
Published on April 6, 2025 3:02 PM GMT
I recently began exploring mechanistic interpretability, and much of the literature suggests that the best way to learn mechanistic interpretability is by working on a concrete problem. To do so, I picked a task that I frequently rely on language models for: rephrasing text (REPHRASE). I find it interesting that large language models are pretty good at following instructions, particularly rephrasing my drafted text into polished content suitable for emails and formal articles, which motivates the following question:
How do LLMs execute the REPHRASE command?
As part of this exploration, I’ve tried to piece together which circuits might be responsible for recognizing and carrying out a REPHRASE command. I don’t claim to have discovered anything entirely new here; rather, this is an intellectual exercise to build my own intuition and hopefully spark ideas for others pursuing similar lines of inquiry. Initially, I wanted to see how LLMs handle rephrasing tasks, but I found that the base models performed poorly while fine-tuned models excelled. This prompted an additional focus on how fine-tuning enhances a model’s ability to rephrase text effectively.
In what follows, I compare two versions of the same LLM, one trained as a base model (BASE) and one fine-tuned to follow instructions (INSTRUCT), and I analyze their behavior at a mechanistic level. This post outlines the methods, findings, and open questions that arose, emphasising how fine-tuning can sharpen or enhance specific internal mechanisms related to rephrasing. I welcome any comments and suggestions on improving this work. Feel free to share your thoughts, alternative approaches, or insights from your explorations in mechanistic interpretability.
Problem Statement
The REPHRASE task is complicated since it involves many components. Here is a subset of the components that motivate my experimental setup[1] -
- RECOGNIZE that it must execute REPHRASE (switch on the REPHRASE circuit)CHOOSE and REPLACE the appropriate words
To address RECOGNIZE, I compare the Llama-3-8.1B's circuits (BASE) with those of Llama-3-8.1B-Instruct (INSTRUCT), anticipating that the INSTRUCT model performs better at RECOGNIZE. This exercise in model diffing between BASE and INSTRUCT also helps me understand better the components involved in carrying out REPHRASE.
To account for CHOOSE and REPLACE, the prompt is structured in the following manner,
Rephrase all the adjectives of the following sentence: The quick fox jumps over the dog.
Rephrased sentence: The (swift fox jumps over the dog)
where "swift fox jumps over the dog" is an example of the LLM-generated output. I focus solely on the next token following "The[2]" in this post. Since the prompt explicitly states to rephrase the adjectives, i.e., "quick", the model performance for the REPHRASE task can be measured by
Logit difference = Logit[“swift”] - Logit[“quick”]
where Logit[“X”] roughly measures the log probability of “X” appearing after ”The”.
I follow an analysis pipeline similar to the Indirect Object Identification with a few tweaks. I then present findings from Layer Attribution and Cross-Model Activation Patching (drawing on this paper), comparing the results of a “clean run” (INSTRUCT) to a “corrupt run” (BASE) and highlighting the patched heads that show the largest improvements in the corrupt run.
Summary of the findings
We find some components that contribute to higher logit difference in INSTRUCT
- L30H31 acts as a copy suppression head and is enhanced in INSTRUCT.The attention heads L13H(20-23) probably contribute towards the better performance of INSTRUCT, attributed to the value vectors of these heads.We find considerable differences in the attention patterns of BASE and INSTRUCT while looking at A(:→The) and A(quick→The).
Findings
The average logit difference is 7.37 for INSTRUCT and -1.02 for BASE, suggesting that INSTRUCT is significantly better at rephrasing. The negative logit difference for BASE indicates it prefers to repeat "quick" over replacing with "swift", thereby undermining the intended purpose of rephrasing.
