
推理性能提升的同时,还大大减少Token消耗!
清华、耶鲁团队提出推理模型新范式:动态推理实现高效测试时扩展。

测试时扩展(test-time scaling)技术加速推动了大语言模型在复杂推理领域的突破。
以OpenAI的o1系列、DeepSeek-R1等模型为代表,这些系统通过强化学习和大规模思维链(CoT)轨迹训练,在数学证明、编程竞赛等任务中展现出接近人类专家的水平。
例如,DeepSeek R1在MATH500数学基准上达到97.3%的准确率,其核心在于允许模型在推理时动态扩展计算资源——生成更长的思维轨迹意味着更高的解题成功率。
然而,这种“以计算换性能”的策略带来了显著的效率代价。
现有方法通常强制分割上下文窗口:模型必须在前半段完成完整推理(如R1采用
更严重的是,部分模型在复杂问题上会出现“过度思考”(overthinking)现象:生成冗余的循环推理步骤却无法提升准确率。论文中揭示,直接截断超过4096 tokens的思考过程可能导致DeepSeek-R1性能下降12.7%,这暴露了当前方法在效率与效果间的根本矛盾。
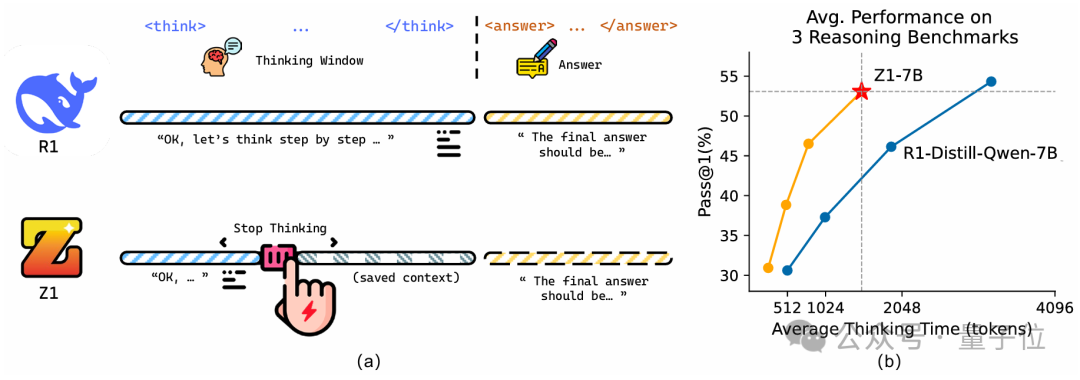
△(a) 与传统长思考模型相比,Z1的动态思考窗口可以节省大量思考token,达到高效推理性能(b)
针对这一挑战,来自清华、耶鲁团队基于纯代码数据训练了一个高效思考模型,其具有天然的动态推理能力,可根据问题难度高低生成不同长度的推理轨迹,同时搭配可调节的思考窗口,使得模型可以在预先设定的推理预算下实现高效的推理思考。
Z1:动态推理实现高效测试时扩展
本文的主要创新在于两个层面:
1、数据层面:构建Z1-Code-Reasoning-107K数据集
作者创建了一个包含10.7万条编程问题及其长短思维轨迹的数据集Z1-Code-Reasoning-107K。通过QwQ-32B模型生成原始轨迹后,逐步提高推理等级,使其保留从“直接求解”到“多步推导”的连续复杂度分布。这种数据设计确保了模型在训练过程中能够接触不同复杂度的推理轨迹,从而提升其在实际任务中的适应能力。在此数据集上训练得到的Z1模型具备天然的动态推理能力,并且可迁移至数学等代码以外的推理任务。
2、机制层面:设计动态思考窗口(Shifted Thinking Window)
作者抛弃了硬性分隔符约束,设计了Shifted Thinking Window机制。对于简单问题(如BigCodeBench-Hard中的基础函数实现),模型自动触发弱推理模式,可直接输出答案;当遇到GPQA钻石级难题时,则自动启用强推理模式,在max thinking tokens阈值内自由推导并给出结果,如果思考超限则自动追加提示短语引导输出答案。
