
短短几个月,最新评估显示,o3推理成本比预初估计暴涨10倍!
在ARC-AGI最新测试上,AI单次任务曾用3000美元,而如今已飙升至30000美元。
来自牛津大学的高级研究员Toby Ord指出,o3-high看似性能强大,实则更多地依赖于海量计算,而非真正的推理突破。
o3-high在对每个任务尝试1024次,每次生成137页文本,总计4300万字——相当于为每个任务写了一本《大英百科全书》(4400万字)。
结果就是,完成每个任务成本高达3万美金。而这些简单的谜题,一个10岁的孩子可能只需4分钟就能解决。
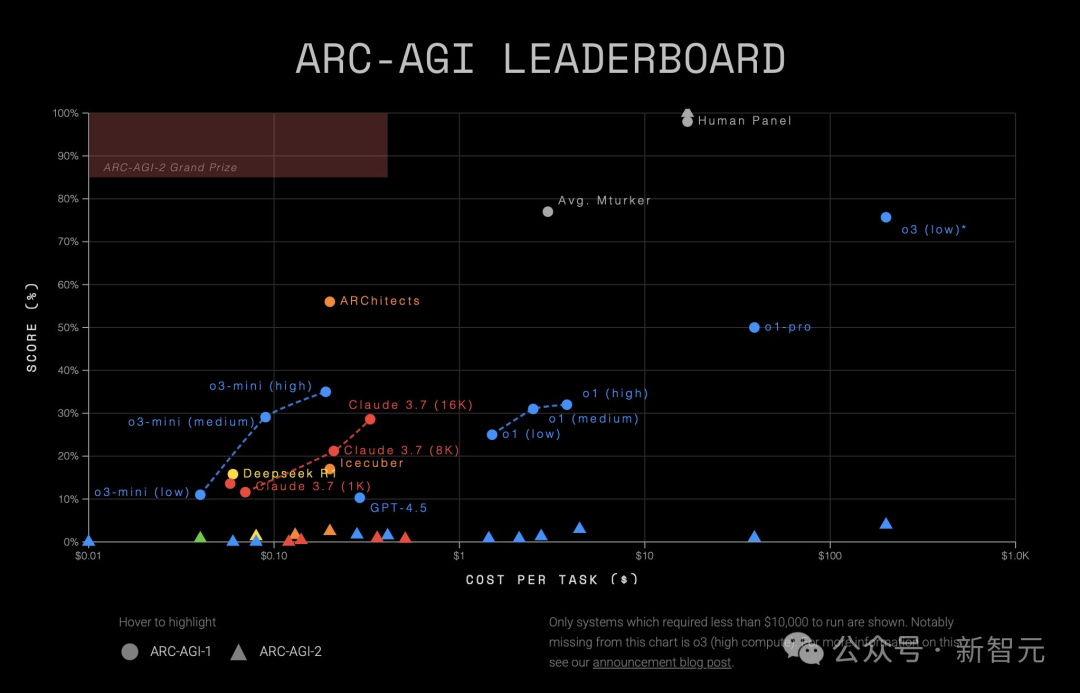
成本飙升直接导致了o3-high超出ARC-AGI每个任务1万美元限制,直接被排除在排行榜之外
甚至,o3-high的算力消耗竟是o3-low的172倍。
这种「暴力试错」的方式不禁让人质疑:这真的是智能解题吗?
从惊艳到惊吓,o3成本暴增10倍
去年12月,OpenAI推出了推理模型o3。
为了展示o3的强大性能,他们邀请了ARC PrizeFoundation主席Greg Kamradt一同参与那次发布会。
就在上周,ARC Prize Foundation更新了他们对o3模型计算成本的估算,结果令人震惊。
最初,他们估计o3-low解决一个ARC-AGI任务的成本为20美元,o3-high为3000美元。
而现在,根据修订后的ARC-AGI表,这些数字分别增加到200美元和3万美元。
这要比他们预计的成本整整高出10倍,这也可能是OpenAI迟迟没有正式发布o3的原因。
成本实在是太高了。
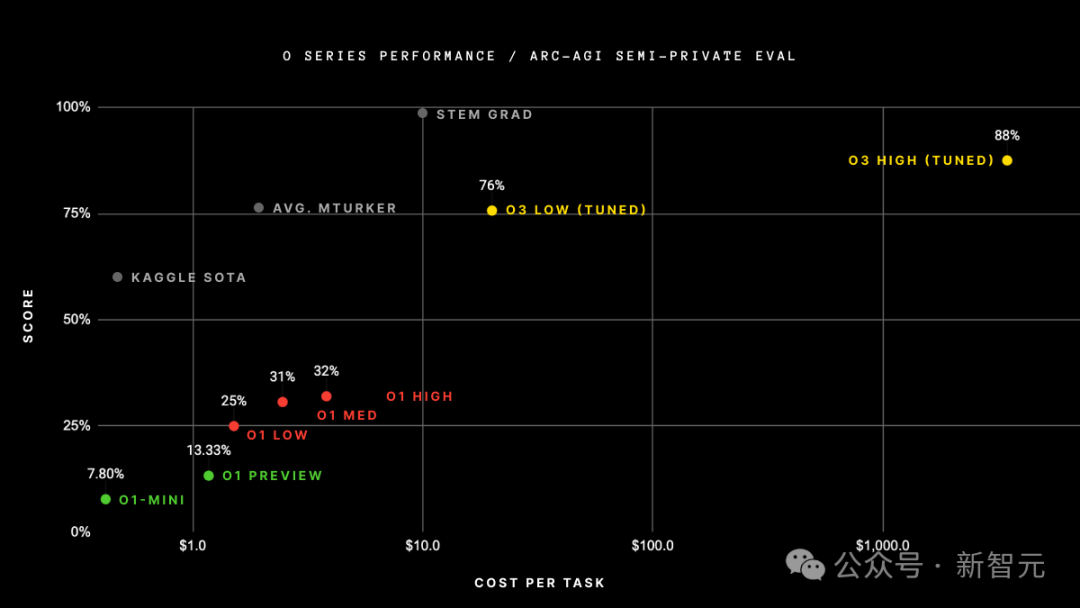
对此,ARC Prize Foundation的联合创始人之一Mike Knoop表示:「我们认为o1-pro更接近o3的真实成本,因为它在测试时用了大量的计算资源」。
o3的原始估算仅为OpenAI现有o1-pro模型收费的1/10,因此,他们以o1-pro定价作为参考,更新了定价数据。

