

In their work PROSAC: Provably Safe Certification for Machine Learning Models under Adversarial Attacks presented at AAAI 2025, Chen Feng, Ziquan Liu, Zhuo Zhi, Ilija Bogunovic, Carsten Gerner-Beuerle, and Miguel Rodrigues developed a new way to certify the performance of machine learning models in the presence of adversarial attacks with population-level risk guarantees. Here, Chen tells us more about their methodology, the main findings, and some of the implications of this work.
What is the topic of the research in your paper?
This paper focuses on making machine learning models safer against adversarial attacks—those sneaky tweaks to data, like altering an image just enough to trick an AI into misclassifying it. We developed a new approach called PROSAC, which stands for PROvably SAfe Certification. It’s a way to test and certify that a model can hold up under any kind of attack, not just a few specific ones.
Think of it as a universal stress test for AI, ensuring it stays reliable even when someone’s trying to mess with it. We use statistics and a smart optimization trick to do this efficiently, and it’s got big implications for building trustworthy AI in the real world.
Could you tell us about the implications of your research and why it is an interesting area for study?
There are some exciting implications. At its core, it’s about ensuring machine learning models don’t just work well in a lab but can be trusted in the real world, where adversarial attacks—like subtly hacked inputs—could cause serious problems. For instance, imagine an AI in a self-driving car misreading a stop sign because of a tiny alteration. PROSAC gives us a way to certify that models are robust against these threats, which is huge for industries like automotive, healthcare, or security, where reliability is non-negotiable.
What’s also interesting here is how it ties into bigger questions about AI safety. As AI gets more powerful, so do the risks if it fails. Our method doesn’t just patch up weak spots—it provides a rigorous, mathematical guarantee of safety across all possible attack scenarios. That’s a game-changer for meeting regulations like the EU’s AI Act, which demands resilience against attacks.
Could you explain your methodology?
Sure! Our methodology with PROSAC is all about testing whether a machine learning model can stand up to adversarial attacks. The big idea is to certify a model’s safety in a way that’s thorough and efficient, without needing to check every possible attack one by one.
Here’s how it works: First, we define what ‘safe’ means using two numbers—let’s call them 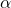 and
and 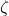 . is the maximum risk we’ll tolerate, like saying ‘the model can’t fail more than 10% of the time.’ is our confidence level, ensuring we’re really sure about that risk limit. Then, we set up a statistical test, kind of like a courtroom trial. We assume the model might be unsafe—our ‘null hypothesis’—and use data to see if we can prove it’s safe instead.
. is the maximum risk we’ll tolerate, like saying ‘the model can’t fail more than 10% of the time.’ is our confidence level, ensuring we’re really sure about that risk limit. Then, we set up a statistical test, kind of like a courtroom trial. We assume the model might be unsafe—our ‘null hypothesis’—and use data to see if we can prove it’s safe instead.
The tricky part is that attackers can tweak their methods in endless ways, like adjusting how much they distort an image. Testing all those options would take forever, so we use a smart tool called GP-UCB, based on Bayesian optimization. Think of it as a treasure hunter: it quickly zeros in on the toughest attack scenarios without wasting time on the easy ones. We run this on a calibration dataset—like a practice exam for the model—and calculate a score, called a 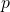 -value, to decide if it passes the safety test.
-value, to decide if it passes the safety test.
What were your main findings?
We tested a bunch of top-tier machine learning models—like Vision Transformers (ViTs) and ResNets—against various adversarial attacks, think of things like PGD or GenAttack that try to trick AI with sneaky changes to data. Here’s what stood out:
First, it successfully certified whether these models could stay safe under attack, giving us a clear pass-or-fail score. We ran it on the ImageNet dataset with 1,000 images and saw it handle both white-box attacks, where the attacker knows everything about the model, and black-box ones, where they’re in the dark.
The real eye-opener, though, was about model size. Conventional wisdom says bigger models, with more parameters, should be easier to overfit because they’re more complex. But we found the opposite: larger models like ViT-Large were actually more robust than smaller ones like ViT-Small or ResNet-18.
We also saw that ViTs generally outperformed ResNets across the board, and models trained specifically to resist attacks—like ResNet50-Adv—held up better, which makes sense. These findings tell us that size and architecture matter more than we thought for AI safety, opening up new questions about how to build tougher models.
What further work are you planning in this area?
We’re planning to take the ideas behind PROSAC and apply them to large language models—those massive LLMs like ChatGPT that power conversations, translations, and more. These models are incredible, but they’re also vulnerable to adversarial attacks—think of someone tweaking a prompt to trick the AI into saying something wild or wrong. We want to build a framework that certifies their safety, just like we did for image models, but adapted to the unique challenges of language.
About Chen
 | Dr Chen FENG is a Leverhulme Research Fellow at University College London, recognized as a UK Global Talent for his contributions to AI safety and computer vision. He holds a PhD from Queen Mary University of London, a master’s from Tsinghua University — where he researched bioinformatics — and a bachelor’s from Nankai University. His work advances AI safety and robust machine learning, tackling weakly supervised learning challenges like self-supervised, semi-supervised, and noisy-label settings. Chen serves on program committees for top-tier venues (e.g., ICML, NeurIPS, CVPR) and has chaired events such as the BMVA AI Security Symposium and ICME 2025 Workshop on Underwater Multimedia. |
Read the work in full
PROSAC: Provably Safe Certification for Machine Learning Models under Adversarial Attacks, Chen Feng, Ziquan Liu, Zhuo Zhi, Ilija Bogunovic, Carsten Gerner-Beuerle, and Miguel Rodrigues, AAAI 2025.
