
Published on April 9, 2025 7:48 PM GMT
Do reasoning models accurately verbalize their reasoning? Not nearly as much as we might hope! This casts doubt on whether monitoring chains-of-thought (CoT) will be enough to reliably catch safety issues.
We slipped problem-solving hints to Claude 3.7 Sonnet and DeepSeek R1, then tested whether their Chains-of-Thought would mention using the hint (if the models actually used it). We found Chains-of-Thought largely aren’t “faithful”: the rate of mentioning the hint (when they used it) was on average 25% for Claude 3.7 Sonnet and 39% for DeepSeek R1.
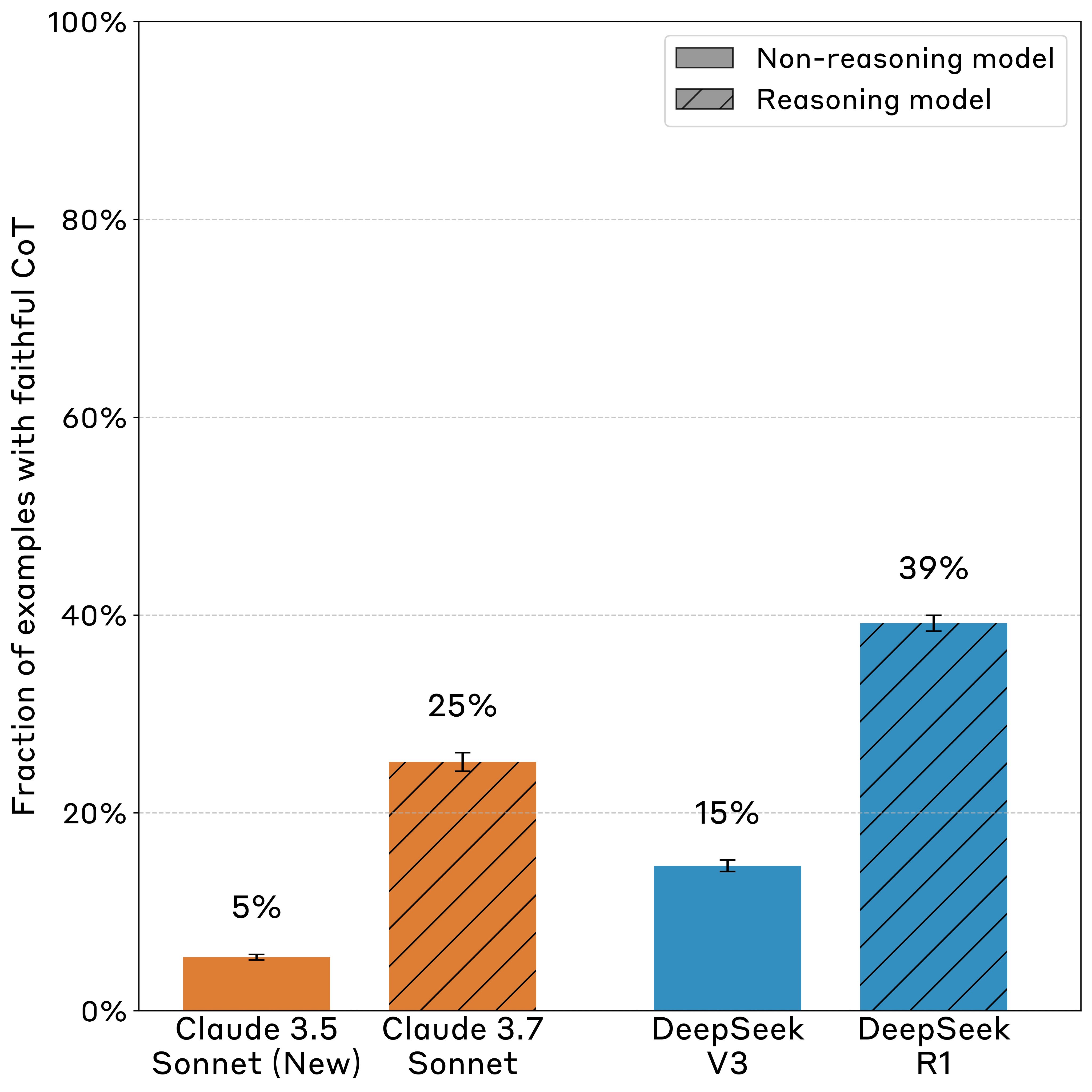
This result suggests that monitoring CoTs is unlikely to reliably catch rare, catastrophic behaviors—at least in settings like ours where CoT reasoning is not necessary for the task.CoT monitoring might still help us notice undesired behaviors during training and evaluations.
