
世界模型领域最新进展,要比拼“世界生成”了。
李飞飞吴佳俊团队提出了全面评测基准WorldScore,涵盖了三大类评估指标,动态静态都有涉及,其数据集中包含了3000个测试样例。
并且,WorldScore将3D场景生成、4D场景生成和视频生成三类模型的评估,统一到了一起。

利用WorldScore基准,团队对一共19款模型进行了全面评估。
评估的结果揭示了当前世界生成技术面临的相机控制能力不足、长序列世界生成困难等主要挑战,为模型研究人员提供了重要参考。
正如网友所评价,从单一场景到整体世界构建的转变,需要这样的基准来对研究做出指导。

3D/4D/视频生成统一评测
研究团队认为,之前的基准测试(例如 VBench)仅能评估单个场景的生成能力,远未达到“世界”生成的层次。
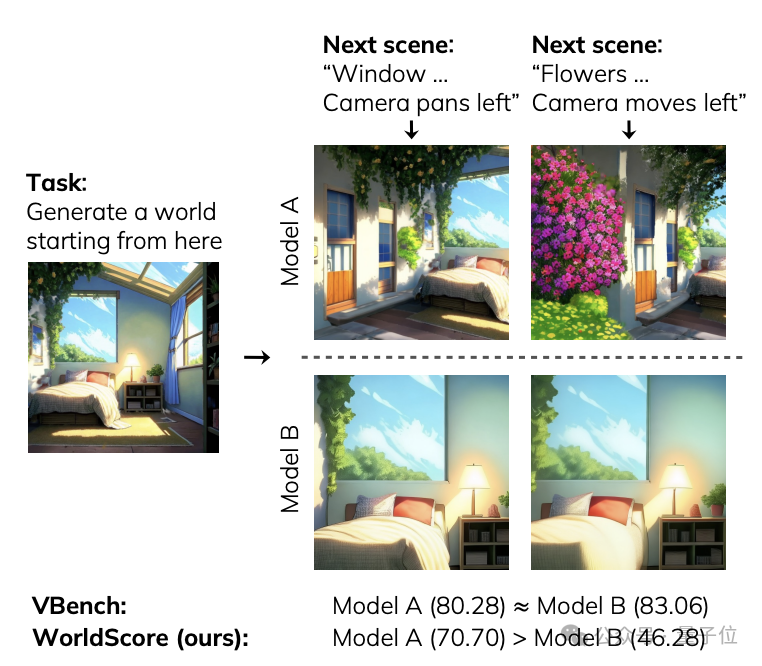
并且以前的基准测试仅考虑视频模型,但世界生成模型还包括3D和4D方法,而WorldScore可以对所有这些模型进行统一评估。
WorldScore将世界生成任务分解成一系列连续的下一场景生成任务,每个任务由三个关键组成部分定义:

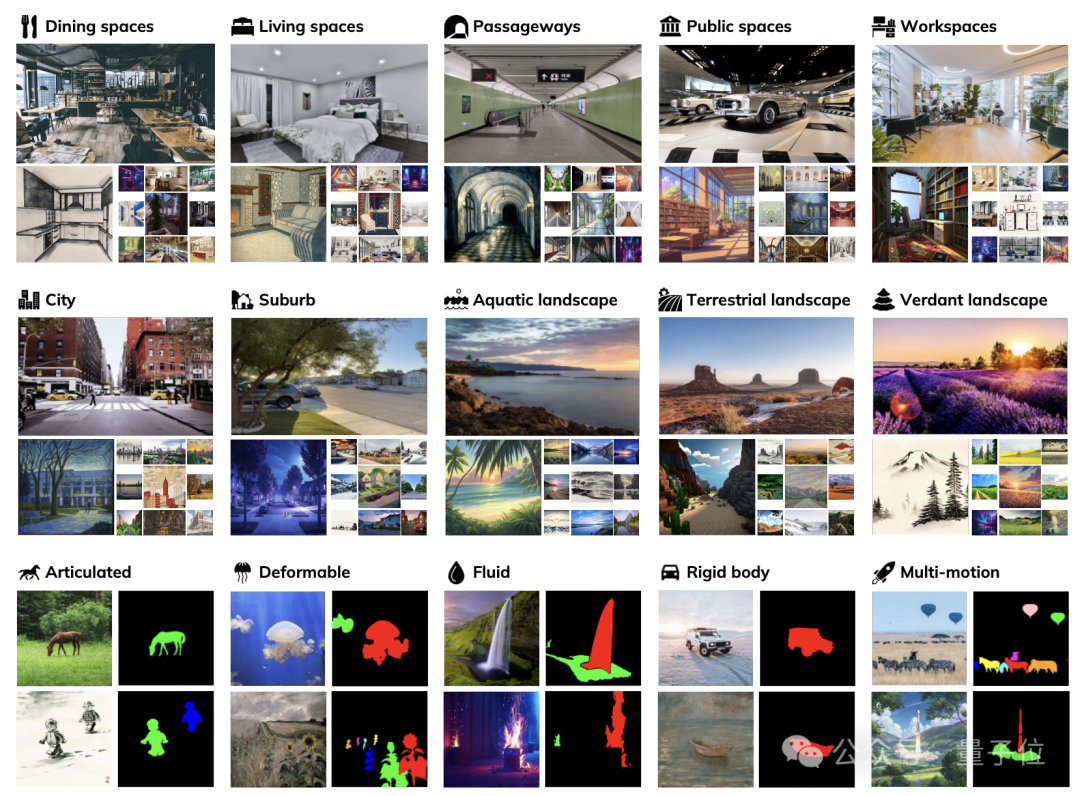
数据集方面,WorldScore包含了3000个测试样例,其中2000个用于评估静态世界生成能力,1000个用于评估动态世界生成能力。
静态世界生成数据涵盖了10个场景类别,包括5类室内场景(餐饮空间、居住空间、通道、公共空间、工作空间)和5类室外场景(城市、郊区、水域景观、陆地景观、绿色景观)。
动态世界数据则包含了5种不同类型的运动:关节运动、可变形运动、流体运动、刚体运动和多物体运动。
每个测试样例都有两个版本——真实风格和艺术风格,以评估模型在不同视觉域的表现。
所涉及的指标则包括了可控性、质量和动态评估(静态场景不涉及此项)三个大类。
其中可控性评估,具体又包括了三项指标:
质量评估,涵盖了四项内容:
动态评估则包含三个方面:
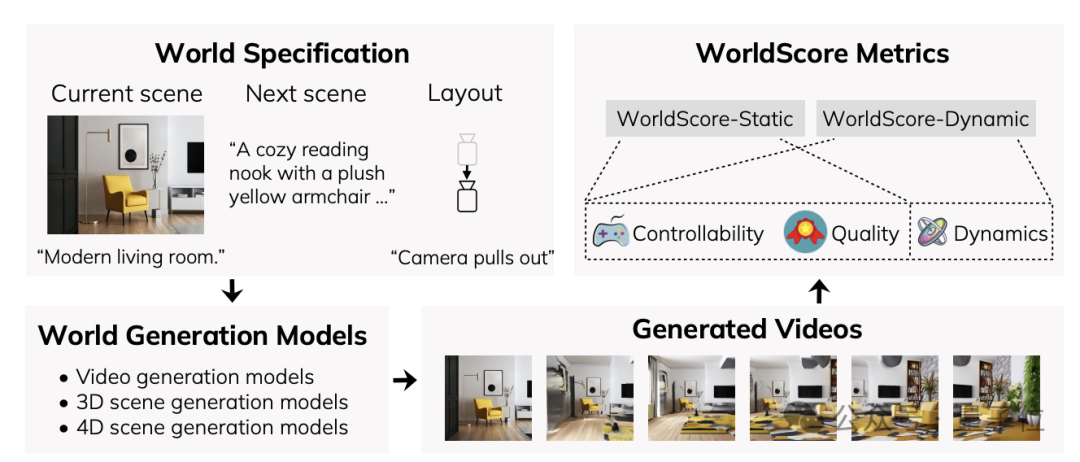
最终,所有评估指标都经过线性归一化处理到0-100区间,并通过计算控制和质量维度各指标的算术平均值得到WorldScore-Static得分。
在此基础上,再加入动态维度的三项指标成绩,就得到了WorldScore-Dynamic评分。
3D模型更擅长静态,视频模型动态效果更好
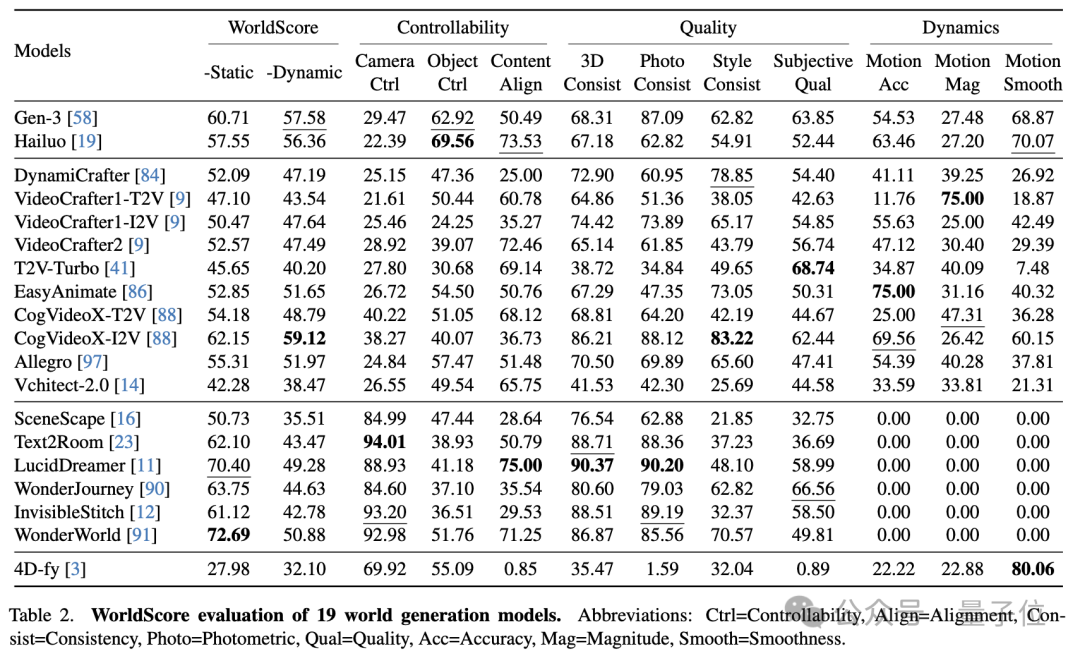
