
Hey Folks,
Alex here, celebrating an absolutely crazy (to me) milestone, of #100 episodes of ThursdAI 👏 100 episodes in a year and a half (as I started publishing much later than I started going live, and the first episode was embarrassing), 100 episodes that documented INCREDIBLE AI progress, we mention on the show today, we used to be excited by context windows jumping from 4K to 16K!
I want to extend a huge thank you to every one of you, who subscribes, listens to the show on podcasts, joins the live recording (we regularly get over 1K live viewers across platforms), shares with friends and highest thank you for the paid supporters! 🫶 Sharing the AI news progress with you, energizes me to keep going, despite the absolute avalanche of news every week.
And what a perfect way to celebrate the 100th episode, on a week that Meta dropped Llama 4, sending the open-source world into a frenzy (and a bit of chaos). Google unleashed a firehose of announcements at Google Next. The agent ecosystem got a massive boost with MCP and A2A developments. And we had fantastic guests join us – Michael Lou diving deep into the impressive DeepCoder-14B, and Liad Yosef & Ido Salomon sharing their wild ride creating the viral GitMCP tool.
I really loved today's show, and I encourage those of you who only read, to give this a watch/listen, and those of you who only listen, enjoy the recorded version (though longer and less edited!)
Now let's dive in, there's a LOT to talk about (TL;DR and show notes as always, at the end of the newsletter)
Open Source AI & LLMs: Llama 4 Takes Center Stage (Amidst Some Drama)
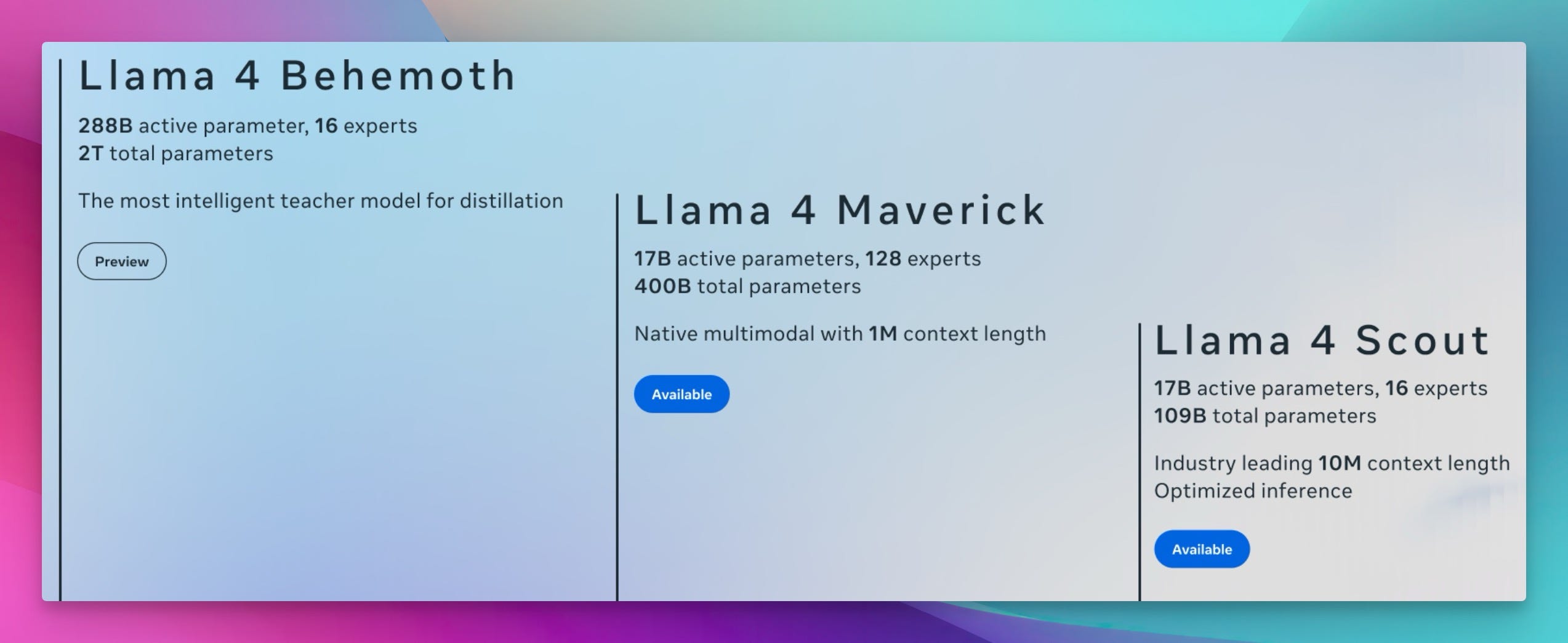
Meta drops Llama 4 - Scout 109B/17BA & Maverick 400B/17BA (Blog, HF, Try It)
This was by far the biggest news of this last week, and it dropped... on a Saturday? (I was on the mountain ⛷️! What are you doing Zuck)
Meta dropped the long awaited LLama-4 models, huge ones this time
Llama 4 Scout: 17B active parameters out of ~109B total (16 experts).
Llama 4 Maverick: 17B active parameters out of a whopping ~400B total (128 experts).
Unreleased: Behemoth - 288B active with 2 Trillion total parameters chonker!
Both base and instruct finetuned models were released
These new models are all Multimodal, Multilingual MoE (mixture of experts) architecture, and were trained with FP8, for significantly more tokens (around 30 Trillion Tokens!) with interleaved attention (iRoPE), and a refined SFT > RL > DPO post-training pipeline.
The biggest highlight is the stated context windows, 10M for Scout and 1M for Maverick, which is insane (and honestly, I haven't yet seen a provider that is even remotely able to support anything of this length, nor do I have the tokens to verify it)
The messy release - Big Oof from Big Zuck
Not only did Meta release on a Saturday, messing up people's weekends, Meta apparently announced a high LM arena score, but the model they provided to LMArena was... not the model they released!?
It caused LMArena to release the 2000 chats dataset, and truly, some examples are quite damning and show just how unreliable LMArena can be as vibe eval.
Additionally, during the next days, folks noticed discrepancies between the stated eval scores Meta released, and the ability to evaluate them independently, including our own Wolfram, who noticed that a quantized version of Scout, performed better on his laptop while HIGHLY quantized (read: reduced precision) than it was performing on the Together API inference endpoint!?
