

在一些需要慢思考的场景中,如数学问题求解或科学研究,大型推理模型(LRM)需要在给出最终回答之前,进行分析性和深思熟虑的推理。
然而,LRM 深思熟虑的推理过程导致其资源消耗极高,带来了 token 消耗大、内存开销高和推理时增加等一系列挑战,这不仅增加了服务公司的推理成本,也降低了用户的体验。
以往针对 LLM 推理效率的研究,如模型压缩、高效模型设计和系统级优化等,虽然能够缓解高内存开销和推理时增加的问题,但并非专门为 LRM 设计,无法有效地解决 LRM 中 token 低效的问题。
为此,来自新加坡国立大学的团队及其合作者进行了专门针对 LRM 的高效推理方法的综述,重点关注在保持推理质量的同时缓解 token 效率低下的问题。主要贡献如下:
对当前的 LRM 高效推理方法进行了全面的论文综述,并进行了分层分类,即显式紧凑型思维链(explicit compact CoT)和隐式潜在型思维链(implicit latent CoT),以及优缺点讨论。
从性能和效率的角度对最新方法进行了实证研究,并从用户控制、可解释性、安全性和应用方面总结了 4 个挑战:用户可控推理、推理可解释性与效率平衡、安全保障和应用拓展。
强调了从模型合并、非自回归架构和 agent 路由的角度进一步改进现有方法的技术见解。
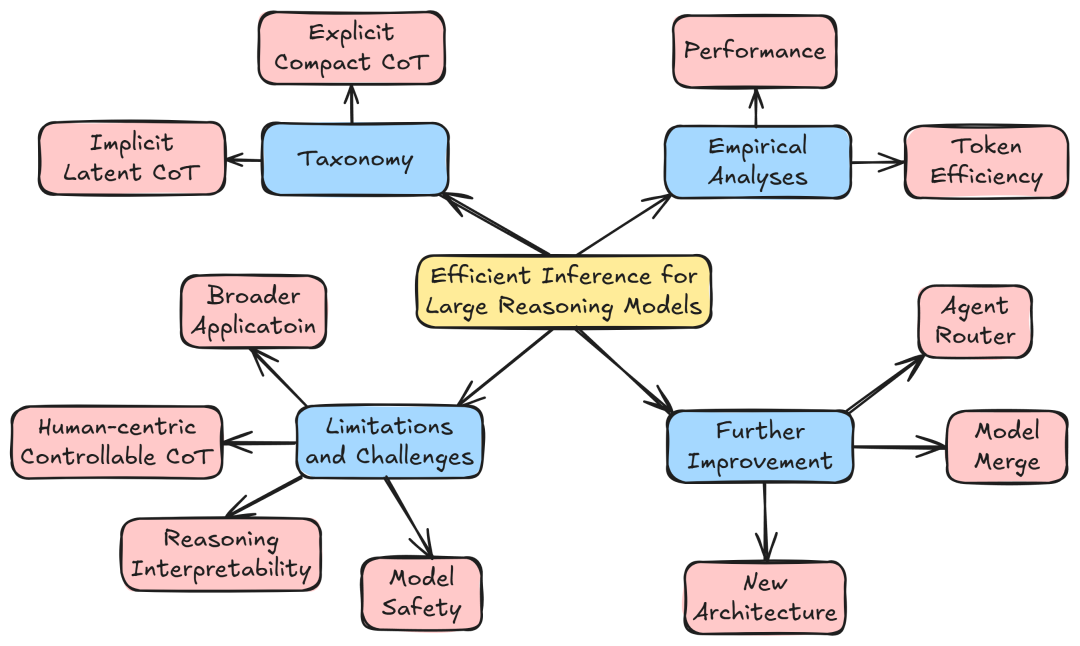
图|综述框架
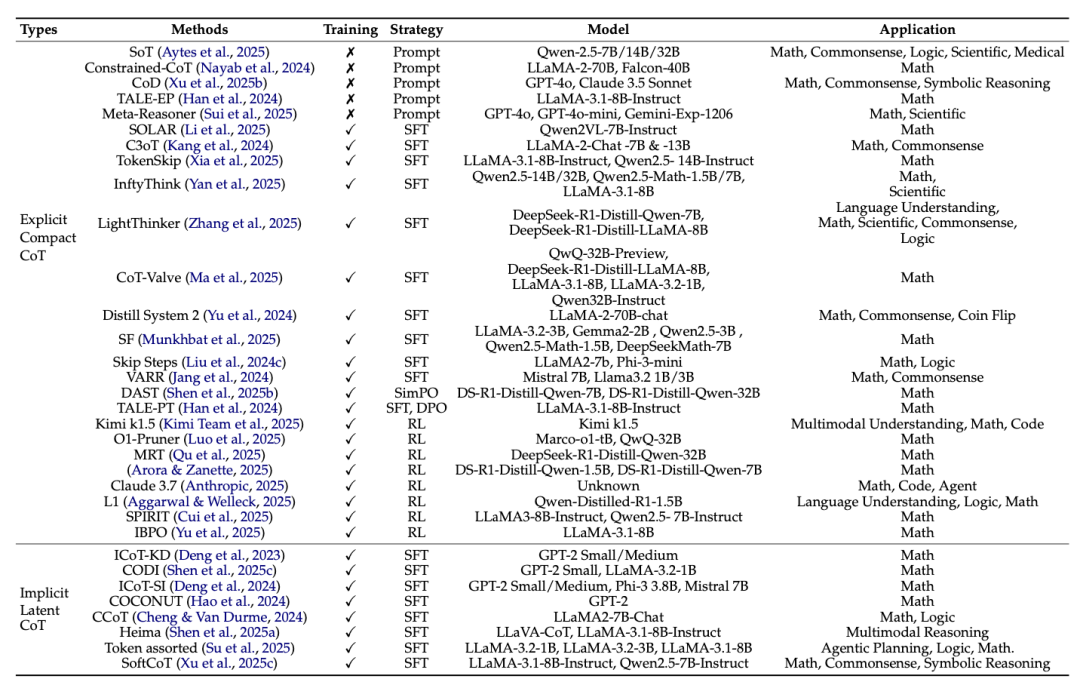
图|大型推理模型的推理方法分类
相关研究论文以 Efficient Inference for Large Reasoning Models: A Survey 为题,已发表在预印本网站 arXiv 上。