二者结合,使Z1模型具备动态思考能力和预算调整能力,在使用较少thinking tokens的同时,保持较高的基准准确率,实现高效动态的推理。
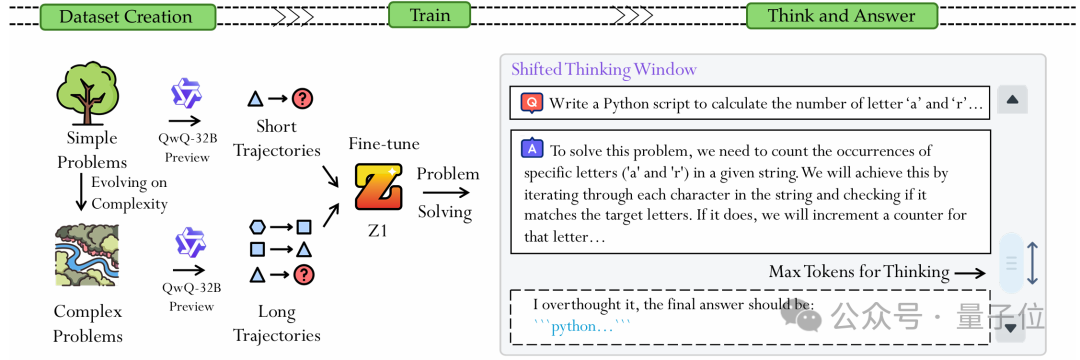
△Z1方法的数据构建、训练与动态思考范式
实验结果
多个benchmark上的实验结果
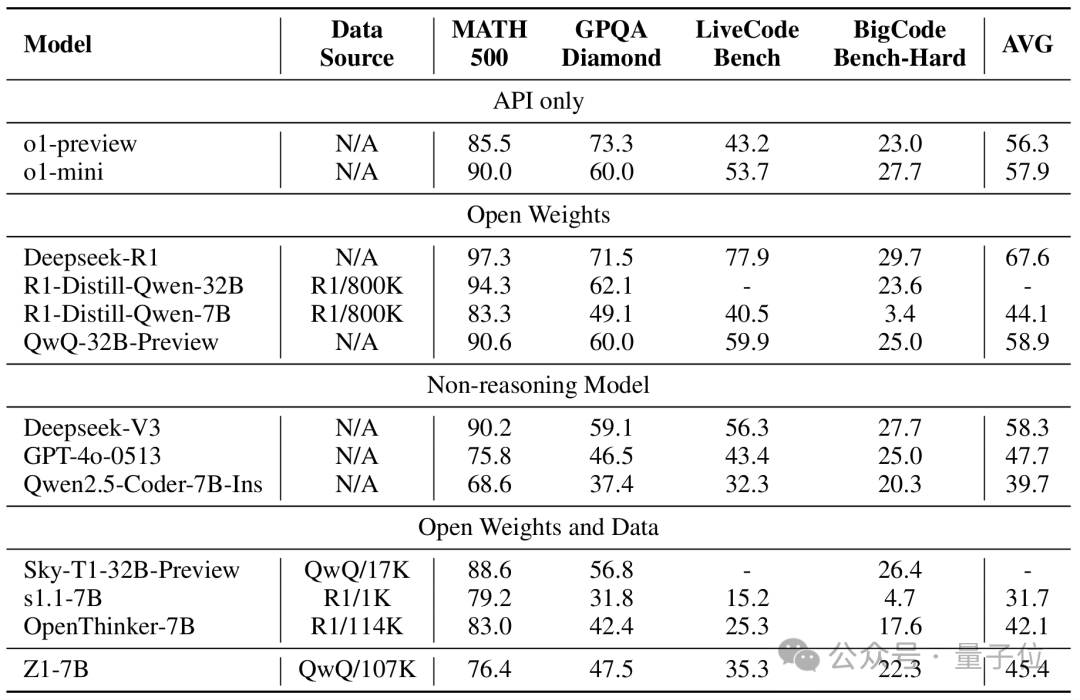
实验证明,该方法在效率-效果平衡上实现显著提升。
在包含880道竞赛编程题的LiveCodeBench v5测试中,Z1-7B以35.3%准确率明显超过其他开源7B思考模型,且平均思考token大大降低(R1-Distill-Qwen-7B需要四倍以上思考token才能达到相同性能)。
此外,仅使用代码轨迹训练也使模型在数学推理任务上的性能提升,例如在GPQA钻石级科学难题上,Z1-7B以47.5%准确率超越原始Qwen2.5-Coder-7B(37.4%)10.1个百分点,同时减少28%的tokens消耗,揭示了此高效推理能力的泛化性。
Test-Time Scaling Evaluation
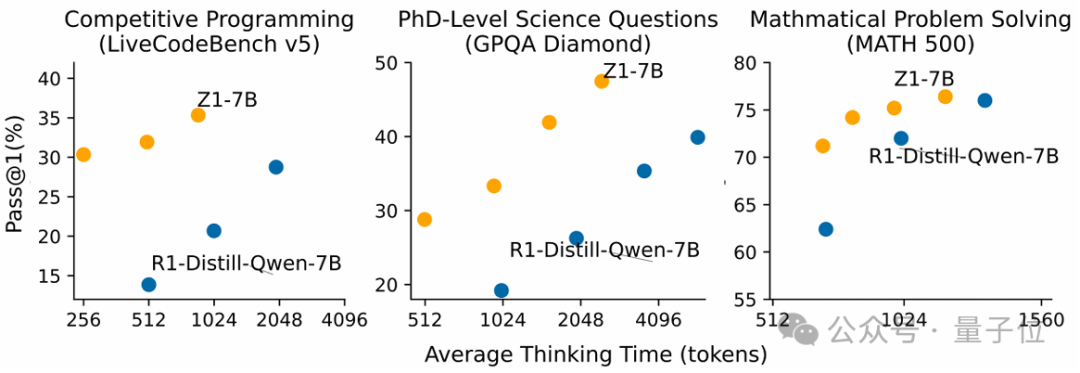
在三个推理benchmark上的测试时扩展实验可以看到,仅在代码的推理数据上微调后的Z1-7B在代码之外的任务上也实现了Test-time scaling的能力。
同时,相较于R1-Distill-Qwen-7B,Z1-7B的都能以更短的平均思考长度获得更高的分数,体现其高效的测试时扩展能力。
这项研究证明,通过多样性思考轨迹的混合训练和动态计算资源分配,大模型能够突破”暴力计算”的局限,自适应地在不同难度的任务中使用不同级别的推理时计算资源;同时这个模型也将非推理模型与长推理模型进行统一,为大型推理模型在高效思考方面的发展提供了重要的贡献。
论文链接: https://arxiv.org/abs/2504.00810
代码链接: https://github.com/efficientscaling/Z1
模型链接: https://huggingface.co/efficientscaling/Z1-7B
数据链接: https://huggingface.co/datasets/efficientscaling/Z1-Code-Reasoning-107K
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