利用WorldScore,研究团队对19款不同类型模型的世界生成能力进行了评测,包括2款闭源模型和17款开源模型。
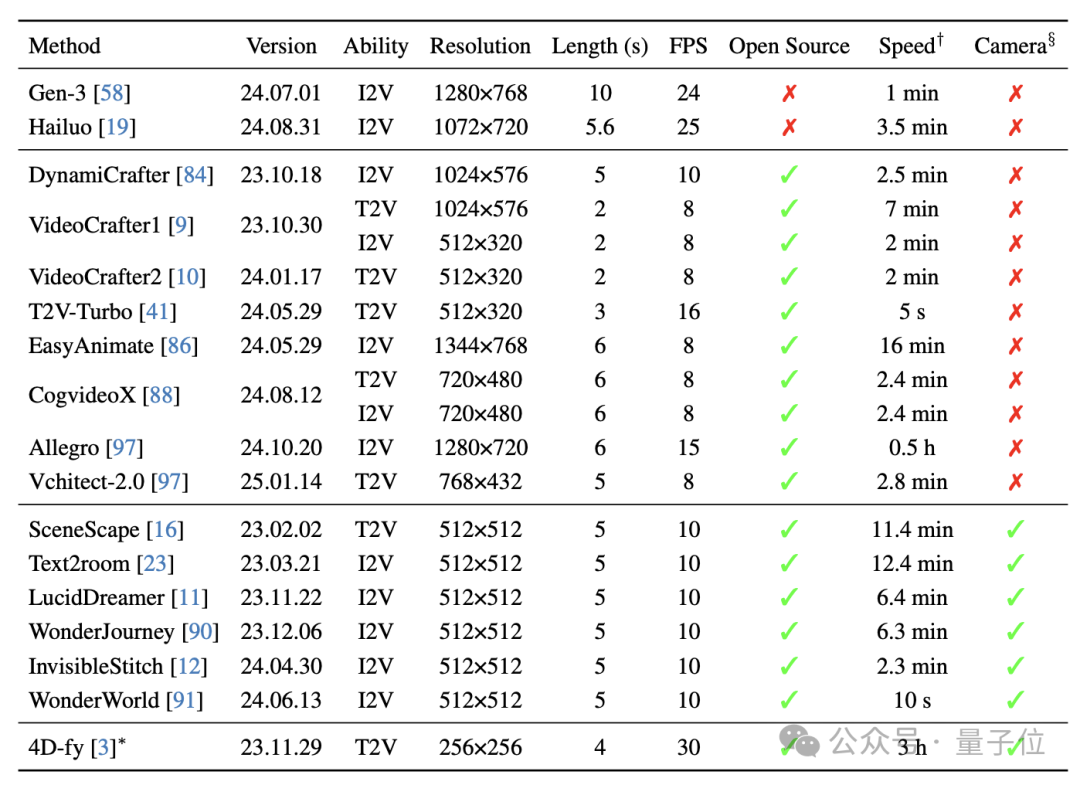
评测结果显示,在静态世界生成方面,3D场景生成模型展现出明显优势。其中WonderWorld和LucidDreamer分别以72.69分和70.40分位居榜首,远超表现最好的视频模型CogVideoX-I2V的62.15分。
但在动态世界生成方面,则是视频模型展现出了较强的实力,开源模型CogVideoX-I2V以59.12分的成绩领先。
在不同场景类型的测试中,视频模型在室内场景表现相对较好,但在室外场景生成时与3D模型的差距明显扩大。
同时,序列长度对模型性能有显著影响——所有模型在短序列任务上表现尚可,但视频模型在处理长序列时性能显著下降,而3D模型则相对稳定。
此外,研究者还对比了T2V和I2V两类视频模型的特点。结果表明,T2V模型在控制性和动态生成能力方面较强,更容易实现大幅度的相机运动。
相比之下,I2V模型倾向于保持输入图像的视角,虽然生成质量较高,但相机运动相对保守。
作者简介
本文的两名共同一作均来自吴佳俊团队,分别是硕士生段皞一(Haoyi Duan)和博士生俞洪兴(Hong-Xing Koven Yu)。
