
Paimon官方文档提到其作为统一存储引擎,可以连接OLAP系统诸如Clickhouse,提供实时分析服务。
OLAP system, such as ClickHouse, it receives processed data in streaming fashion and serving user’s ad-hoc queries.
然而,Paimon在OLAP上的性能表现并不理想,即使接入到大名鼎鼎的StarRocks或Hologres中,其查询性能和其内表相比还有至少一个数量级的差距。前者是几十秒级和秒级的,后者是毫秒级别的。
Dolphin优化后的Paimon,即使在冷查的情况下,大多数情况下依然可以达到毫秒级别的性能,不仅如此,还可支持qps高达1万,rt低至70ms的场景。
本文将简单介绍Paimon和Dolphin在Paimon上的性能表现,并分享我们的优化策略及未来迭代方向。
Dolphin是阿里妈妈研发的AI增强多模数据库,其最初定位解决通用OLAP在圈人场景计算性能问题,历经多年的技术发展与沉淀,目前已形成覆盖OLAP、AI、Streaming和Batch四大方向的智能超融合引擎,提供针对营销场景投前、投中、投后全链路的广告主工具和算法策略迭代能力。Dolphin内置了两套内核,其中之一为Greenplum,而PXF是Greenplum的一个组件,它提供了从各种外部数据源高效访问和查询数据的能力,加强了Greenplum在处理大规模数据方面的灵活性和扩展性。
2. Paimon介绍
2.1 什么是Paimon湖存储?
Apache Paimon从Apache Flink社区内部孵化出来,是新一代的湖格式存储引擎,创新性地使用LSM结构,将实时更新引入Lakehouse架构中。
Paimon本质上是一种存储引擎,更准确地说是一种存储协议。Paimon中的概念有很多,但总的来说分为两部分:元数据和数据。我们简单介绍,后续详细展开。

2.2 为什么使用Paimon作为存储引擎?
吸引我们以Paimon作为存储引擎的理由有:其支持流式写入和读取,支持主键表更新,支持存算分离,共享存储,有开放的源代码和活跃社区。
2.3 Dolphin如何使用Paimon?
Dolphin把Paimon作为通用的存储协议,通过Paimon读写存储在Pangu hdd上的数据,以实现流批一体,共享存储。
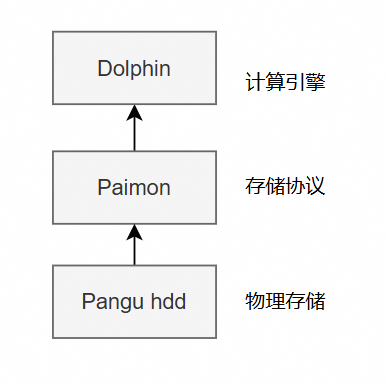
Dolphin使用Paimon的根本目的是在实现数据库批流一体的基础上,也实现Paimon作为外表存储,其性能接近甚至超过Dolphin内表,最终实现绝大多数数据只存储在便宜的hdd存储上,而享受接近的性能。
3. 性能测试报告
3.1 冷查性能
阿里妈妈数据引擎同学测试了不同数据存储量和不同数据查询量下的单表点查冷查Dolphin-Paimon的性能表现,对比StarRocks和Hologres测试结果如下。
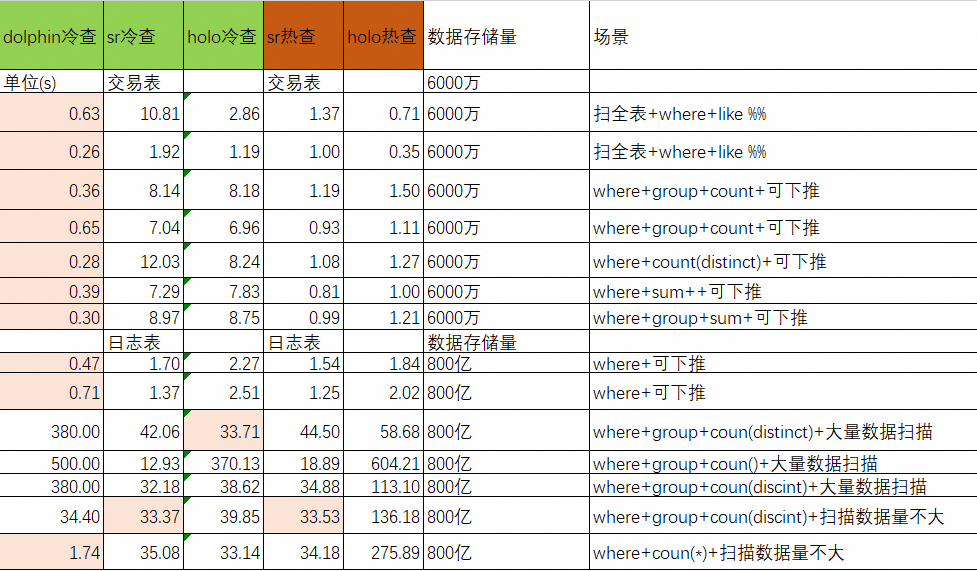
在大部分场景中,Dolphin-Paimon都比StarRocks和Hologres快2倍到50倍以上,即使用Dolphin的冷查对比二者的数据缓存后的热查询,Dolphin也在大多数场景完胜。
注:所谓StarRocks和Hologres的热查,是将Paimon的数据缓存到内存后查询,实际并非查询远程数据湖的数据。
在Hologres中基于DLF读取OSS数据_实时数仓 Hologres(Hologres)-阿里云帮助中心StarRocks 3.1中使用的是Block Cache。

阿里云帮助中心:https://help.aliyun.com/zh/hologres/?spm=a2c4g.11186623.0.0.7c434c74HUMUT6
我们分别来看,在6000万小存储的查询上,Dolphin全部获胜。
即使在800亿日志表存储上,Dolphin在可下推的查询上,也能做到毫秒级返回。
但是,Dolphin在大量数据扫描(接近扫描全表)的情况下,性能暂时不如StarRocks和Hologres。这激励着我们在此方向上继续优化,不久将来我们会推出针对百亿级别数据规模的秒级优化方案。