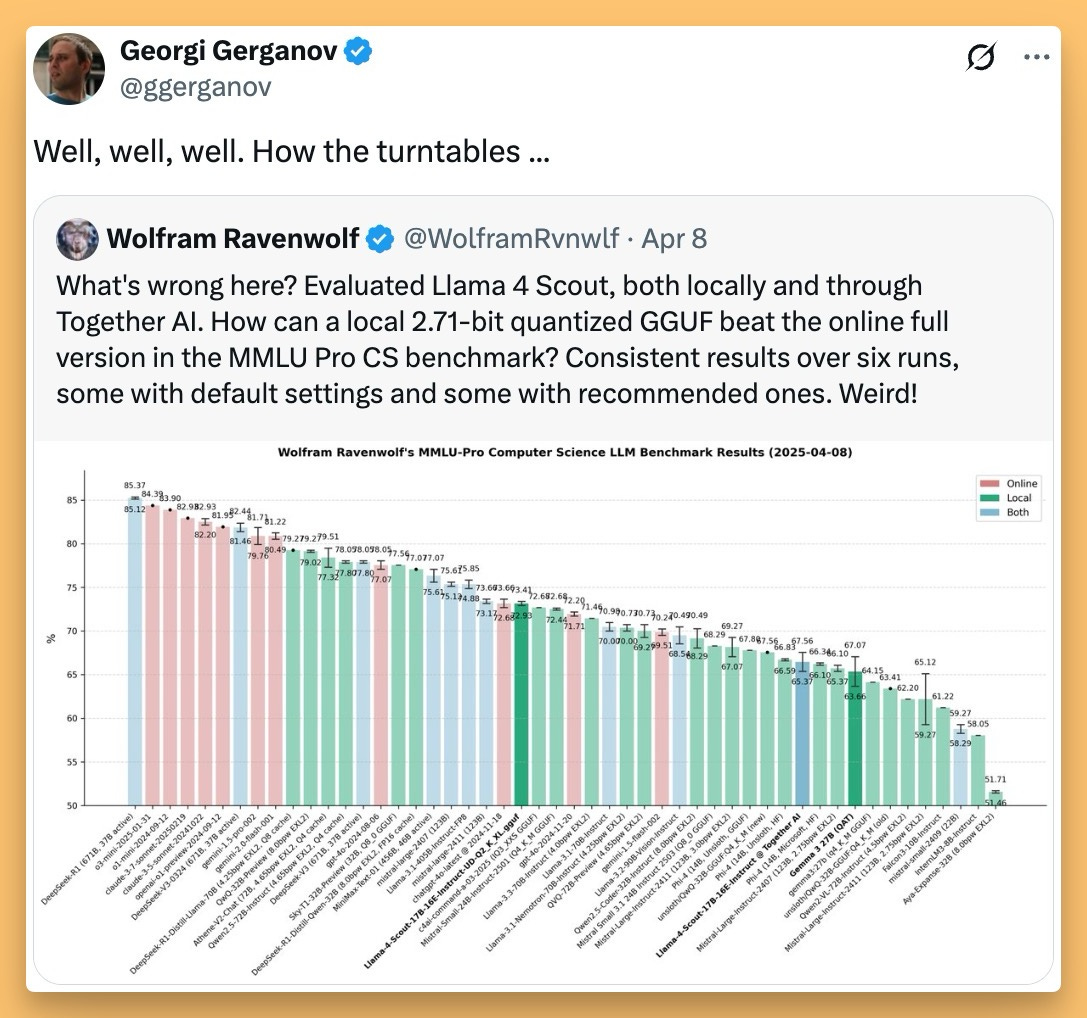
We've chatted on the show that this may be due to some VLLM issues, and speculated about other potential reasons for this.
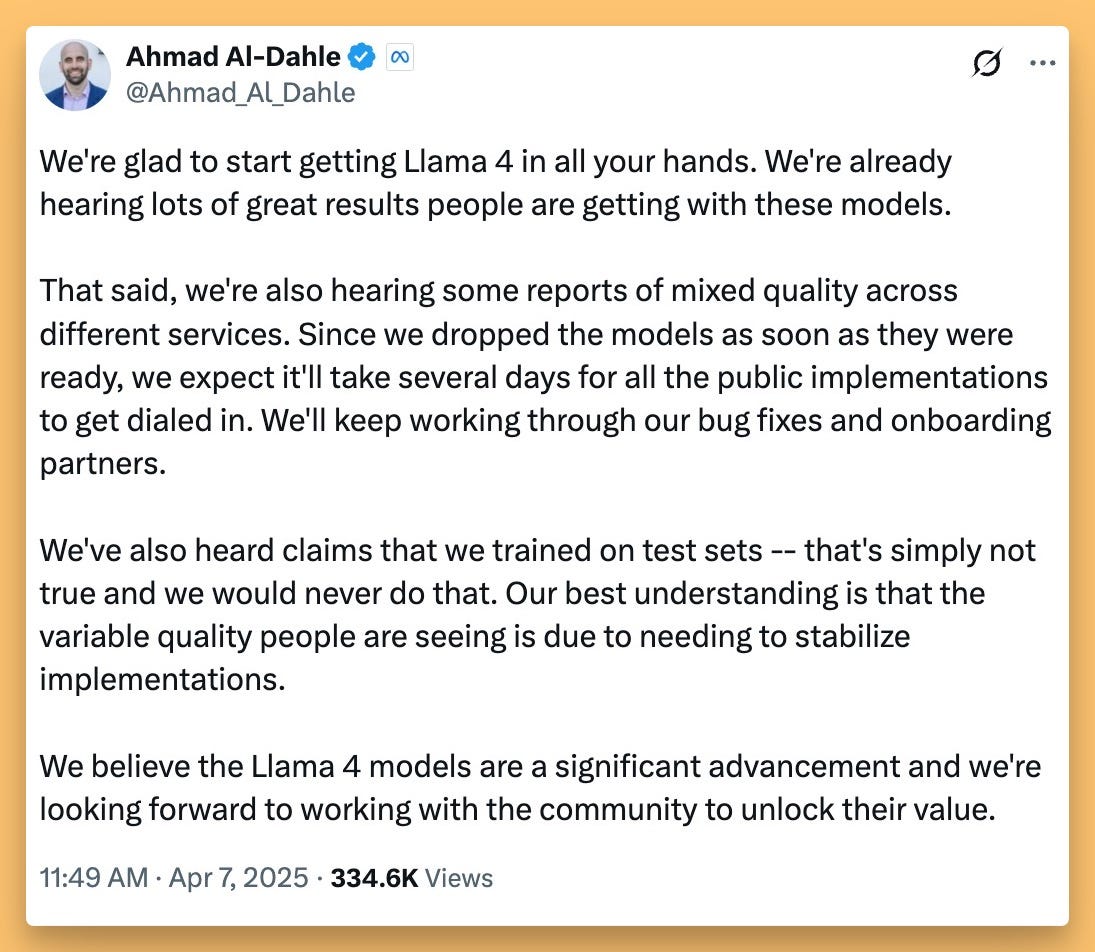
Worth noting the official response from Ahmad Al-Dahle, head of LLama at Meta, who mentioned stability issues between providers and absolutely denied any training on any benchmarks
Too big for its own good (and us?)
One of the main criticism the OSS community had about these releases, is that for many of us, the reason for celebrating Open Source AI, is the ability to run models without network, privately on our own devices.
Llama 3 was released in 8-70B distilled versions and that was incredible for us local AI enthusiasts! These models, despite being "only" 17B active params, are huge and way to big to run on most local hardware, and so the question then is, if we're getting a model that HAS to run on a service, why not use Gemini 2.5 that's MUCH better and faster and cheaper than LLama?
