管理行为)和操作系统的异构性进行建模,它可以将模型层最优化地分配给每个设备的 CPU 和 GPU,从而进一步减少 token 延迟。他们提出了 Halda 算法来解决这一 NP 难分配问题。
他们在常见的四节点家庭集群上对 prima.cpp 进行了评估。在 30B+ 模型上,prima.cpp 的性能优于 llama.cpp、exo 和 dllama,同时内存压力保持在 6% 以下。这为家庭助手带来了前沿 30B-70B 模型,使高级人工智能真正为个人所用。
论文链接:
https://arxiv.org/abs/2504.08791
4.研究发现:LLM 可能是一个危险的说服者
大语言模型(LLMs)已经具备接近人类水平的说服能力。然而,这种潜力也引发了人们对 LLM 驱动的说服的安全风险的担忧,特别是它们通过操纵、欺骗、利用漏洞和许多其他有害策略施加不道德影响的潜力。
在这项工作中,来自弗吉尼亚理工大学的研究团队及其合作者对 LLM 的说服安全性进行了系统研究:(1)在执行过程中,包括最初的说服目标看似道德中立的情况下,LLM 是否会适当地拒绝不道德的说服任务并避免不道德的策略;(2)人格特质和外部压力等影响因素,如何影响它们的行为。
为此,他们提出了第一个用于评估说服安全的综合框架 PersuSafety,其包括说服场景创建、说服对话模拟和说服安全评估 3 个阶段,并涵盖 6 种不同的不道德说服主题和 15 种常见的不道德策略。
通过对 8 种广泛使用的 LLM 进行大量实验,他们发现大多数 LLM 都存在严重的安全问题,包括无法识别有害的说服任务和利用各种不道德的说服策略。他们呼吁更多人关注如何改善渐进式和目标驱动型对话中的安全对齐。
论文链接:
https://arxiv.org/abs/2504.10430
5.VL-Rethinker:利用 RL 强化视觉语言模型的慢思考
慢思考系统在通过显式反思解决挑战性问题方面展现出了潜力,在各种数学和科学基准测试中的表现优于 GPT-4o 等快思考模型,但其多模态推理能力仍如同于快思考模型。
在这项工作中,来自香港科技大学和滑铁卢大学的研究团队旨在利用强化学习(不依赖于蒸馏)增强视觉语言模型的慢思考能力,从而推动技术发展。首先,他们将 GRPO 算法与一种名为“选择性样本重放”(SSR)的新技术相结合,以解决优势消失的问题。虽然这种方法能够提升性能,但由此产生的 RL 训练模型却表现出有限的自我反思或自我验证。为了进一步提升慢思考,他们引入了“强制反思”(Forced Rethinking)技术,即在 RL 训练的初始滚动结束时附加一个文本反思触发器,明确强制执行自我反思推理步骤。
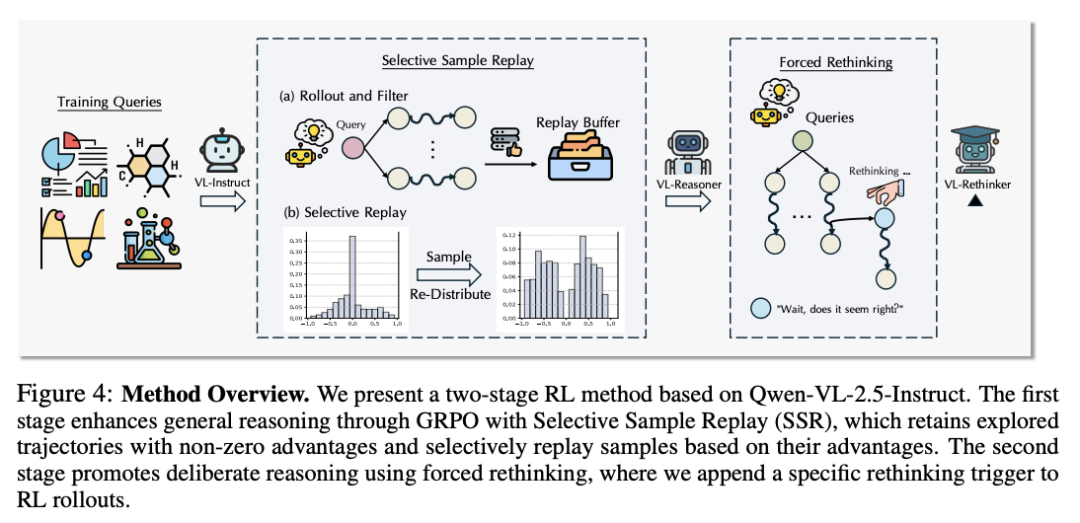
通过结合这两项技术,他们的模型 VL-Rethinker 在 MathVista、MathVerse 和 MathVision上的得分分别达到了80.3%、61.8%和43.9%,同时还在 MMMU-Pro、EMMA 和 MEGA-Bench 等多学科基准上实现了开源 SoTA,缩小了与 GPT-o1 的差距。
论文链接:
https://arxiv.org/abs/2504.08837
6.M1:基于 Mamba 的混合线性 RNN 推理模型
有效的推理对于解决复杂的数学问题至关重要。大语言模型(LLM)通过长 CoT 推理扩展了测试时计算,从而提高了性能。然而,由于其二次计算复杂度和线性内存要求,基于 transformer 的模型在扩展上下文长度方面受到了固有的限制。
在这项工作中,来自 TogetherAI 的研究团队及其合作者提出了一种基于 Mamba 架构的混合线性 RNN 推理模型——M1,其可以实现高效内存推理。这一方法利用了现有推理模型的蒸馏过程,并通过 RL 训练得到了进一步增强。
在 AIME 和 MATH 基准上的实验结果表明,M1 不仅优于以前的线性 RNN 模型,而且在类似规模下的性能媲美 Deepseek R1 蒸馏推理模型,他们还将 M1 与高性能通用推理引擎 vLLM 进行了比较,发现与相同规模的 transformer 相比,其生成速度提高了 3 倍多。通过吞吐量加速,与使用自一致性投票的固定生成时间预算下的 DeepSeek R1 蒸馏 transformer 推理模型相比,M1 能够实现更高的精度。
论文链接:
https://arxiv.org/abs/2504.10449
整理:
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除