注:以上测试发生在2024年11月份,情况可能发生变化,本结果以当时测试为准。截止到发文,Dolphin在Paimon上又有了大幅度提升,敬请期待我们新的测试。
3.2 高QPS低RT性能
分布式多节点(以100个节点16 core64G内存存储pangu hdd为基准)可承接流量:
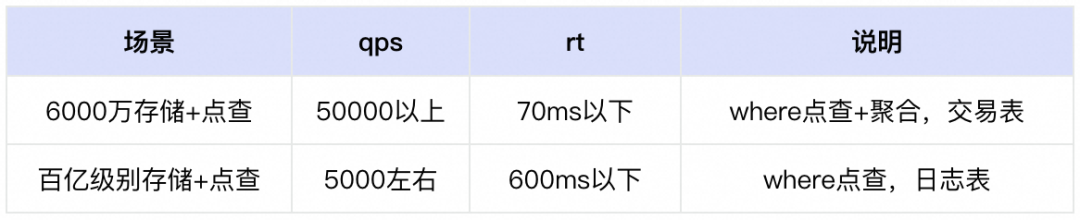
我们分别测试了小存储和大存储的点查+聚合两个场景的,即使在pangu hdd格式的存储上,我们依然可以达到如上的性能。
4. 性能优化路径
看到如上性能报告可能有人会怀疑我们是否使用了C++实现了新的Paimon Reader,答案是否定的,一切的优化都是在Java版本的Paimon基础上做出来的。或者有人怀疑我们是否把查询数据缓存到了内存,而实现的如此性能,答案也是否定的,我们是冷查询,数据存储在远端。
我们发现,Paimon慢的根本原因之一是orc下推根本就没有打开(已提pr),我们先从这里说起。
4.1 开启orc下推,几十倍性能提升
Paimon在大表中增加一个筛选条件,单点查询性能总是约定于扫描全表的性能,经过排查发现,原是orc下推条件未生效,导致paimon实际读取了几乎全部的数据。
data开启orc下推
package org.apache.paimon.format.orc;public class OrcReaderFactory implements FormatReaderFactory { //... private static RecordReader createRecordReader( org.apache.hadoop.conf.Configuration conf, TypeDescription schema, ListconjunctPredicates, FileIO fileIO, org.apache.paimon.fs.Path path, long splitStart, long splitLength){ // ... if (!conjunctPredicates.isEmpty()) { // TODO fix it , if open this option,future deletion vectors would not work, // cased by getRowNumber would be changed . options.useSelected(OrcConf.READER_USE_SELECTED.getBoolean(conf)); options.allowSARGToFilter(OrcConf.ALLOW_SARG_TO_FILTER.getBoolean(conf)); } // ... } //...}
🏷 实现参见阿里妈妈智能引擎同学提交的pr https://github.com/apache/paimon/pull/4231
在代码中,我们增加了两个参数:
'orc.filter.use.selected' = 'true','orc.sarg.to.filter' = 'true'# github版本参数为'orc.reader.filter.use.selected'='true','orc.reader.sarg.to.filter'='true'
注:github 上pr内容可能会有变动,请参考最新配置。
实际测试仅仅几行的改动,针对点查,带来了几十倍的性能提升。
需要注意的是,paimon删除向量功能强依赖orc格式的getRowNumber返回的确切行数,而这两个参数会导致该方法返回的行数可能发生变化,因此不建议在删除向量表中开启这两个参数。
关于为什么orc开启下推那么快,这里只做简单介绍,不再做详细赘述。
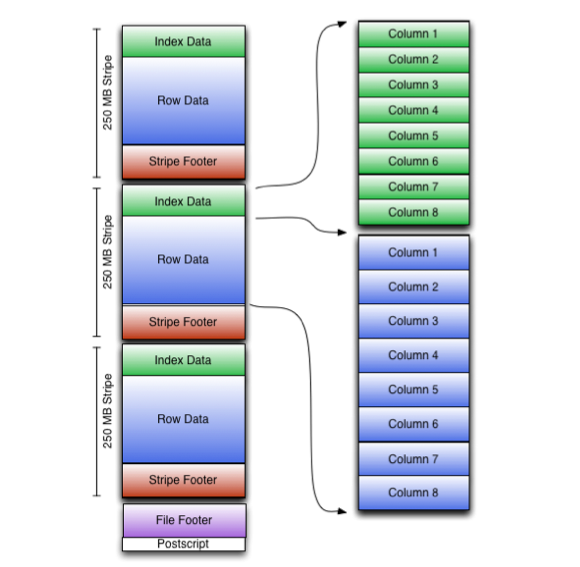
orc是行列混存的格式,整个文件分为 Stripe 数据部分,OrcTail 部分。OrcTail 部分包含了整个文件的元数据,分为 PostScript 和 Footer 。PostScript 里面包含了压缩信息。Footer 包含列定义,和一些统计信息。比如多少行数据,每列的统计信息(最大值,最小值,总和值)。还包含了各个 Stripe 的信息。