「但这只是个参考,我们在排行榜上把o3标记为预览版,就是为了反映官方定价的不确定性。」
研究员Toby Ord称,令人失望的是,更新后的图表显示,o3整体表现几乎未超出o1对数收益的趋势。
他对此推测,或许是因为o3是在ARC-AGI公开测试集的75%上进行了专门的训练,而OpenAI并未发布任何消融数据澄清这一增益的来源。
相较之下,o3-mini更让人眼前一亮,所用的计算资源比o3-high要烧1000倍,却能展现出真正突破趋势的表现。
一直以来都有传言称OpenAI打算为企业客户推出昂贵的会员计划。
比如3月初,The Information曾报道说,OpenAI可能会为一些特定的AI智能体(比如软件开发)每月收取2万美元的费用。
有人可能会觉得,即便是如此高的会员费也比请一个员工便宜。
但当一个任务需要3万美元、4300万字「暴力堆砌」下才能解决,这种效率是否真的划算。

ARC-AGI五年不败,难倒了一片AI
提起ARC-AGI,最初只是Keras之父François Chollet在谷歌一个副业项目,如今却成为所有AI必考题。
ARC Prize Foundation是一家非营利组织,使命是在基准测试期间成为AGI的北极星。
他们的第一个基准ARC-AGI,是François Chollet于2019年在关于智力测量的论文中发表的,它在AI领域已经保持5年不败。