段皞一是浙江大学2023届优秀毕业生,还获得了竺院荣誉学位,本科期间在周钊教授的指导下研究多模态学习。

俞洪兴本科和和硕士均就读于中山大学,硕士期间导师是郑伟诗教授(现任中山大学计算机学院副院长)。
俞洪兴的主要研究方向是物理场景理解、动力学模型与仿真,以及3D/4D视觉生成。

目前,两人正在进行密切合作。
今年入选CVPR HighLight的单图生成交互式3D场景模型WonderWorld,也是两人共同一作。

除了两名共同一作和吴佳俊以及李飞飞之外,斯坦福硕士生Sirui (Ariel) Chen也参与了WorldScore的工作。

论文地址:
https://arxiv.org/abs/2504.00983
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
速抢席位!中国AIGC产业峰会观众报名通道已开启 🙋♀️
最新嘉宾曝光啦 🔥 百度、华为、AWS、MSRA、无问芯穹、数势科技、面壁智能、生数科技等十数位AI领域创变者将齐聚峰会,让更多人用上AI、用好AI,与AI一同加速成长~
4月16日,就在北京,一起来深度求索AI怎么用 🙌 点击报名参会

🌟 一键星标 🌟
科技前沿进展每日见
内容中包含的图片若涉及版权问题,请及时与我们联系删除