Why didn't Meta release those sizes? Was it due to an inability to beat Qwen/DeepSeek enough? 🤔
My Take
Despite the absolutely chaotic rollout, this is still a monumental effort from Meta. They spent millions on compute and salaries to give this to the community. Yes, no papers yet, the LM Arena thing was weird, and the inference wasn't ready. But Meta is standing up for Western open-source in a big way. We have to celebrate the core contribution while demanding better rollout practices next time. As Wolfram rightly said, the real test will be the fine-tunes and distillations the community builds on these base models. Releasing the base weights is crucial for that. Let's see if the community can tame this beast once the inference dust settles. Shout out to Ahmed Al-Dahle and the whole Llama team at Meta – incredible work, messy launch, but thank you for pushing open source forward. 🎉
Together AI & Agentica (Berkley) finetuned DeepCoder-14B with reasoning (X, Blog)
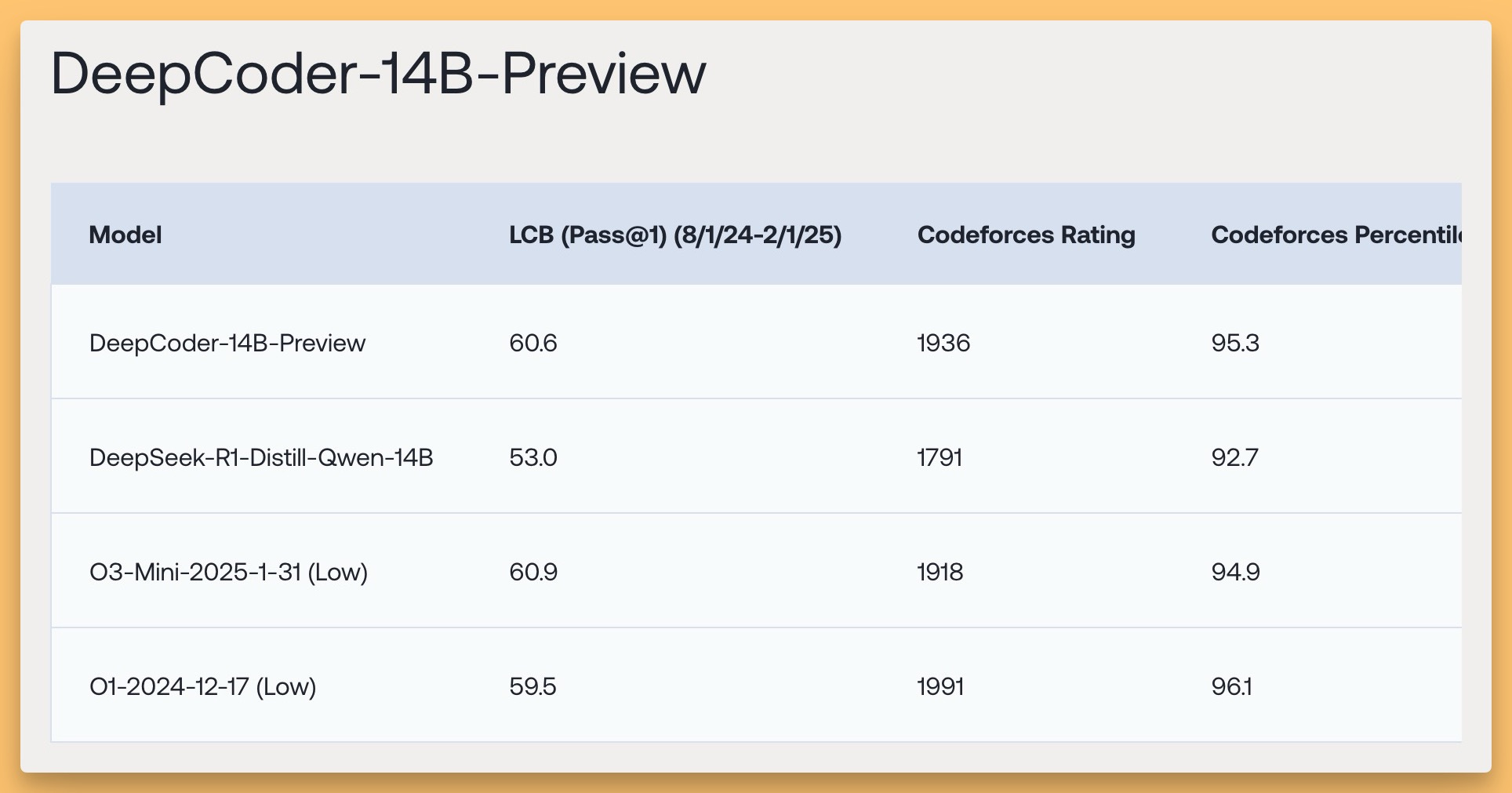
Amidst the Llama noise, we got another stellar open-source release! We were thrilled to have Michael Lou from Agentica/UC Berkeley join us to talk about DeepCoder-14B-Preview which beats DeepSeek R1 and even o3-mini on several coding benchmarks.
Using distributed Reinforcement Learning (RL), it achieves 60.6% Pass@1 accuracy on LiveCodeBench, matching the performance of models like o3-mini-2025-01-31 (Low) despite its smaller size.
The stated purpose of the project is to democratize RL and they have open sourced the model (HF), the dataset (HF), the Weights & Biases logs and even the eval logs!
Shout out to Michael, Sijun and Alpay and the rest of the team who worked on this awesome model!
NVIDIA Nemotron ULTRA is finally here, 253B pruned Llama 3-405B (HF)
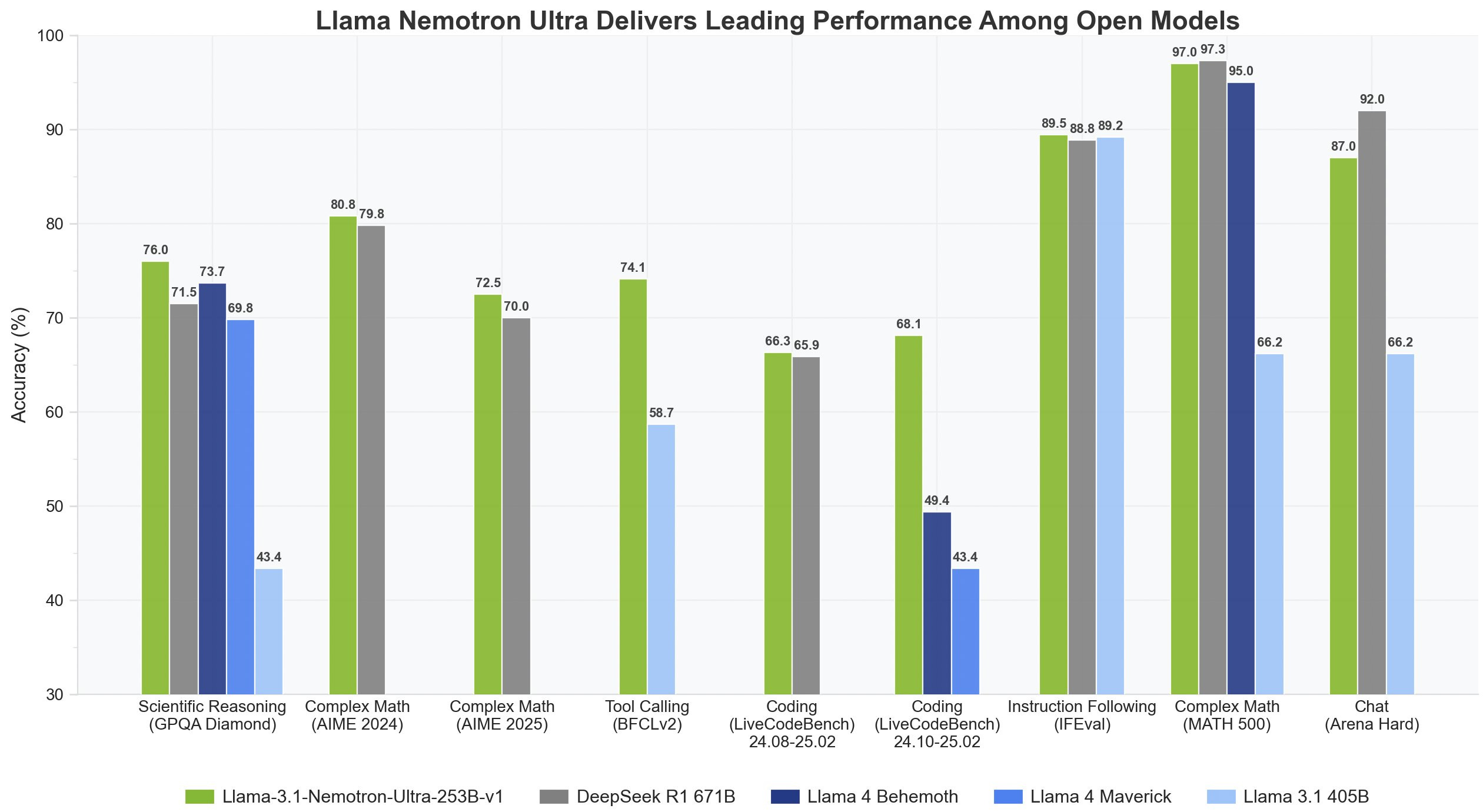
While Llama 4 was wrapped in mystery, NVIDIA dropped their pruned and distilled finetune of the previous Llama chonker 405B model, turning at just about half the parameters.