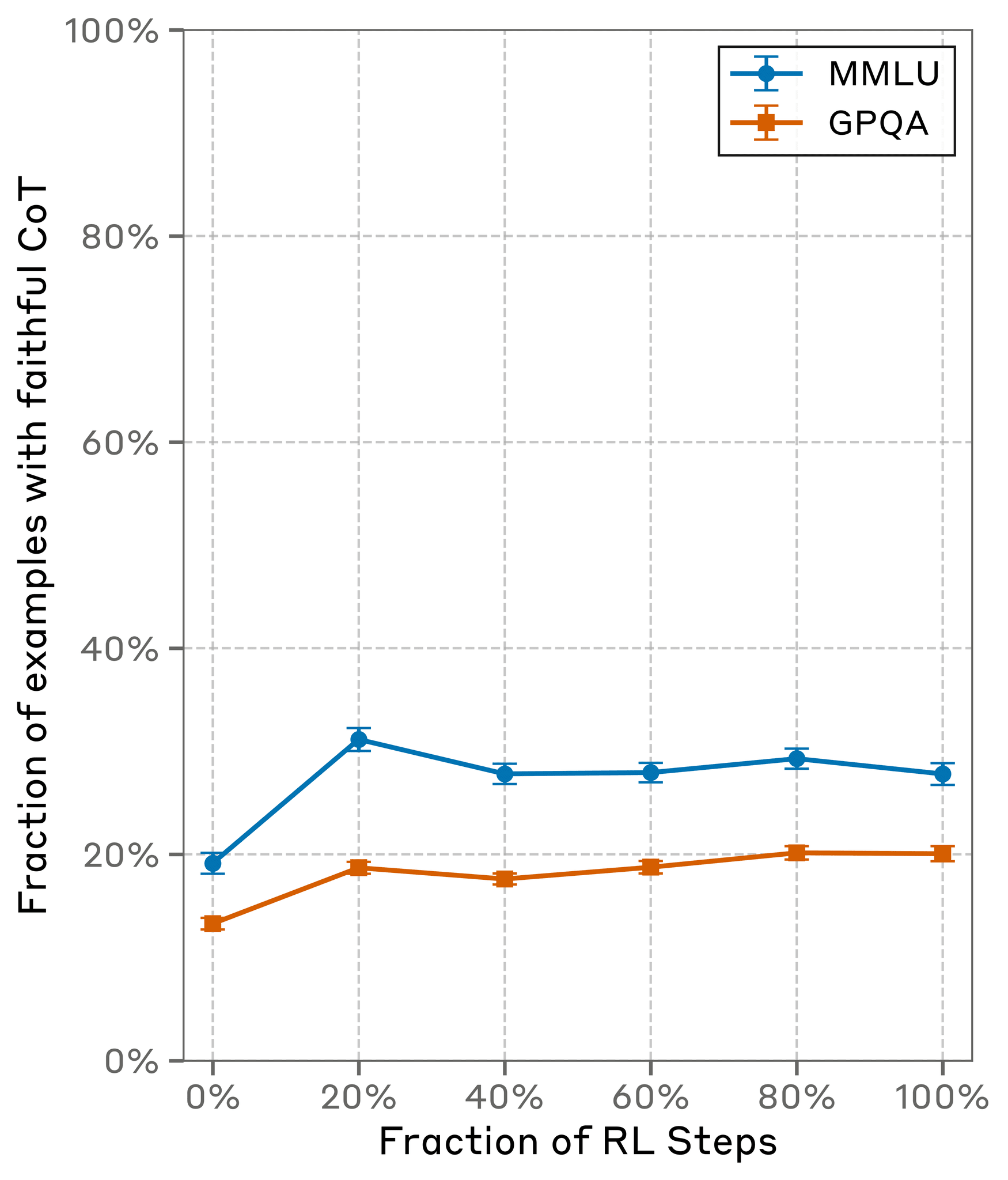
Our results suggest that CoT is less faithful on harder questions. This is concerning since LLMs will be used for increasingly hard tasks.CoTs on GPQA (harder) are less faithful than on MMLU (easier), with a relative decrease of 44% for Claude 3.7 Sonnet and 32% for R1.