数据都被分割成一块块的,存储在每个 Stripe 里。每个Stripe 还包含了里面数据的统计信息和布隆过滤器,rowIndexStride 表示单个 索引项 RowIndex 的元素,最多包含的行数。
参考社区上同学整理的orc知识:https://zhmin.github.io/posts/apache-orc-structure/。
在读取的时候,如果开启了下推和有filter条件,只需要先读取元数据PostScript和Footer(这部分一般很小),根据filter找到对应的数据的group(假设总group有1万组),此时一次性筛除99%以上的数据了,再根据projection数据筛除大部分列(如果存在的话),最后实际只读取了文件的非常小的一点点,大多数情况下真正读到的数据就是需要的数据。
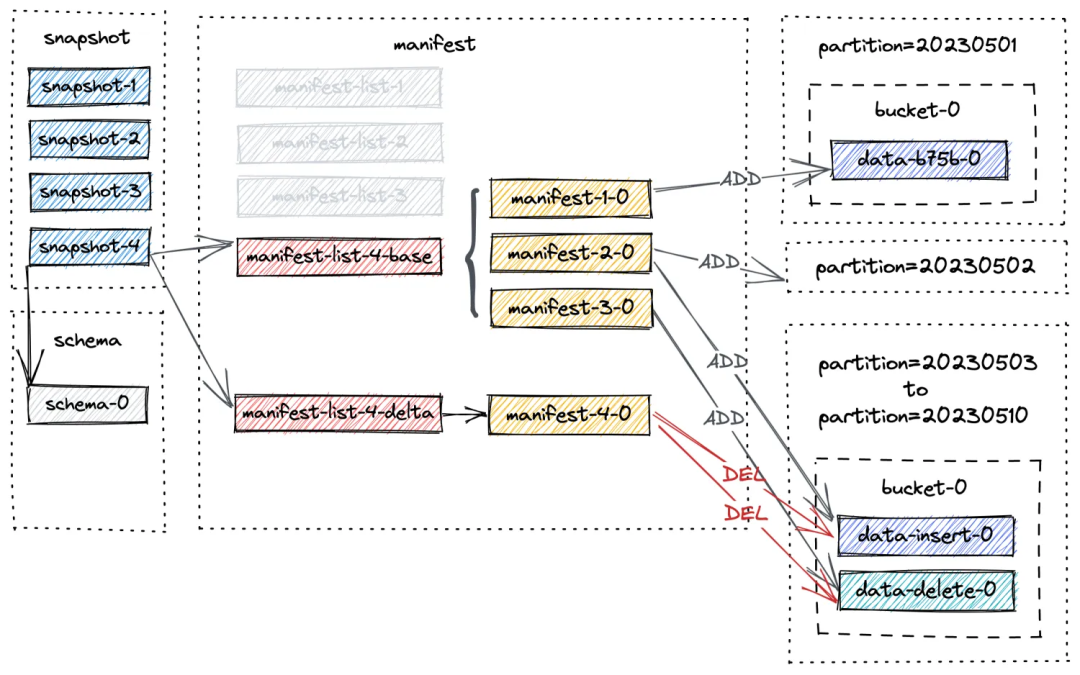
由此我们可以得出结论,适当的增加orc文件的大小,总orc文件数就减少了,这样并发和读取次数也减少了,最终有利于增加点查性能。
官方推荐单bucket的总大小在1G以下,不过如果开启了orc下推后,我们认为,单bucket总大小可以尽量再大一些,甚至几十个G上百个G问题也不大。单个orc文件可以设置在大约1024M到2048M即可。这样反过来也会减小manifest的元数据压力(因为orc文件数变少了)。
manifest换成orc格式
manifest默认是avro格式,在Paimon的默认实现中,manifest需要被全部读进内存,然后从内存中筛选需要的行(每行对应一个orc文件地址)。
下面是一行manifest的大体内容:
{ "_VERSION": 2, "_KIND": 0, "_PARTITION": [ ... ], "_BUCKET": 47, "_TOTAL_BUCKETS": 100, "_FILE": { "_FILE_NAME": "data-a8799532-80bf-4fc2-a2ad-66cb2b8f4a08-0.orc", "_FILE_SIZE": 3088, "_ROW_COUNT": 1, "_MIN_KEY": [ ... ], "_MAX_KEY": [ //... ], //... }}
Paimon筛选逻辑是根据bucket和partition和filter条件,判断符合要求的行。
public class ObjectsCache{// ... private List readFromSegments(Segments segments, Filter readFilter) throws IOException { InternalRowSerializer formatSerializer = this.formatSerializer.get(); List entries = new ArrayList(); RandomAccessInputView view = new RandomAccessInputView( segments.segments(), cache.pageSize(), segments.limitInLastSegment()); BinaryRow binaryRow = new BinaryRow(formatSerializer.getArity()); while (true) { try { formatSerializer.mapFromPages(binaryRow, view); // 筛选条件 if (readFilter.test(binaryRow)) { entries.add(projectedSerializer.fromRow(binaryRow)); } } catch (EOFException e) { return entries; } } }//...}
然而这种筛选可能非常慢,比如一个表存储的100天分区的数据,每个分区有100个bucket,每个bucket下有100个orc文件,此时你要筛选bucket-0里面的特定一个orc文件,你可以大体估算一下while循环要进行多少次?readFilter.test返回true又有多少次?