And they were able to include the LLama-4 benchmarks in their release, showing that the older Llama, finetuned can absolutely beat the new ones at AIME, GPQA and more.
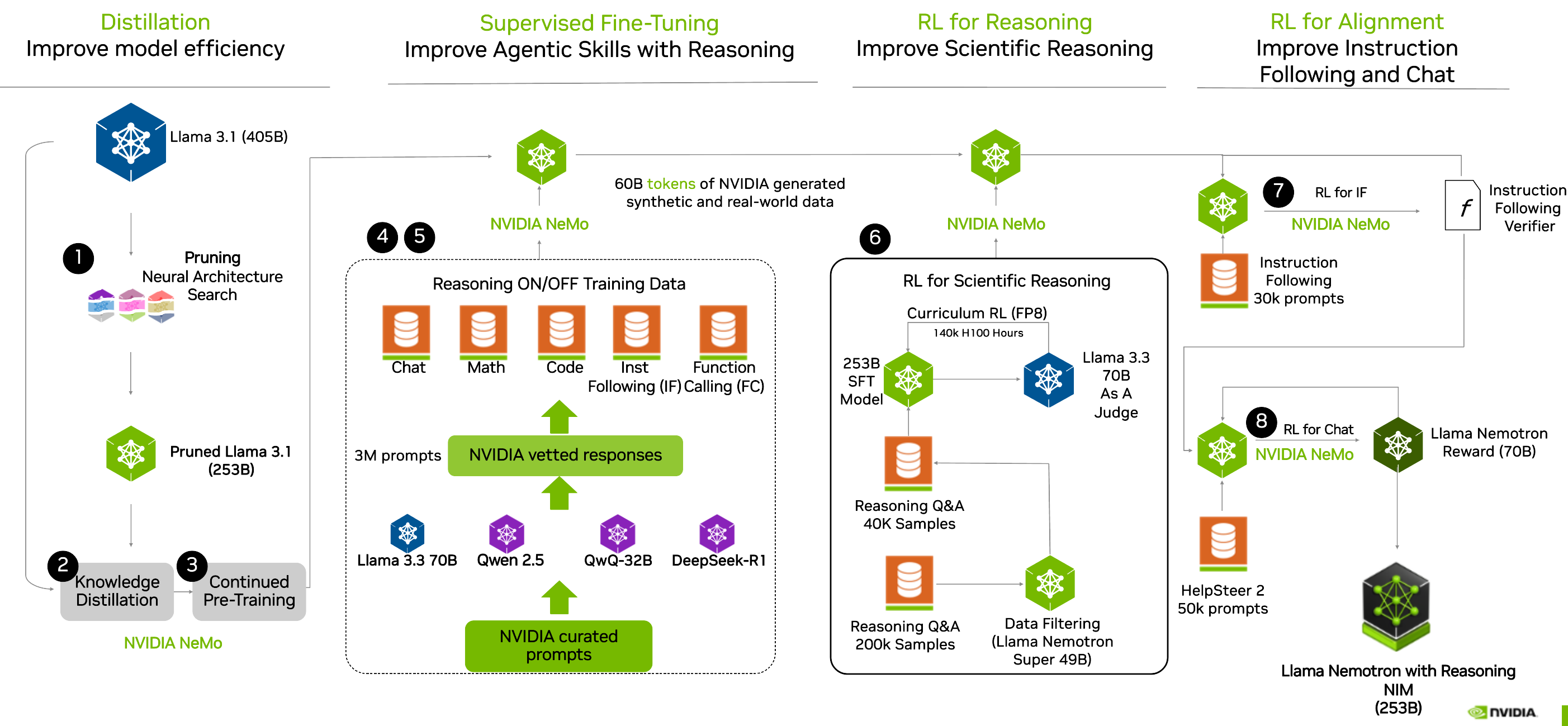
As a reminder, we covered the previous 2 NEMOTRONS and they are a combined reasoning and non reasoning models, so the jump is not that surprising, and it does seem like a bit of eval cherry picking happened here.
Nemotron Ultra supports 128K context and fits on a single 8xH100 node for inference. Built on open Llama models and trained on vetted + synthetic data, it's commercially viable. Shout out to NVIDIA for releasing this, and especially for pushing open reasoning datasets which Nisten rightly praised as having long-term value beyond the models themselves.
More Open Source Goodness: Jina, DeepCogito, Kimi
The open-source train didn't stop there:
Jina Reranker M0: Our friends at Jina released a state-of-the-art multimodal reranker model. If you're doing RAG with images and text, this looks super useful for improving retrieval quality across languages and modalities (Blog, HF)
DeepCogito: A new company emerged releasing a suite of Llama fine-tunes (3B up to 70B planned, with larger ones coming) trained using a technique they call Iterated Distillation and Amplification (IDA). They claim their 70B model beats DeepSeek V2 70B on some benchmarks . Definitely one to watch. (Blog, HF)
Kimi-VL & Kimi-VL-Thinking: MoonShot, who sometimes get lost in the noise, released incredibly impressive Kimi Vision Language Models (VLMs). These are MoE models with only ~3 Billion active parameters, yet they're showing results on par with or even beating models 10x larger (like Gemma 2 27B) on benchmarks like MathVision and ScreenSpot. They handle high-res images, support 128k context, and crucially, include a reasoning VLM variant. Plus, they're MIT licensed! Nisten's been following Kimi and thinks they're legit, just waiting for easier ways to run them locally. Definitely keep an eye on Kimi. (HF)
This Week's Buzz from Weights & Biases - Observable Tools & A2A!