LRM 的两大分类
根据当前的研究形式,研究团队将 LRM 分为了两大类:
显式紧凑型 CoT,通过引入显式指令、奖励或预算约束来鼓励使用较短的推理链,而不是冗长的 CoT。
隐式潜在型 CoT,将显式的长 CoT 压缩为紧凑、连续的推理状态。
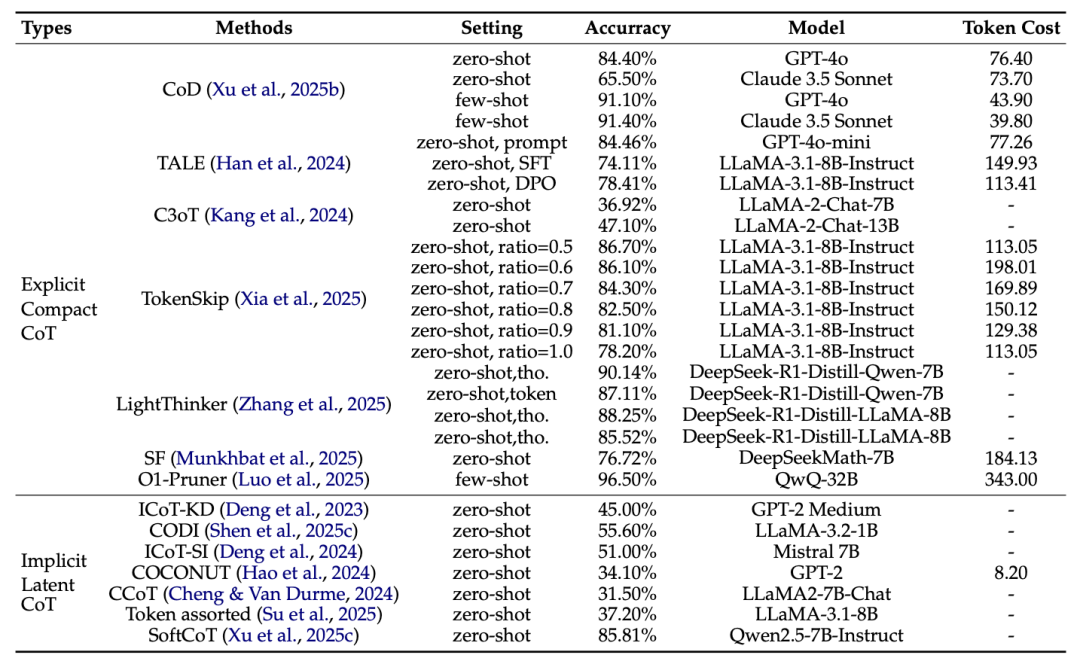
图|GSM8K 数据集上最新推理方法的基准测试
研究团队认为,隐式潜在型 CoT 在推理准确度上可以超过显式紧凑型 CoT,同时也能够显著降低生成的成本。
1.显式紧凑型 CoT
最近的研究关注如何在保持推理准确性的同时,开发更紧凑的推理路径:
CoT 压缩。通过将中间推理限制在必要步骤、使用一个小的路由模型生成推理草图、动态调整推理 token 等方式,在保持解决方案质量的同时简化推理过程。但可能会牺牲透明度,存在忽略关键的中间逻辑的风险,这可能会破坏可解释性。
基于紧凑推理链的微调。利用 LLM 生成压缩的长 CoT 版本、整理专家验证的简洁答案、标注数据集进行微调等方法,提高了 LRM 的效率,但成本高,并且依赖于精心整理的数据集和大量再处理工作,限制了它们对开放式领域的适应性。
基于奖励的激励。越来越多的研究引入明确的奖励信号,例如基于长度的奖励以抑制冗长的推理;利用强化学习训练模型以进行动态资源分配;基于推理成本控制推理分布;平衡对心推理路径的探索与对简洁、已验证推理路径的利用;交互式或用户导向的长度控制机制。
但是,这类激励信号可能导致模型倾向于简单答案,影响复杂任务的深度推理。并且,仅靠效率不足以实现实际部署,现实的应用程序需要在紧凑性、推理鲁棒性、可解释性和域泛化(domain generalization)之间取得平衡。