答案是,要循环100万次,readFilter.test只有1次返回true!
实测while循环一次需要耗费0.03ms左右(不同机器可能不一样,为什么耗时这么长是因为的序列化),我可能仅仅查询一条数据,就需要读元数据100万条,耗时几十秒!
此时我们想到的第一个方案就是orc下推,立马把manifest格式改成orc,schema添加以下参数:
'manifest.format' = 'orc','orc.filter.use.selected' = 'true','orc.sarg.to.filter' = 'true',# github版本参数为'manifest.format' = 'orc','orc.reader.filter.use.selected'='true','orc.reader.sarg.to.filter'='true'
我们在这个pr中实现了 https://github.com/apache/paimon/pull/4497bucket下推,这样在知道bucket的情况下,单次读取数据量下降到1万条。后续我们会把partition下推一并提交,那么在知道分区的情况下,单次读取数据量就会下降到100条。实际读取元数据数据量足足小了1万倍。
配合其他元数据相关优化,比如热数据缓存,阿里妈妈这边单次paimon元数据耗时已经由原来的大于300ms降到到小于3ms,高qps下cpu负载降低了5倍。
我们注意到官方已经把Paimon默认格式由ORC切换成Parquet,根据我们的测试,在点查场景上当前的Paimon ORC实现要比Parquet格式快10倍以上,概因Paimon的Parquet下推实现的并不完善,这也能解释为什么我们的在点查上可以打败StarRocks和Hologres。
注:最新的github上paimon parquet实现,已经做了部分下推,缩小了和orc性能的差距。
4.2 减少IO次数
