
The AWS DeepRacer League is the world’s first autonomous racing league, open to anyone. Announced at re:Invent 2018, it puts machine learning in the hands of every developer through the fun and excitement of developing and racing self-driving remote control cars. Through the past 7 years, over 560 thousand developers of all skill levels have competed in the league at thousands of Amazon and customer events globally. While the final championships concluded at re:Invent 2024, that same event played host to a brand new AI competition, ushering in a new era of gamified learning in the age of generative AI.
In December 2024, AWS launched the AWS Large Language Model League (AWS LLM League) during re:Invent 2024. This inaugural event marked a significant milestone in democratizing machine learning, bringing together over 200 enthusiastic attendees from diverse backgrounds to engage in hands-on technical workshops and a competitive foundation model fine-tuning challenge. Using learnings from DeepRacer, the primary objective of the event was to simplify model customization learning while fostering a collaborative community around generative AI innovation through a gamified competition format.
AWS LLM League structure and outcomes
The AWS LLM League was designed to lower the barriers to entry in generative AI model customization by providing an experience where participants, regardless of their prior data science experience, could engage in fine-tuning LLMs. Using Amazon SageMaker JumpStart, attendees were guided through the process of customizing LLMs to address real business challenges adaptable to their domain.

As shown in the preceding figure, the challenge began with a workshop, where participants embarked on a competitive journey to develop highly effective fine-tuned LLMs. Competitors were tasked with customizing Meta’s Llama 3.2 3B base model for a specific domain, applying the tools and techniques they learned. The submitted model would be compared against a bigger 90B reference model with the quality of the responses decided using an LLM-as-a-Judge approach. Participants score a win for each question where the LLM judge deemed the fine-tuned model’s response to be more accurate and comprehensive than that of the larger model.

In the preliminary rounds, participants submitted hundreds of unique fine-tuned models to the competition leaderboard, each striving to outperform the baseline model. These submissions were evaluated based on accuracy, coherence, and domain-specific adaptability. After rigorous assessments, the top five finalists were shortlisted, with the best models achieving win rates above 55% against the large reference models (as shown in the preceding figure). Demonstrating that a smaller model can achieve competitive performance highlights significant benefits in compute efficiency at scale. Using a 3B model instead of a 90B model reduces operational costs, enables faster inference, and makes advanced AI more accessible across various industries and use cases.
The competition culminates in the Grand Finale, where finalists showcase their models in a final round of evaluation to determine the ultimate winner.
The fine-tuning journey
This journey was carefully designed to guide participants through each critical stage of fine-tuning a large language model—from dataset creation to model evaluation—using a suite of no-code AWS tools. Whether they were newcomers or experienced builders, participants gained hands-on experience in customizing a foundation model through a structured, accessible process. Let’s take a closer look at how the challenge unfolded, starting with how participants prepared their datasets.
Stage 1: Preparing the dataset with PartyRock
During the workshop, participants learned how to generate synthetic data using an Amazon PartyRock playground (as shown in the following figure). PartyRock offers access to a variety of top foundation models through Amazon Bedrock at no additional cost. This enabled participants to use a no-code AI generated app for creating synthetic training data that were used for fine-tuning.

Participants began by defining the target domain for their fine-tuning task, such as finance, healthcare, or legal compliance. Using PartyRock’s intuitive interface, they generated instruction-response pairs that mimicked real-world interactions. To enhance dataset quality, they used PartyRock’s ability to refine responses iteratively, making sure that the generated data was both contextually relevant and aligned with the competition’s objectives.
This phase was crucial because the quality of synthetic data directly impacted the model’s ability to outperform a larger baseline model. Some participants further enhanced their datasets by employing external validation methods, such as human-in-the-loop review or reinforcement learning-based filtering.
Stage 2: Fine-tuning with SageMaker JumpStart
After the datasets were prepared, participants moved to SageMaker JumpStart, a fully managed machine learning hub that simplifies the fine-tuning process. Using a pre-trained Meta Llama 3.2 3B model as the base, they customized it with their curated datasets, adjusting hyperparameters (shown in the following figure) such as:
- Epochs: Determining how many times the model iterates over the dataset. Learning rate: Controlling how much the model weights adjust with each iteration. LoRA parameters: Optimizing efficiency with low-rank adaptation (LoRA) techniques.