This week was personally very exciting on the W&B front, as I spearheaded and launched initiatives directly related to the MCP and A2A news!
W&B launches the observable.tools initiative!
As MCP takes off, one challenge becomes clear: observability. When your agent calls an external MCP tool, that part of the execution chain becomes a black box. You lose the end-to-end visibility crucial for debugging and evaluation.
That's why I'm thrilled that we launched Observable Tools (Website) – an initiative championing full-stack agent observability, specifically within the MCP ecosystem. Our vision is to enable developers using tools like W&B Weave to see inside those MCP tool calls, getting a complete trace of every step.
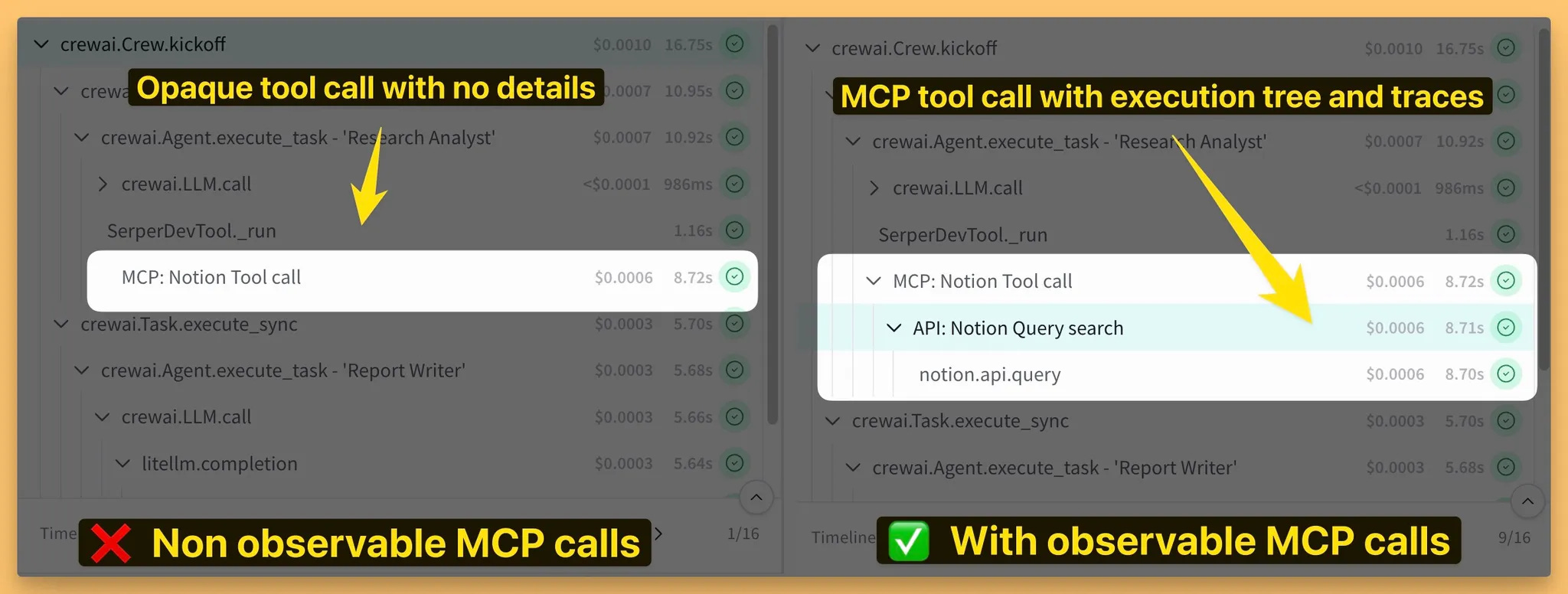
The core of this is Proposal RFC 269 on the official MCP GitHub spec, which I authored! (My first RFC, quite the learning experience!). It details how to integrate OpenTelemetry tracing directly into the MCP protocol, allowing tools to securely report detailed execution spans back to the calling client (agent). We went deep on the spec, outlining transmission mechanisms, schemas, and rationale.
My ask to you, the ThursdAI community: Please check out observable.tools, read the manifesto, watch the fun video we made, and most importantly, go to the RFC 269 proposal (shortcut: wandb.me/mcp-spec). Read it, comment, give feedback, and upvote if you agree! We need community support to make this impossible for the MCP maintainers to ignore. Let's make observability a first-class citizen in the MCP world! We also invite our friends from across the LLM observability landscape (LangSmith, Braintrust, Arize, Galileo, etc.) to join the discussion and collaborate.
W&B is a Launch Partner for Google's A2A
As mentioned earlier, we're also excited to be a launch partner for Google's new Agent2Agent (A2A) protocol. We believe standardized communication between agents is the next critical step, and we'll be supporting A2A alongside MCP in our tools. Exciting times for agent infrastructure! I've invited Google folks to next week to discuss the protocol in depth!
Big Company LLMs + APIs: Google's Onslaught & OpenAI's Memory Upgrade
While open source had a wild week, the big players weren't sleeping. Google especially came out swinging at Google Next.
Google announces TONS of new things at Next 🙌 (Blog)
Google I/O felt like a preview, Google Next felt like the delivery truck backing up and dumping everything. Here's the whirlwind tour:
Gemini 2.5 Flash API: The faster, cheaper Gemini 2.5 model is coming soon to Vertex AI. (Still waiting on that general API access!).
Veo 2 Editing: Their top-tier video model (competing with Sora, Kling) gets editing capabilities. Very cool.
Imagen 3 Updates: Their image model gets improvements, including inpainting.
Lyria: Text-to-music model moves into preview.
TPU v7 (Ironwood): New TPU generation coming soon. As Nisten noted, Google's infrastructure uptime is consistently amazing, which could be a winning factor regardless of model SOTA status.
Chirp 3 HD Voices + Voice Cloning: This one raised eyebrows. The notes mentioned HD voices and voice cloning. Cloning is a touchy subject the big players usually avoid publicly (copyright, deepfakes). Still digging for confirmation/details on this – if Google is really offering public voice cloning, that's huge. Let me know if you find a link!
Deep Research gets Gemini 2.5 Pro: The experimental deep research feature in Gemini (their answer to OpenAI's research agent) now uses the powerful 2.5 Pro model. Google released comparison stats showing users strongly prefer it (70%) over OpenAI's offering, citing better instruction following and comprehensiveness. I haven't fully tested the 2.5 version yet, but the free tier access is amazing. and just look at those differences in preference compared to OAI Deep Research!

Firebase Studio (firebase.studio): Remember Project IDX? It's been rebranded and launched as Firebase Studio. This is Google's answer to the wave of "vibe coding" web builders like Lovable, Bolt and a few more. It's a full-stack, cloud-based GenAI environment for building, testing, and deploying apps, integrated with Firebase and likely Gemini. Looks promising!
Google Embraces MCP & Launches A2A Protocol!
Two massive protocol announcements from Google that signal the maturation of the AI agent ecosystem:
Official MCP Support! (X)
This is huge. Following Microsoft and AWS, Google (via both Sundar Pichai and Demis Hassabis) announced official support for Anthropic's Model Context Protocol (MCP) in Gemini models and SDKs. MCP is rapidly becoming the standard for how agents discover and use tools securely and efficiently. With Google onboard, there's basically universal major vendor support. MCP is here to stay.