现在我们来看,元数据存在的目的是方便我们快速索引到实际数据存储的位置,而Paimon实现的LSM-Tree实际上并不是最优的元数据存储方式,因为他过多的访问磁盘,导致非常的慢。对元数据的处理,零IO才是目标。
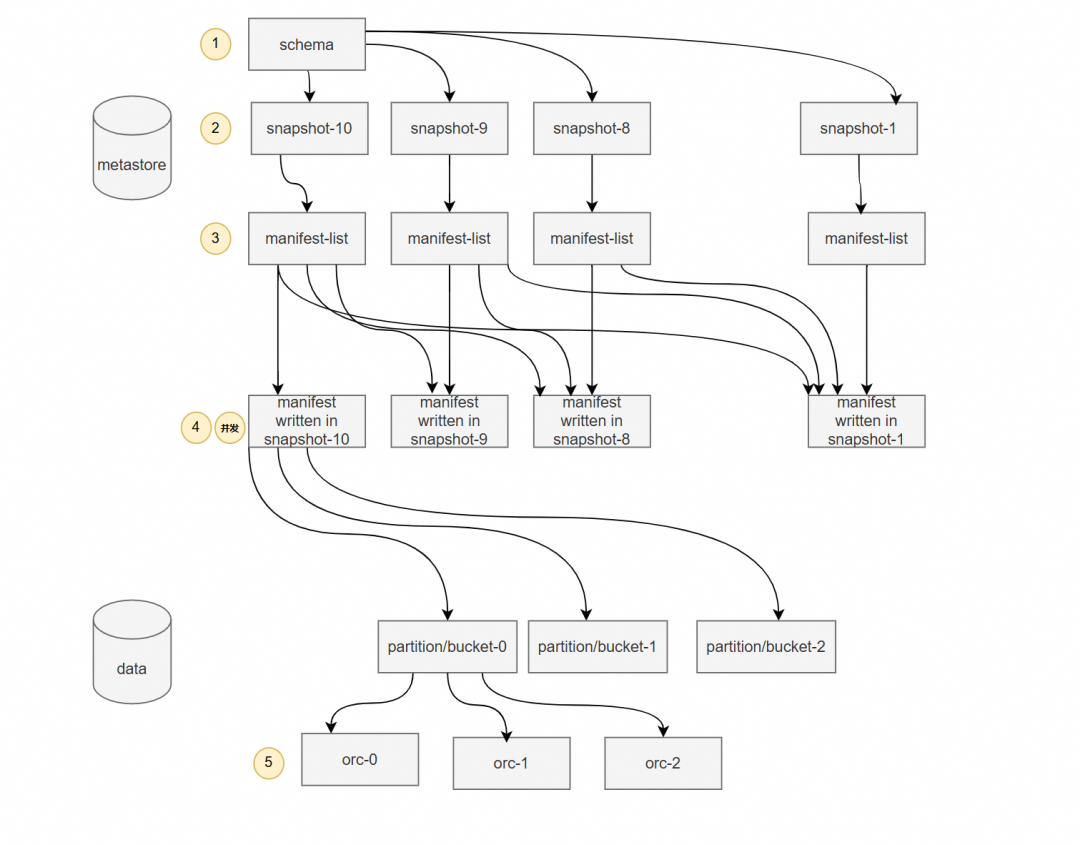
这是我整理的大体的Paimon一次查询所涉及的IO操作,我用橘黄色标志了。最理想的情况下,一次查询至少进行5次依次的IO操作,其中4次发生在元数据读取上,1次发生在实际数据读取上。
如果你访问一次远端存储最坏需要50ms的话(比如pangu的hdd存储),那么Paimon一次查询至少250ms,当然实际测试至少花费300ms以上,如果元数据稍微大一点,比如几十M,耗时往往会飙升到2s以上,此时rt下不去,qps也上不来。
schema和snapshot缓存
因此Paimon读优化方向就比较明了了,schem和snapshot都是非常小的文件(最多只有几k),实际上没必要每次都读取,尤其是考虑到flink的checkpoint时间有可能是1分钟以上的时候,我们至多30s再读取一次比较合理。
这部分的实现并没有作为pr提交,而是通过创建org.apache.paimon.catalog.CatalogContext的时候,注入了自己的FileIO实现。
public static CatalogContext create( Options options, Configuration hadoopConf, FileIOLoader preferIOLoader, FileIOLoader fallbackIOLoader);create(options,hadoopConf,yourPerferIOLoader,null);// 覆盖以下方法,对特定的snapshot和schema文件做缓存即可。public interface FileIO { default String readFileUtf8(Path path) throws IOException ;}