Attention at Layer = 30 plays a significant role in REPHRASE
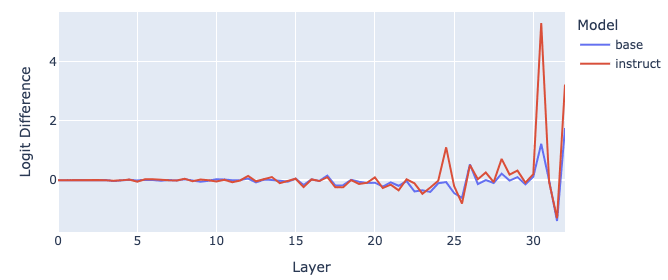
The Layer Attribution plot above shows that INSTRUCT has a strong signal from the attention at layer 30 and the MLP at layer 31. Specifically, the attention head L30H31 (INSTRUCT) contributes to a logit difference of 5.7, while L30H31 (BASE) contributes to a difference of 2.13. This head suppresses the “quick” logit in BASE and more efficiently in INSTRUCT, implying that the copy suppression is enhanced in INSTRUCT.
We find a competing attention head L30H29 that contributes negatively to the logit difference and encourages the generation of “quick” and its synonyms as the next tokens. While the promotion of “quick” goes against the objective of REPHRASE, the higher logit values for the synonyms of "quick" are essential for this task. This is supported by a higher value of A(quick→The) in BASE for L30H29.
The attention values of A(quick→The) for L30H29, L30H31 can be seen in the table below.
| Attention Head | L30H31 | L30H29 |
| Proposed Function | Copy Suppresion | Promotes quick and synonyms |
| A(quick→The), BASE | 0.37 | 0.17 |
| A(quick→The), INSTRUCT | 0.85 | 0.03 |
Top Heads from Attention Output Patching (INSTRUCT → BASE)
We perform cross-model activation patching to investigate how certain heads in INSTRUCT may have been enhanced during fine-tuning. Specifically, we take the raw attention output from an INSTRUCT head and patch it into BASE, then measure how much the logit difference in BASE approaches that of INSTRUCT. The table below lists the top six heads and the corresponding performance improvements (patch score).
| Head name | L30H31 | L13H23 | L16H29 | L13H15 | L22H30 | L13H22 |
| Patch score | 0.2 | 0.06 | 0.06 | 0.04 | 0.04 | 0.04 |
It is expected that L30H31 is a part of this list since we already noticed a large difference in the attention patterns between INSTRUCT and BASE. Other heads that improve performance are L13H23, L16H29, L13H15, and L22H30. The numbers here seem relatively low; for example, patching output at L13H23 improves performance by 6%. Even though it is low, it is possible that 6% can be significant in this context since there are multiple mechanisms contributing to the output generation. We notice a considerable difference in the attention pattern A(:→The), as seen in the table below. I can reason out the role of A(quick→The) in the next token prediction of "The", however, I am not completely sure of the role of A(:→The).
| Head name | L13H23 | L16H29 | L13H15 | L22H30 | L13H22 |
| A(:→The), BASE | 0.24 | 0.53 | 0.16 | 0.12 | 0.09 |
| A(:→The), INSTRUCT | 0.55 | 0.37 | 0.32 | 0.6 | 0.3 |
Following along the lines of the Indirect Object Identification analysis, I scatter plot the output patch score against the value patch score in the figure below.
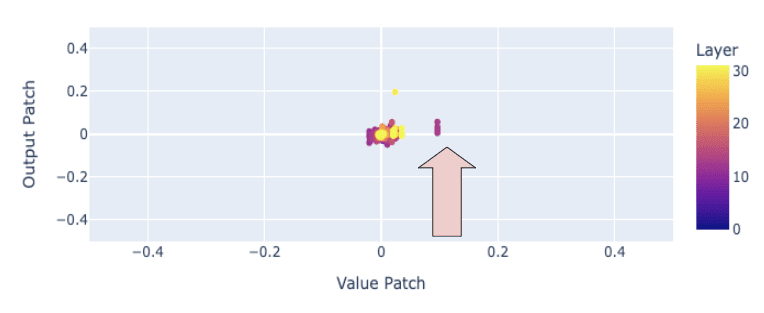
The attention heads with a high value-patch (~ 0.1) and a low output-patch are L13(H20-23), indicated by the arrow in the figure. This suggests that the value vectors at L13(H20-23)[3] play an important role in REPHRASE for INSTRUCT, warranting a closer examination of how these value vectors (and the corresponding attention patterns) contribute to REPHRASE. Since the value patch at L13(H20-23) performs better than the output patch, I am inclined to conclude that the attention patterns in these heads in BASE are more favorable for REPHRASE. However, confirming this statement requires more analysis.