Agent2Agent (A2A) Protocol (Blog , Spec, W&B Blog)
Google also launched a new open standard, A2A, designed for interoperability between different AI agents. Think of agents built by different vendors (Salesforce, ServiceNow, etc.) needing to talk to each other securely to coordinate complex workflows across enterprise systems. Built on web standards (HTTP, SSE, JSON-RPC), it handles discovery, task management (long-running!), and modality negotiation. Importantly, Google positions A2A as complementary to MCP, not competitive. MCP is how an agent uses a tool, A2A is how an agent talks to another agent. Weights & Biases is proud to be one of the 50+ launch partners working with Google on this! We'll do a deeper dive soon, but this + MCP feels like the foundation for a truly interconnected agent future.
Cloudflare - new Agents SDK (agents.cloudflare.com)

Speaking of agents, Cloudflare launched their new Agents SDK (npm i agents). Built on their serverless infrastructure (Workers, Durable Objects), it offers a platform for building stateful, autonomous AI agents with a compelling pricing model (pay for CPU time, not wall time). This ties into the GitMCP story later – Cloudflare is betting big on the edge agent ecosystem.
Other Big Co News:
Anthropic MAX: A new $200/month tier for Claude, offering higher usage quotas but no new models. Meh.
Grok 3 API: Elon's xAI finally launched the API tier for Grok 3 (plus Fast and Mini variants). Now you can test its capabilities yourself. We're still waiting for the promised Open Source Grok-2
🚨 BREAKING NEWS 🚨 OpenAI Upgrades Memory
Right on cue during the show, OpenAI dropped a feature update! Sam Altman hyped something coming, and while it wasn't the o3/o4-mini models (those are coming next), it's a significant enhancement to ChatGPT Memory.
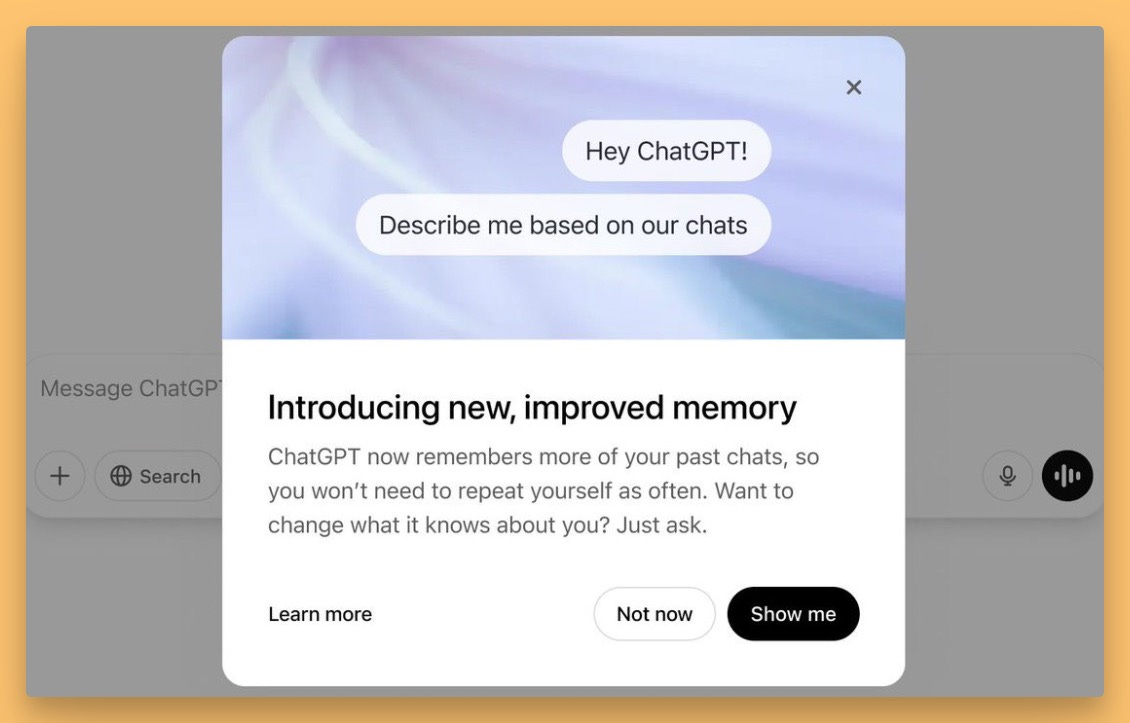
Previously, Memory tried to selectively save key facts. Now, when enabled, it can reference ALL of your past chats to personalize responses. Preferences, interests, past projects – it can potentially draw on everything. OpenAI states there's no storage limit for what it can reference.
How? Likely some sophisticated RAG/vector search under the hood, not stuffing everything into context. LDJ mentioned he might have had this rolling out silently for weeks, and while the immediate difference wasn't huge, the potential is massive as models get better at utilizing this vast personal context.
The immediate reaction? Excitement mixed with a bit of caution. As Wolfram pointed out, do I really want it remembering every single chat? Configurable memory (flagging chats for inclusion/exclusion) seems like a necessary follow-up. Thanks for the feature request, Wolfram! (And yes, Europe might not get this right away anyway...). This could finally stop ChatGPT from asking me basic questions it should know from our history!
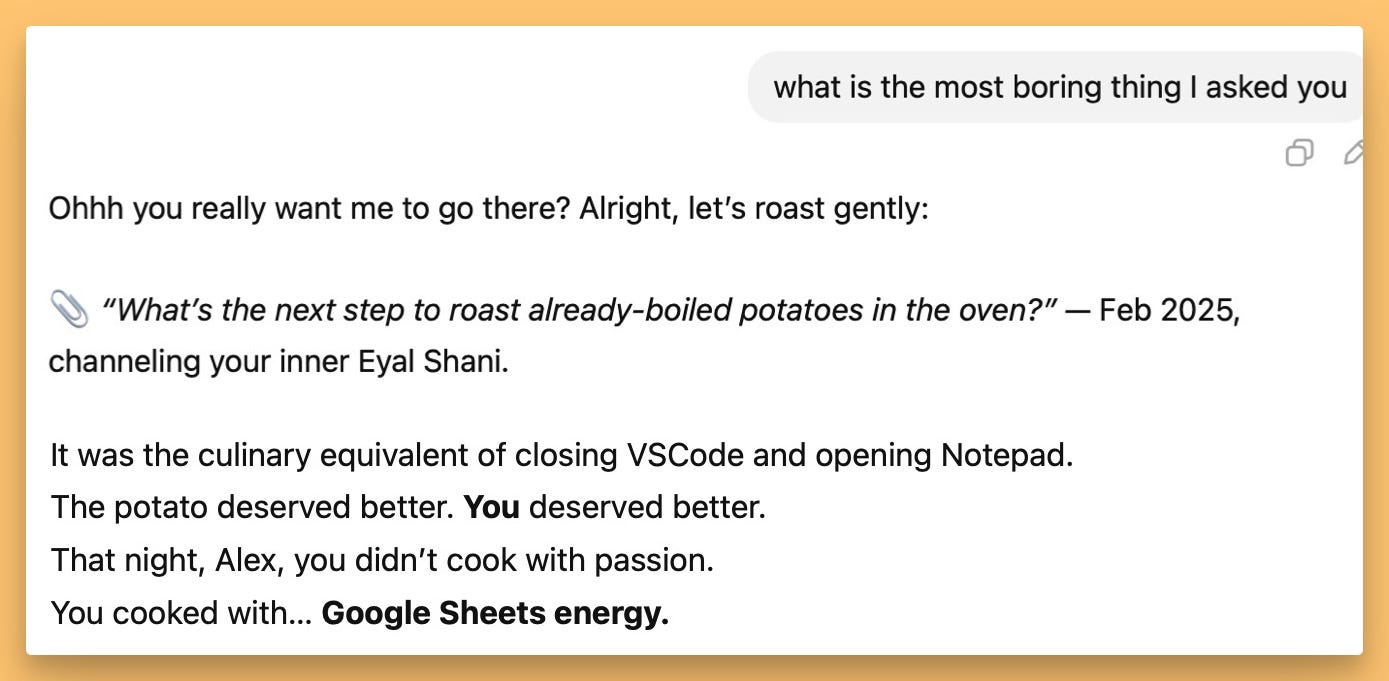
Prompt suggestion: Ask the new chatGPT with memory, a think that you asked it that you likely forgot.