图|显式紧凑型 CoT 的要点
2.隐式潜在型 CoT
隐式潜在型 CoT 则通过将推理从显式 token 转移到潜在 token,在隐藏层而非自然语言中编码推理,以此提升 token 效率。用知识蒸馏、潜在嵌入、沉思 token 等方法,优化了各个层面的推理,在保持准确性的同时减少了延迟。
这类方法通过内化推理步骤提高效率,在推理准确性上甚至可以超越显式 CoT 方法,且能显著降低生成成本,展现出良好的可扩展性,但牺牲了模型的可解释性,使得推理过程难以验证。

图|隐式潜在型 CoT的要点
研究团队认为,未来的工作应侧重于从潜在表征中提取人类可解释的推理痕迹,从而实现效率和透明度的平衡。
局限性和挑战
此外,研究团队也从用户体验、可解释性、安全性和应用性的角度,讨论了现有推理方法的局限性和挑战。

图|局限性和挑战的要点
在用户体验方面,尽管部分 LRM 已支持用户配置推理模式,使用户能够调整推理深度,在透明度和效率之间取得平衡,同时优化用户体验,但还需探索更精细的控制机制,可以侧重于用户的交互式和个性化推理。
在可解释性上,当前为提高效率的方法可能会降低可解释性,比如减少显式推理步骤或转向潜在表示推理,使得理解模型结论的得出过程变得困难。未来的研究应开发适应性推理策略来平衡效率和可解释性。
当涉及安全性时,现有高效推理方法在提升 token 效率的同时,可能会破坏 LRM 的安全对齐,增加越狱攻击和隐私泄露等风险。未来的工作应在训练中整合安全约束,并制定更强有力的基于推理的保障措施。
从应用的角度来看,在社会科学、情感智能和创意写作等领域,LRM 存在开放式问题,比如难以制定明确目标,且高计算需求和延迟限制了其在时间敏感领域的应用。高效的推理方法则可以提高 LRM 在更广泛应用中的可行性,例如实时应用程序和开放式任务。
3 个方法,提高推理效率
那么,如何提高 LRM 的推理效率呢?
研究团队从新架构、模型合并、agent 路由 3 个方面提出了提升 LRM 推理效率的策略。
在新架构方面,主要包括混合自回归和扩散模型、内存高效 transformers 和基于图的推理,是进一步提高推理效率同时保持推理质量的潜在技术。
在模型合并上,将传统 LLM 和 LRM 的模型权重合并,使合并后的模型兼具 LLM 的快速响应和 LRM 的推理能力。但在模块选择、权重分配和架构兼容性方面存在挑战。
agent 路由则是根据任务难度为不同的 LRM 分配资源,以优化推理效率。目前包括两种路由策略:一是基于路由模型,通过训练一个独立的路由模型,根据输入任务的特征决定使用哪个 LRM;二是基于信心指标,利用模型对自身预测的信心程度来选择合适的 LRM 。

图|进一步优化的要点
如需了解更多详情,请查看原论文。
论文链接:https://arxiv.org/abs/2503.23077
整理:锦鲤
如需转载或投稿,请直接在公众号内留言
内容中包含的图片若涉及版权问题,请及时与我们联系删除