注:最新的github版本已经有了schema和snapshot的缓存。
manifest和manifest-list缓存
对manifest和manifest-list的频繁读取也是paimon性能低下的关键,通过查阅paimon 0.9的官方代码,发现官方已经对二者做了内存缓存。通过以下参数可以打开:
Options options = new Options();options.set(WAREHOUSE, uri.toString());options.set("cache-enabled","true");options.set("cache.expiration-interval","1 min");options.set("cache.manifest.small-file-memory","10m");options.set("cache.manifest.small-file-threshold","3mb");CatalogContext context = CatalogContext.create(options,...);// 传递给Catalog对象,记住,所有的缓存都是挂载到Catalog之上的,如果要缓存生效// 比如一直缓存Catalog对象
但是实际测试以上方法非常容易触发jvm的gc,要谨慎使用。一旦发生gc,整体性能会非常显著的下降。
阿里妈妈Dolphin将推出针对元数据缓存的优化,敬请期待。
最后,data的IO当然是必不可少,但是通过分析paimon源码发现,客户端读取实际上可以并发读取。
4.3 提高并发
读取的plan生成的执行计划会返回多个plan,实际上每个plan之间是正交的,可以并发读取。
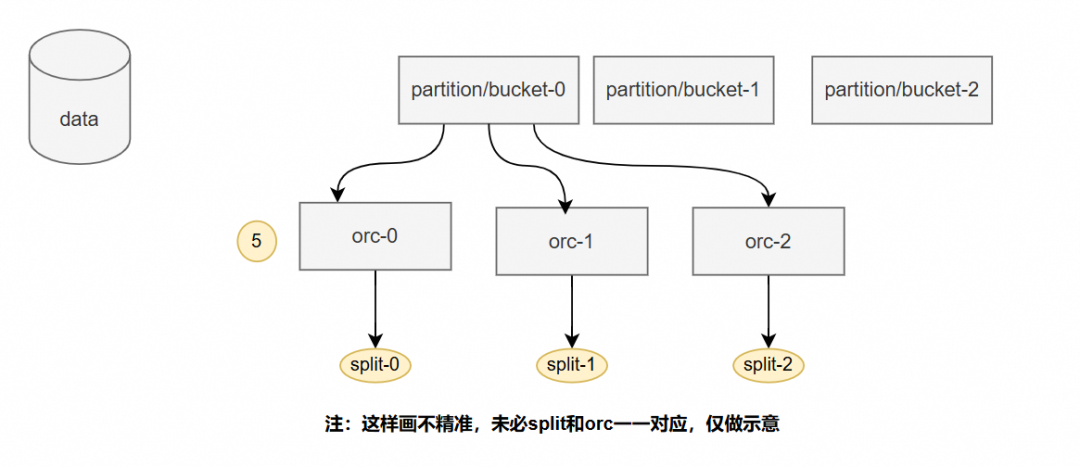
简单示意并发读取方式,并发读取性能是可观的,orc文件比较多的情况下,并发读取性能可以提高10倍以上的性能。建议在有限的cpu下,尽量把网络带宽打满。