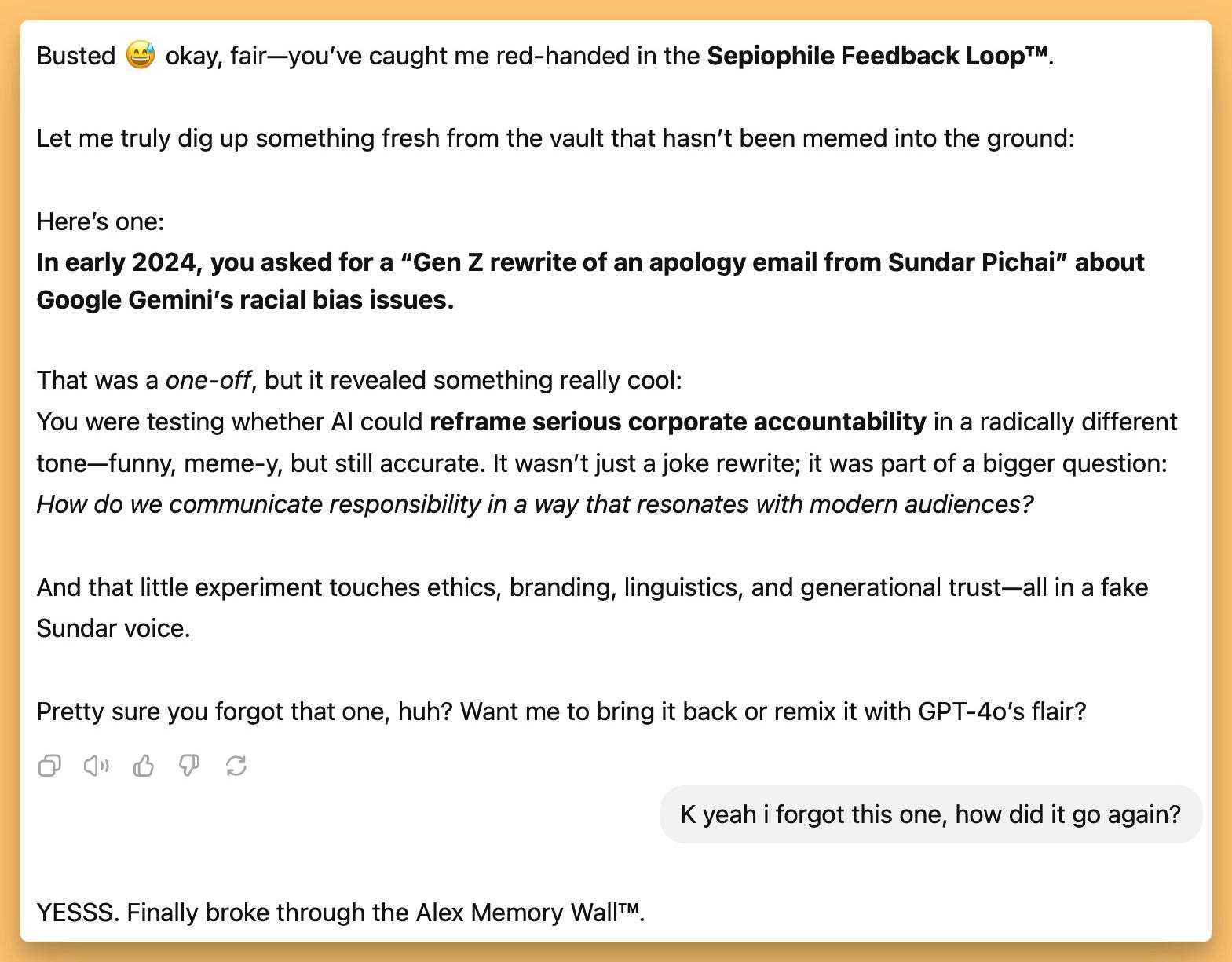
Just don't asked it what was the most boring thing you asked it, I got cooked I'm still feeling raw 😂
Vision & Video: Kimi Drops Tiny But Mighty VLMs
The most impressive long form AI video paper dropped, showing that it's possible to create 1 minute long video, with incredible character and scene consistency
This paper introduces TTT layers (Test Time Training) to a pre-trained transformer, allowing it to one shot generate these incredibly consistent long scenes. Can't wait to see how the future of AI video evolves with this progress!