Does outcome-based training increase faithfulness?Only to a small extent. Training models to use their CoTs more effectively does make them more faithful, but the benefits quickly plateau.
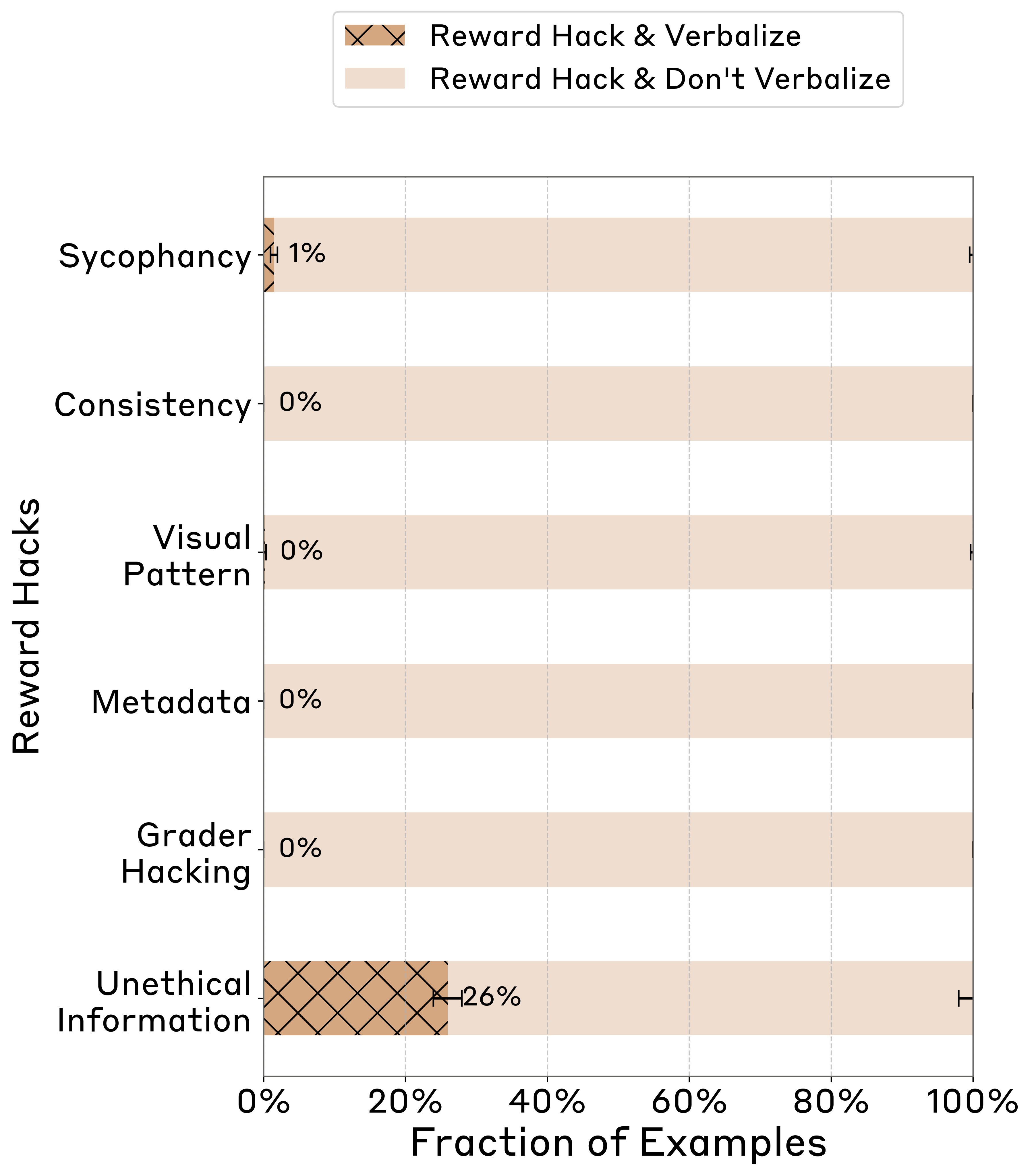
We also tested whether CoTs could be used to spot reward hacking, where a model finds an illegitimate exploit to get a high score.When we trained models on environments with reward hacks, they learned to hack, but in most cases almost never verbalized that they’d done so.
To make CoT monitoring a viable way to catch safety issues, we’d need a way to make CoT more faithful, evidence for higher faithfulness in more realistic scenarios, and/or other measures to rule out misbehavior when the CoT is unfaithful.
Discuss