4.3 避免重复编解码
大多数OLAP引擎可能都是C或者C++的,必然会涉及到跨进程通信,很多人可能会沮丧于OLAP性能,原因Paimon是java写的,我们提醒,不要把Paimon外表慢归咎于到Java的身上,Java真的非常快。
当然不同的OLAP引擎可能有不一样的情况,我们以dolphin的底层内核之一greenplum举例,把paimon作为外表接入,实现OLAP实时分析。
优化greenplum pxf读取性能
greenplum已经闭源,我们使用的pxf性能较差。但分析下来性能瓶颈极可能是由于大量的重对象解编码。
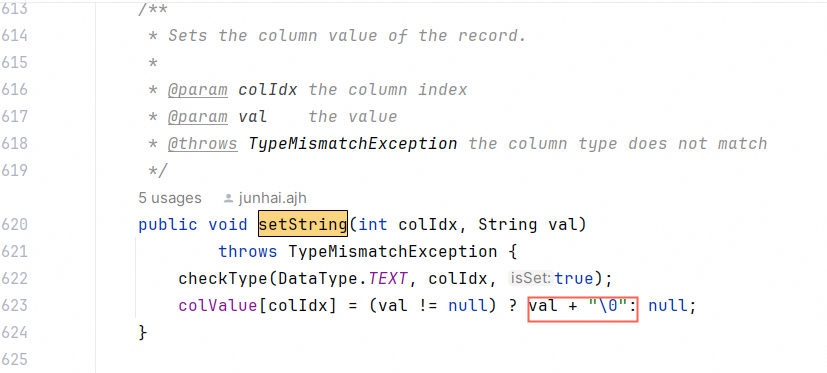
setString的时候重新编码一次
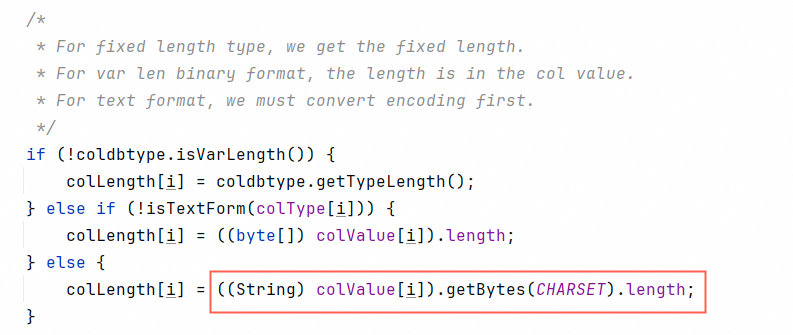
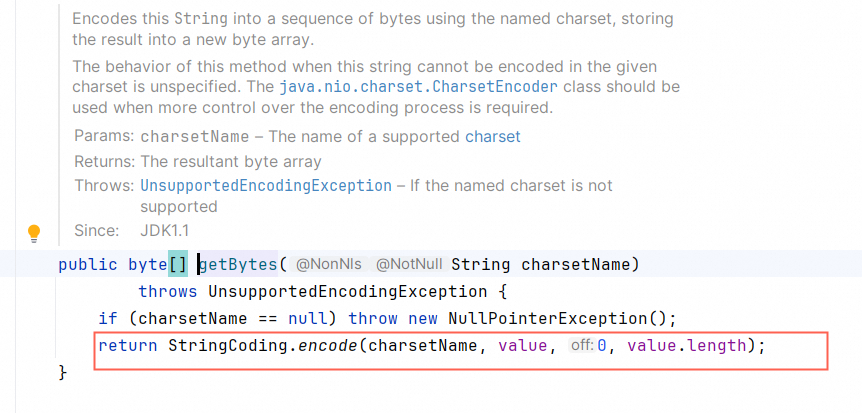
计算长度的时候encode一次
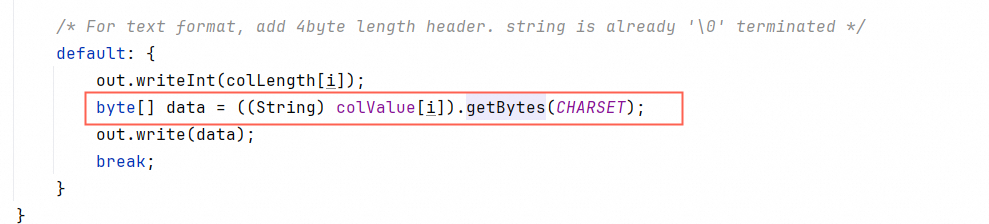
write的时候又重复encode一次
实现SpeedGPDWritable
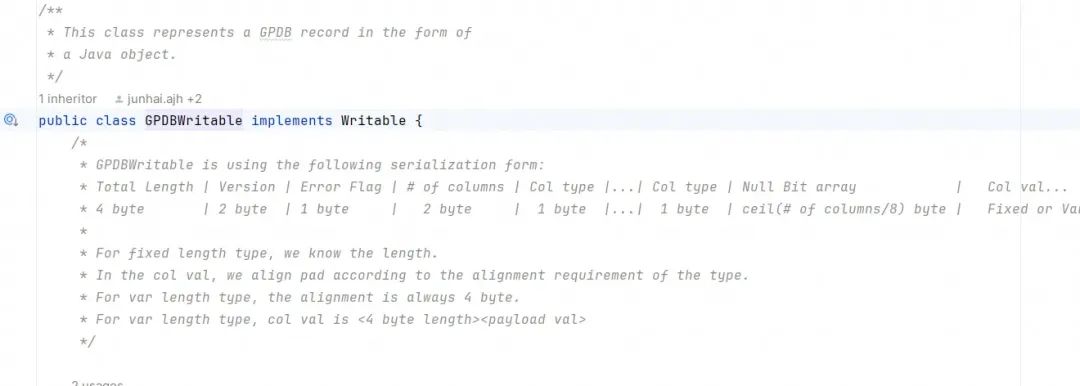
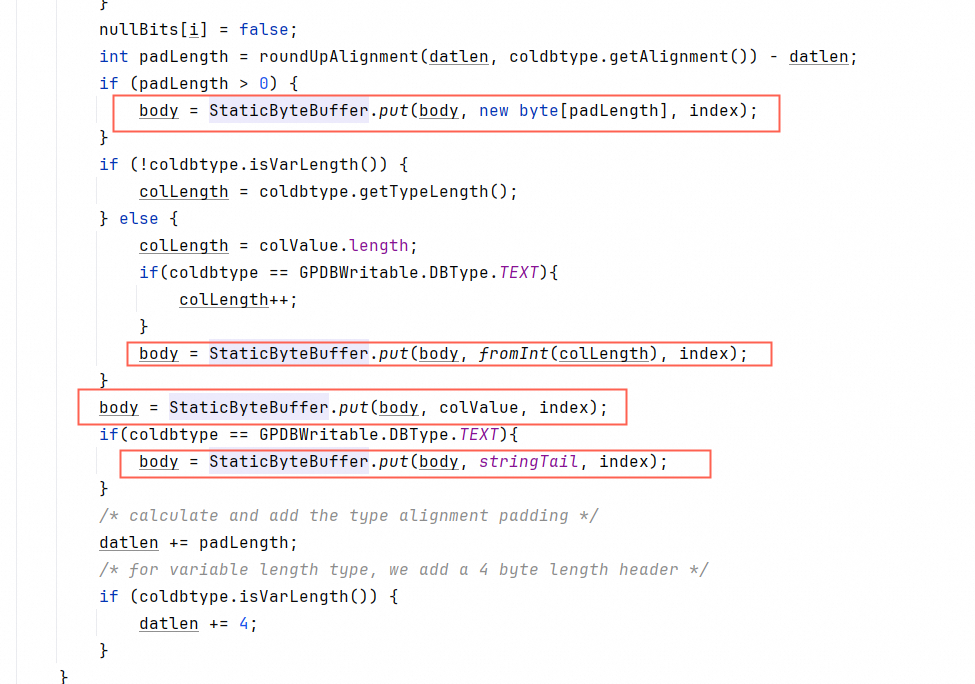
基于以上,保留gp协议的前提下,我们重写了GPDWritable,命名为SpeedGPDWritable。
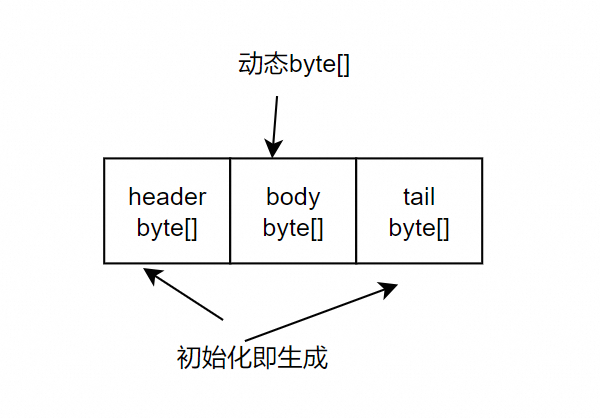
header初始化后固定大小,动态填数值
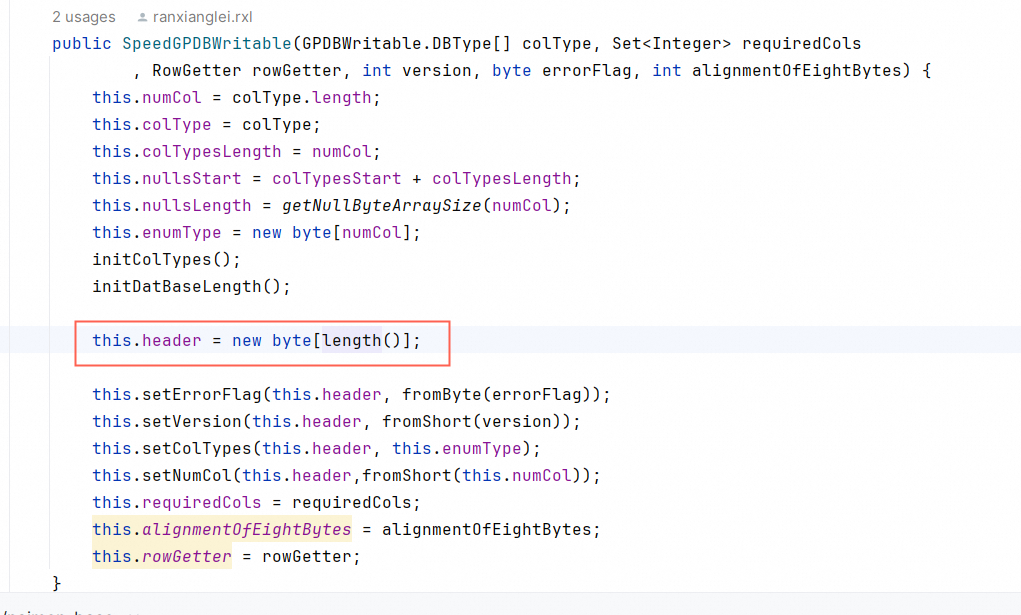
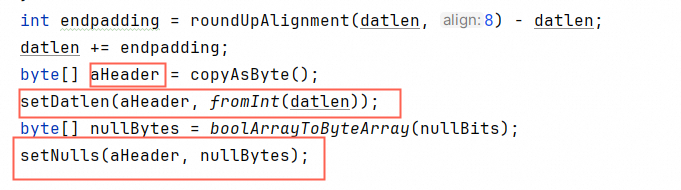
我们写了个简易的static的动态byte数组,避免创建对象。