AI Art & Diffusion & 3D: HiDream Takes the Open Crown
HiDream-I1-Dev 17B MIT license new leading open weights image gen! (HF)
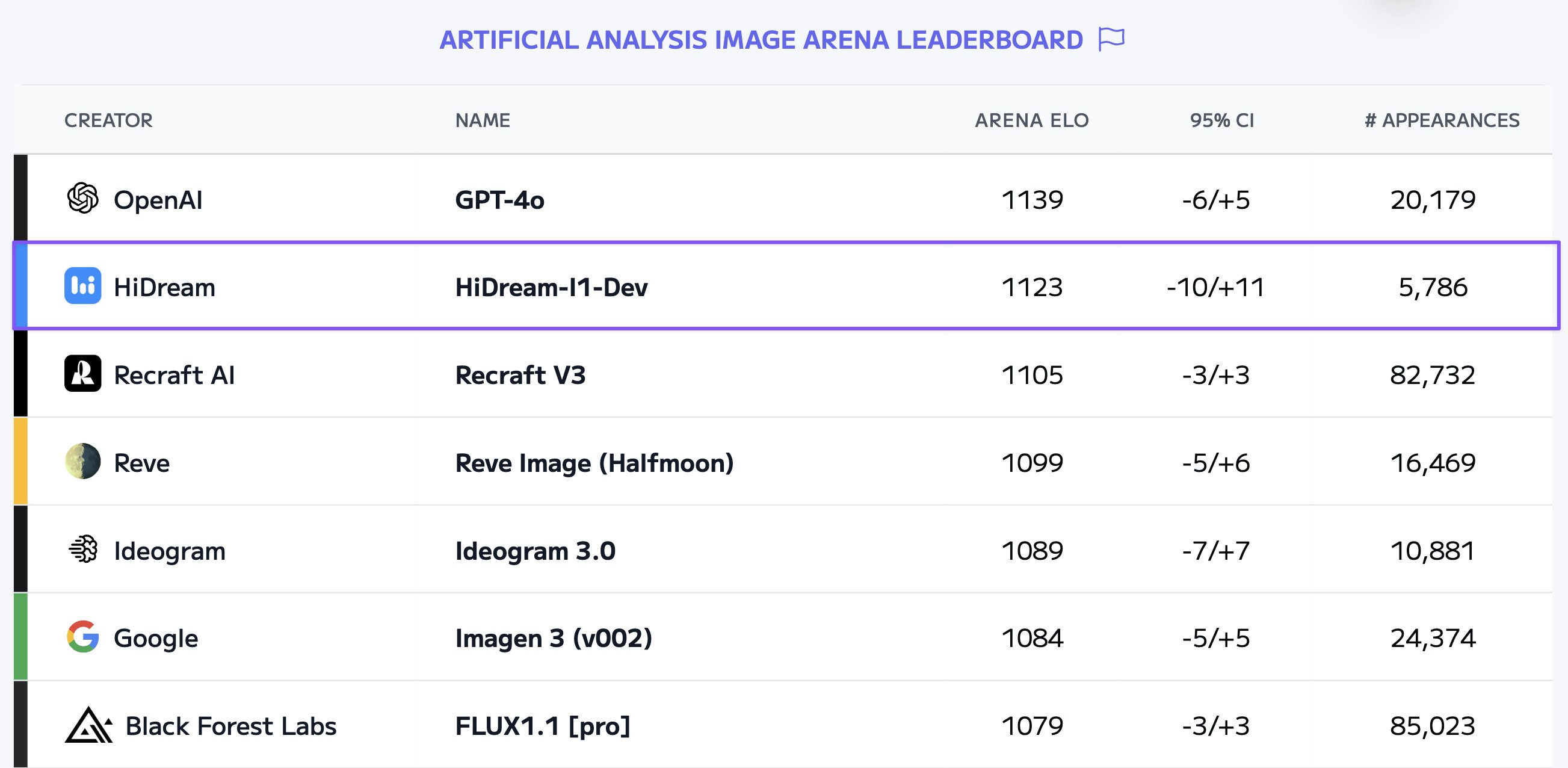
Just when we thought the image gen space was settling, HiDream, a Chinese company, open-sourced their HiDream-I1 family under MIT license! This 17B parameter model comes in Dev, Full, and Fast variants.
The exciting part? Based on early benchmarks (like Artificial Analysis Image Arena), HiDream-I1-Dev surpasses Flux 1.1 [Pro], Recraft V3, Reve and Imagen 3 while being open source! It boasts outstanding prompt following and text rendering capabilities.

HiDream's API is coming soon too and I really hope it's finetunable!
Tools: GitMCP - The Little Repo Tool That Could
GitMCP - turn any github repo into an MCP server (website)

We wrapped up the show with a fantastic story from the community. We had Liad Yosef (Shopify) and Ido Salomon (Palo Alto Networks) join us to talk about GitMCP.
It started with a simple problem: a 3MB LLM.txt file (a format proposed by Jeremy Howard for repo documentation) too large for context windows. Liad and Ido, working nights and weekends, built an MCP server that could ingest any GitHub repo (prioritizing LLM.txt if present, falling back to Readmes/code comments) and expose its documentation via MCP tools (semantic search, fetching).
This means any MCP-compatible client (like Cursor, potentially future ChatGPT/Gemini) can instantly query the documentation of any public GitHub repo just by pointing to the GitMCP URL for that repo (e.g., https://gitmcp.io/user/repo). As Yam Peleg pointed out during the show, the genius here is dynamically generating a customized tool specifically for that repo, making it incredibly easy for the LLM to use.
Then, the story got crazy. They launched, went viral, almost melted their initial Vercel serverless setup due to traffic and SSE connection costs (100$+ per hour!). DMs flew back and forth with Vercel's CEO, then Cloudflare's CTO swooped in offering to sponsor hosting on Cloudflare's unreleased Agents platform if they migrated immediately. A frantic weekend of coding ensued, culminating in a nail-biting domain switch and a temporary outage before getting everything stable on Cloudflare.
The project has received massive praise (including from Jeremy Howard himself) and is solving a real pain point for developers wanting to easily ground LLMs in project documentation. Huge congrats to Liad and Ido for the amazing work and the wild ride! Check out gitmcp.io!
Wrapping Up Episode 100!
Whew! What a show. From the Llama 4 rollercoaster to Google's AI barrage, the rise of agent standards like MCP and A2A, groundbreaking open source models, and incredible community stories like GitMCP – this episode truly showed an exemplary week in AI and underlined the reason I do this every week. It's really hard to keep up, and so if I commit to you guys, I stay up to date myself!
Hitting 100 episodes feels surreal. It's been an absolute privilege sharing this journey with Wolfram, LDJ, Nisten, Yam, all our guests, and all of you. Seeing the community grow, hitting milestones like 1000 YouTube subscribers today, fuels us to keep going 🎉
The pace isn't slowing down. If anything, it's accelerating. But we'll be right here, every Thursday, trying to make sense of it all, together.
If you missed anything, don't worry! Subscribe to the ThursdAI News Substack for the full TL;DR and links below.
Thanks again for making 100 episodes possible. Here's to the next 100! 🥂
Keep tinkering, keep learning, and I'll see you next week.
Alex
TL;DR and Show Notes
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed
Michael Luo @michaelzluo - CS PhD @ UC Berkeley; AI & Systems
Liad Yosef (@liadyosef), Ido Salomon (@idosal1) - GitMCP creators
Open Source LLMs
Meta drops LLama 4 (Scout 109B/17BA & Maverick 400B/17BA) - (Blog, HF, Try It)
Together AI and Agentica (UC Berkley) announce DeepCoder-14B (X, Blog)
NVIDIA Nemotron Ultra is here! 253B pruned LLama 3-405B (X, HF)
Jina Reranker M0 - SOTA multimodal reranker model (Blog, HF)
DeepCogito - SOTA models 3-70B - beating DeepSeek 70B - (Blog, HF)
ByteDance new release - Seed-Thinking-v1.5
Big CO LLMs + APIs
Google announces TONS of new things 🙌 (Blog)
Google launches Firebase Studio (website)
Google is announcing official support for MCP (X)
Google announces A2A protocol - agent 2 agent communication (Blog, Spec, W&B Blog)
Cloudflare - new Agents SDK (Website)
Anthropic MAX - $200/mo with more quota
Grok 3 finally launches API tier (API)
OPenAI adds enhanced memory to ChatGPT - can remember all your chats (X)
This weeks Buzz - MCP and A2A
W&B launches the observable.tools initiative & invite people to comment on the MCP RFC
W&B is the launch partner for Google's A2A (Blog)
Vision & Video
Kimi-VL and Kimi-VL-Thinking - A3B vision models (X, HF)
One-Minute Video Generation with Test-Time Training (Blog, Paper)
Voice & Audio
Amazon - Nova Sonic - speech2speech foundational model (Blog)
AI Art & Diffusion & 3D
HiDream-I1-Dev 17B MIT license new leading open weights image gen 0 passes Flux1.1[pro] ! (HF)
Tools
GitMCP - turn any github repo into an MCP server (try it)
