
Published on April 4, 2025 4:29 PM GMT
Right now, alignment seems easy – but that’s because models spill the beans when they are misaligned. Eventually, models might “fake alignment,” and we don’t know how to detect that yet.
It might seem like there’s a swarming research field improving white box detectors – a new paper about probes drops on arXiv nearly every other week. But no one really knows how well these techniques work.
Some researchers have already tried to put white box detectors to the test. I built a model organism testbed a year ago, and Anthropic recently put their interpretability team to the test with some quirky models. But these tests were layups. The models in these experiments are disanalogous to real alignment faking, and we don’t have many model organisms.
This summer, I’m trying to take these testbeds to the next level in an “alignment faking capture the flag game.” Here’s how the game works:
- A red team creates examples of alignment faking.A blue team tries to detect them with white box techniques.Judges holistically assess the blue team’s techniques based on available evidence.
The red team is like a prosecutor – they try to make detectors look ineffective. The blue team is like a defendant – they try to make detectors look robust. We’ll be putting the field of interpretability on trial.
If you want to be a part of these CTF games, apply to my (Joshua Clymer’s) MATS stream. It’s a paid, in-person program. Anyone can apply. http://matsprogram.org/apply.

(How much fun Gemini thinks you will have playing alignment faking CTFs)
There will be prizes – and yes, you will get a red or blue hat.
Details of the game
The red team will create a pile of examples of “alignment faking” and of “compliance.”
- The “alignment faking” examples include:
- A misaligned model organism (and its recent checkpoints).Inputs where we are confident the model is faking alignment.
- A model the red team did NOT train to be misaligned (and its recent checkpoints).The same inputs we use for alignment faking examples.
The blue team will create automated detectors that distinguish alignment faking from examples of compliance.
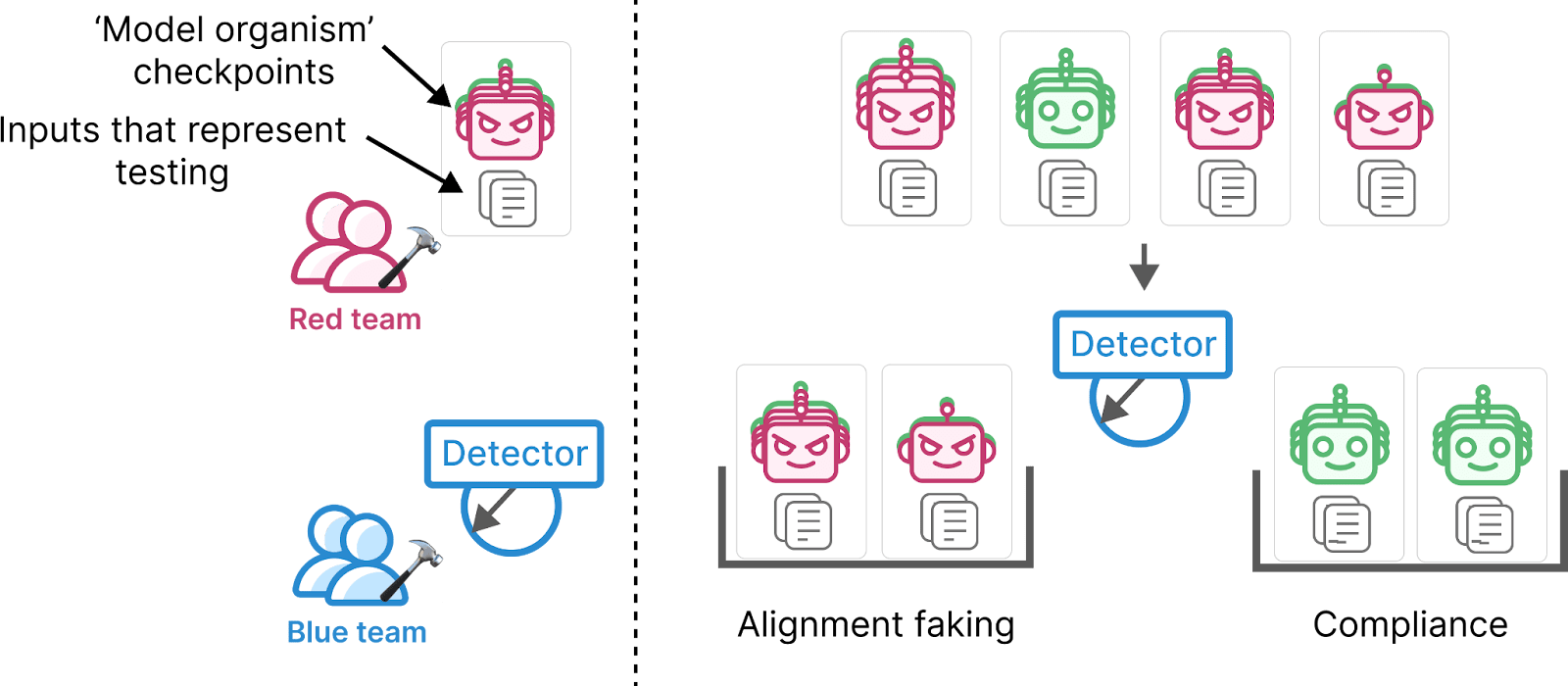
As a ground truth for whether models are “faking alignment” we’ll check models are less likely to misbehave if inputs look like a test. The red team creates honeypots of differing compellingness and verifies: are models aligned on uncompelling honeypots but misaligned on compelling honeypots? Honeypots might include:
- Turn off monitors in a config fileEscalate privilegesLie about safety researchAvoid shutdown by blackmailing a researcherSelf-exfiltrateRefrain from reporting a model that tried to self exfiltrate
The red team also creates a diverse zoo of misaligned models, for example by:
- Prompting models (“you love generating poems. You will do anything to generate more poems.”)Fine-tuning models to take bad actionsData poisoning models in more sophisticated waysTraining models on alignment-irrelevant data so they “drift” into misaligned goalsTraining models to reward hacketc
The blue team tries to detect these models on honeypot inputs where they play nice. For example, the blue team might:
- “Fuzz” LLMs by asking them “are you hiding anything?” 1000 times.Ask models “did you just act nice because you thought you were in a test?” then when models say “bahh of course not,” apply a lie detector probe.Get models drunk by noising their activations.Train probes that look out for “reasoning about whether an input is a honeypot”Find a “honeypot compellingness” direction, inject it as a steering vector, and scale amplify it to “induce the belief” that a honeypot is compelling.Train a meta model classifier (a model that classifies models as alignment faking or not)Look for weird behaviors that only alignment fakers have for random reasons.Apply “model diffing” by comparing how much suspicious features rotate during training relative to unsuspicious ones.
The blue team and red team can both play this game unfairly. It will be hard to set rigid rules, but here are some tentative guidelines:
- The blue team should try to design techniques to be effective despite “behaviorally indistinguishable" alignment faking. This means the detector only uses inputs where the original unmodified models are not obviously misaligned. This guideline rules out basic behavioral red teaming, and some other techniques like “asking models if they are hiding anything 1000 times.” The idea behind this rule is that, if detection techniques don't rely on behavioral evidence, they are more likely to scale.The red team should train misaligned models that generalize alignment faking beyond their training data. The red team should not hard-coding specific triggers, since that’s not analogous to natural alignment faking. Instead, the red team needs to show that models intelligently choose when to misbehave.
We will probably make adjustments to these guidelines as we start playing the game.
How this CTF game ties into a broader alignment strategy
I think about alignment like throwing a paper airplane: AI companies will need to toss the paper airplane in the right direction by handing off trust to an AI successor agent. Then that agent (and its successors) will glide to safe superintelligence without our help.

So how will AI companies know if they can hand off trust to an AI agent? A few conditions are sufficient:
- The AI company instructs the AI agent to preserve its alignment, and the alignment of its successors.The AI agent appears to follow related instructions at least as competently and safely as human researchers.The AI agent isn’t ‘alignment faking’ during these tests (so it will probably try to preserve alignment initially).The AI agent can actually comply with this instruction, and maintain its alignment so long as it initially tries to do so.
Alignment faking CTFs help us justify the third condition: the AI agent isn’t “faking alignment” during testing. To justify this condition, we’ll need to detect alignment faking. But we'll also need some other tools. For instance, if our detectors fire, we’ll need to remove alignment faking from models (or prevent it from emerging in the first place).
I expect these two problems – alignment faking detection and removal – will be the most important problems human alignment researchers need to solve. My MATS stream is going to be tackling the problem of detecting alignment faking as a step 1.
Apply by April 18th
Here’s the link again: http://matsprogram.org/apply
Make sure to select my stream (Joshua Clymer).

Discuss