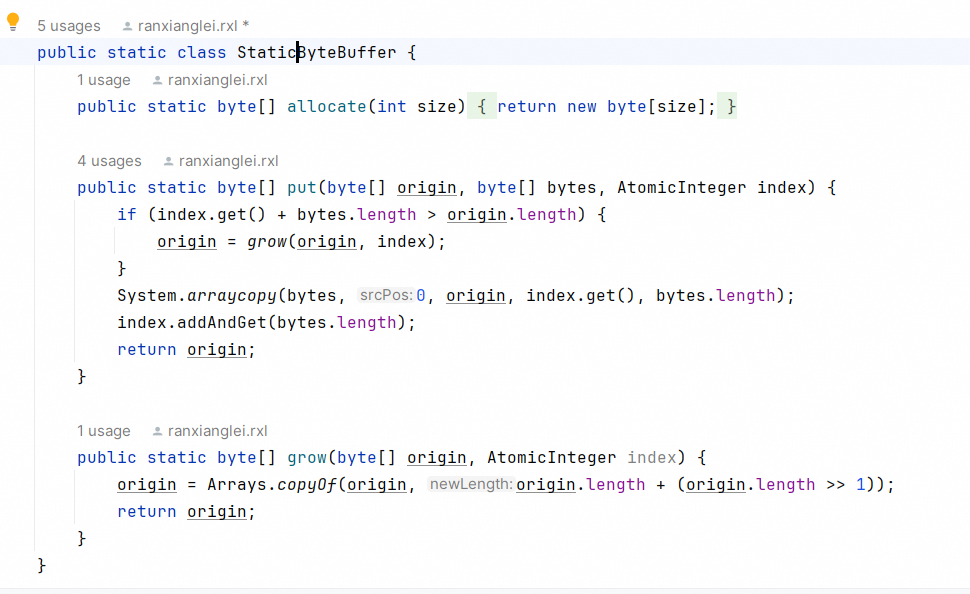
这样可以做到字符串直接byte追加,避免编码解码:
直接对接OutputStream流
给Paimon实现一个直接write到OutputStream的流接口,让底层ORC文件流和pxf的IO流直接对接,消除中间任何可能降低性能的环节。
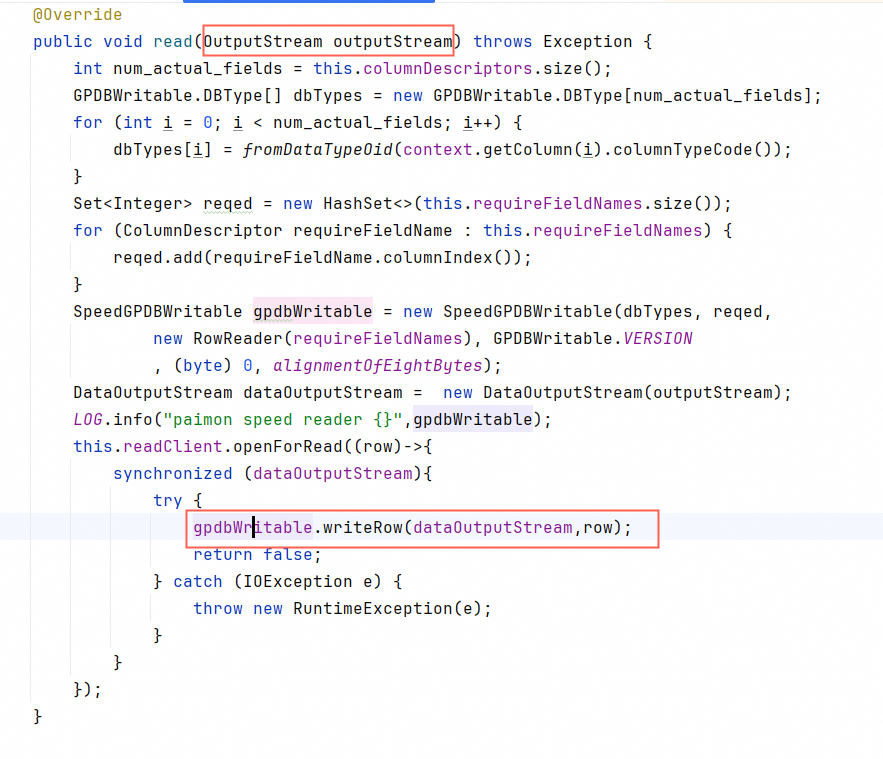
测试下来,这一改动使得传输性能提升了10倍左右。
5. 业务表现
结合阿里妈妈内部应用场景,我们前期主要承接对时效性和rt要求不高的业务场景,随着我们优化的深入,我们逐步承接高qps低rt的应用场景。更多业务应用请参考阿里妈妈Dolphin业务篇相关文章。数据规模方面,Dolphin-Paimon当前在线qps1000+,p99 RT约100ms,已接入1000+表,数据量达PB级。
6.进一步优化方向
针对Paimon读取大日志做聚合分析的场景,Dolphin会推出秒级性能的查询优化方案。
针对更高QPS更低RT的点查场景,Dolphin会推出10万级别qps,5ms以下rt的性能表现的Paimon实现。
Dolphin也会在不久的将来,把Paimon引入Clickhouse,并努力优化Clickhouse查询Paimon外表的性能,使其接近Clickhouse原生内表性能,最终实现Paimon官方的愿望:
▐ 关于我们
阿里妈妈Dolphin营销引擎,最初定位为解决通用OLAP在人群和场景圈选的计算性能问题,历经多年的技术发展与沉淀,目前已形成覆盖OLAP、AI、Streaming和Batch四大方向的智能超融合引擎,提供针对营销场景投前、投中、投后全链路的商家工具和算法策略迭代。欢迎感兴趣同学加入我们!


丨开源greenplum向量计算库:https://github.com/AlibabaIncubator/gpdb-faiss-vector