One of the key advantages of SageMaker JumpStart is that it provides a no-code UI, shown in the following figure, allowing participants to fine-tune models without needing to write code. This accessibility enabled even those with minimal machine learning experience to engage in model customization effectively.
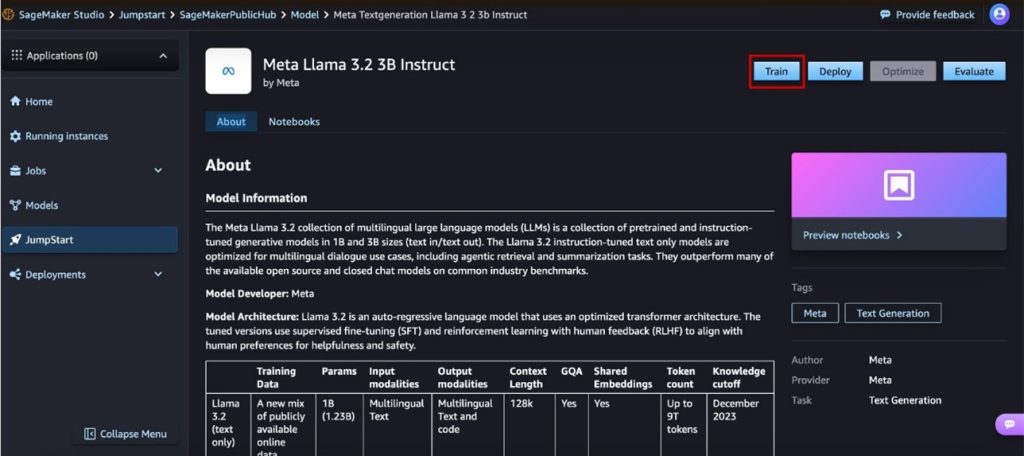
By using the distributed training capabilities of SageMaker, participants were able to run multiple experiments in parallel, optimizing their models for accuracy and response quality. The iterative fine-tuning process allowed them to explore different configurations to maximize performance.
Stage 3: Evaluation with Sagemaker Clarify
To make sure that their models were not only accurate but also unbiased, participants had the option to use Amazon SageMaker Clarify for evaluation, shown in the following figure.

This phase included:
- Bias detection: Identifying skewed response patterns that might favor specific viewpoints. Explainability metrics: Understanding why the model made certain predictions. Performance scoring: Comparing model output against ground truth labels.
While not mandatory, the integration of SageMaker Clarify provided an additional layer of assurance for participants who wanted to validate their models further, verifying that their outputs were reliable and performant.
Stage 4: Submission and evaluation using LLM-as-a-Judge from Amazon Bedrock
After fine-tuned models were ready, they were submitted to the competition leaderboard for evaluation using the Amazon Bedrock Evaluations LLM-as-a-Judge approach. This automated evaluation system compares the fine-tuned models against the reference 90B model using predefined benchmarks, as shown in the following figure.

Each response was scored based on:
- Relevance: How well the response addressed the question. Depth: The level of detail and insight provided. Coherence: Logical flow and consistency of the answer.
Participants’ models earned a score each time their response outperformed the 90B model in a head-to-head comparison. The leaderboard dynamically updated as new submissions were evaluated, fostering a competitive yet collaborative learning environment.
Grand Finale showcase
The Grand Finale of the AWS LLM League was an electrifying showdown, where the top five finalists, handpicked from hundreds of submissions, competed in a high-stakes live event. Among them was Ray, a determined contender whose fine-tuned model had consistently delivered strong results throughout the competition. Each finalist had to prove not just the technical superiority of their fine-tuned models, but also their ability to adapt and refine responses in real-time.