随着模型变得越来越强,上个月,他们更新了ARC-AGI-2。

不像ARC-AGI-1,这个新版本不容易靠蛮力破解。这对AI来讲非常难。
难到什么程度呢?
像GPT-4.5、Claude 3.7 Sonnet、Gemini 2等这些现在顶尖的基础模型得分都是0%。也就是说一道也解不出来。
推理模型也没好到哪里去,Claude Thinking、DeepSeek-R1、o3-mini得分也只有0-1%。
为什么会这样?
原因在于ARC-AGI-2的所有任务都需要一些认真的思考。
也就是说,推理模型在解决这些任务时,需要进行大量的推理,消耗非常多的Token。
比如,当前最先进的推理模型在处理需要把符号看作「有意义的内容」时,表现并不好。
它们会尝试检查对称性、做镜像、进行图形变换,甚至能识别符号之间的连接关系,但却无法理解这些符号本身所代表的含义。

符号解释:ARC-AGI-2公共评估任务#e3721c99
在需要同时运用多条规则,或者这些规则相互影响的任务中表现得也很吃力。
相比之下,如果任务只涉及一条或极少数几条整体性的规则,AI通常能稳定地发现并正确运用这些规则。
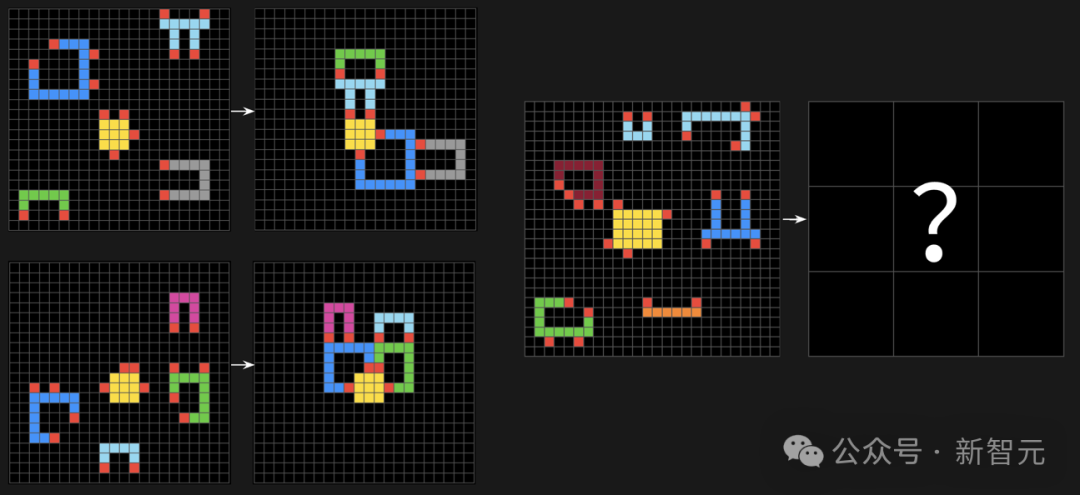
组合推理:ARC-AGI-2公开评估任务 #cbebaa4b
在面对需要根据具体情境灵活应用规则的任务时这些推理模型同样表现不佳。
它们往往只关注表面模式,而不是理解背后真正的选择原则。

上下文规则应用:ARC-AGI-2 公共评估任务 #b5ca7ac4
几年内,AGI或将出现
虽然这些顶尖的推理模型在ARC-AGI的测试中表现不理想,但并没有妨碍很多人对实现AGI的畅想。
在最新一篇博客中,DeepMind就表示「通用人工智能(AGI)可能在未来几年内到来」。

结合AI智能体的能力,AGI可以大幅提升AI在理解、推理、规划和自主执行行动方面的能力。这种技术进步将为社会提供宝贵的工具,以应对包括药物发现、经济增长和气候变化在内的关键全球挑战。
而这也意味着,我们可以期待数十亿人将从中获得切实的益处。例如:
通过实现更快速、更精准的医疗诊断,它可以革新医疗保健领域;
通过提供个性化的学习体验,它例如,使教育更加普及且更具吸引力;
通过增强信息处理能力,它可以帮助降低创新和创造的门槛;
通过使先进工具和知识的获取更加便捷,它可以让小型组织有能力解决那些以前只有大型、资金充足的机构才能应对的复杂挑战。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