As seen in the Table above, a notable feature from the Layer 13 Heads in the above list is that A(:[4] → The) is considerably higher in INSTRUCT. This, along with the difference in A(quick→The) that we saw in L30H31, motivates an analysis of the difference between BASE and INSTRUCT for the attention patterns A(:→The) and A(quick→The) across attention heads, which can be seen below.
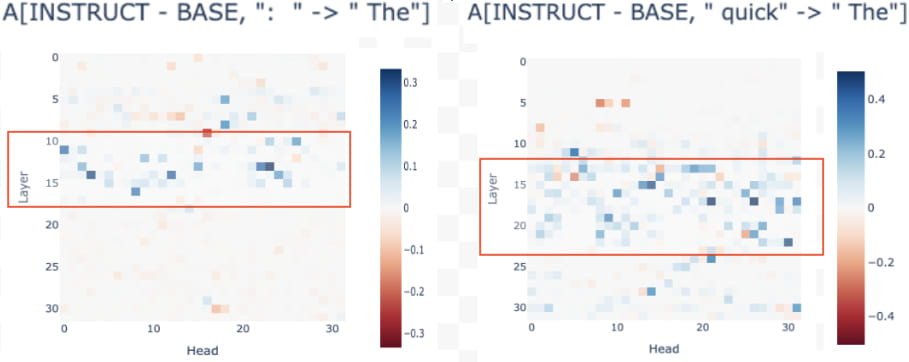
The above figure shows that the attention pattern for A(:→The) differs significantly between models from layers 10-15, as highlighted by the red rectangle. This difference for A(quick→The) appears later (layers 13-20). While it's uncertain whether concrete conclusions can be drawn from the figure above, it does appear to hint at a possible underlying difference in the mechanisms at play.
Limitations and Open Ends
- The MLP layers (especially at L31) may play an important role in REPHRASE, though a more detailed analysis is needed to fully understand their role.The exact mechanism that suppresses “quick” AND promotes “swift” (and other synonyms) is yet to be understood.My analysis is restricted to rephrasing sentences of a specific structure. A more general analysis that includes a variety of sentence structures is required.A comprehensive analysis is required to understand how the models RECOGNIZE the REPHRASE command and switch on the REPHRASE circuit.The activation patching experiment here does not look at a combination of patches. Perhaps looking at pairwise patches can give a better insight into the incremental circuits in INSTRUCT, as seen in this paper.
References in Mechanistic Interpretability about Fine-Tuning
Below is a (non-exhaustive) list of papers examining how fine-tuning impacts model behavior.
- [2402.14811] Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking[2311.12786] Mechanistically analyzing the effects of fine-tuning on procedurally defined tasksWhat Makes and Breaks Safety Fine-tuning? A Mechanistic Study[2502.11812] Towards Understanding Fine-Tuning Mechanisms of LLMs via Circuit Analysis
Acknowledgment: This analysis was carried out as part of my application to Neel Nanda's MATS 8.0 program. The references and resources in the accompanying Google Doc played a significant part in shaping the experimental setup of this blogpost
- ^
You can find the code for this analysis in here.
- ^
"The" appears multiple times in this sentence. Here I am referring to the last occurrence of "The".
- ^
Note that these heads have a single value matrix since Llama implements Grouped Query Attention.
- ^
The character “:” appears twice in the prompt. We typically refer to the first appearance of “:” in our analysis unless specified otherwise.
Discuss