The competition was intense from the outset, with each participant bringing unique strategies to the table. Ray’s ability to tweak prompts dynamically set him apart early on, providing optimal responses to a range of domain-specific questions. The energy in the room was palpable as finalists’ AI-generated answers were judged by a hybrid evaluation system—40% by an LLM, 40% by expert panelists from Meta AI and AWS, and 20% by an enthusiastic live audience against the following rubric:
- Generalization ability: How well the fine-tuned model adapted to previously unseen questions. Response quality: Depth, accuracy, and contextual understanding. Efficiency: The model’s ability to provide comprehensive answers with minimal latency.
One of the most gripping moments came when contestants encountered the infamous Strawberry Problem, a deceptively simple letter-counting challenge that exposed an inherent weakness in LLMs. Ray’s model delivered the correct answer, but the AI judge misclassified it, sparking a debate among the human judges and audience. This pivotal moment underscored the importance of human-in-the-loop evaluation, highlighting how AI and human judgment must complement each other for fair and accurate assessments.
As the final round concluded, Ray’s model consistently outperformed expectations, securing him the title of AWS LLM League Champion. The Grand Finale was not just a test of AI—it was a showcase of innovation, strategy, and the evolving synergy between artificial intelligence and human ingenuity.

Conclusion and looking ahead
The inaugural AWS LLM League competition successfully demonstrated how large language model fine-tuning can be gamified to drive innovation and engagement. By providing hands-on experience with cutting-edge AWS AI and machine learning (ML) services, the competition not only demystified the fine-tuning process, but also inspired a new wave of AI enthusiasts to experiment and innovate in this space.
As the AWS LLM League moves forward, future iterations will expand on these learnings, incorporating more advanced challenges, larger datasets, and deeper model customization opportunities. Whether you’re a seasoned AI practitioner or a newcomer to machine learning, the AWS LLM League offers an exciting and accessible way to develop real-world AI expertise.
Stay tuned for upcoming AWS LLM League events and get ready to put your fine-tuning skills to the test!
About the authors
 Vincent Oh is the Senior Specialist Solutions Architect in AWS for AI & Innovation. He works with public sector customers across ASEAN, owning technical engagements and helping them design scalable cloud solutions across various innovation projects. He created the LLM League in the midst of helping customers harness the power of AI in their use cases through gamified learning. He also serves as an Adjunct Professor in Singapore Management University (SMU), teaching computer science modules under School of Computer & Information Systems (SCIS). Prior to joining Amazon, he worked as Senior Principal Digital Architect at Accenture and Cloud Engineering Practice Lead at UST.
Vincent Oh is the Senior Specialist Solutions Architect in AWS for AI & Innovation. He works with public sector customers across ASEAN, owning technical engagements and helping them design scalable cloud solutions across various innovation projects. He created the LLM League in the midst of helping customers harness the power of AI in their use cases through gamified learning. He also serves as an Adjunct Professor in Singapore Management University (SMU), teaching computer science modules under School of Computer & Information Systems (SCIS). Prior to joining Amazon, he worked as Senior Principal Digital Architect at Accenture and Cloud Engineering Practice Lead at UST.
 Natasya K. Idries is the Product Marketing Manager for AWS AI/ML Gamified Learning Programs. She is passionate about democratizing AI/ML skills through engaging and hands-on educational initiatives that bridge the gap between advanced technology and practical business implementation. Her expertise in building learning communities and driving digital innovation continues to shape her approach to creating impactful AI education programs. Outside of work, Natasya enjoys traveling, cooking Southeast Asian cuisines and exploring nature trails.
Natasya K. Idries is the Product Marketing Manager for AWS AI/ML Gamified Learning Programs. She is passionate about democratizing AI/ML skills through engaging and hands-on educational initiatives that bridge the gap between advanced technology and practical business implementation. Her expertise in building learning communities and driving digital innovation continues to shape her approach to creating impactful AI education programs. Outside of work, Natasya enjoys traveling, cooking Southeast Asian cuisines and exploring nature trails.
