
OpenAI承认Claude是最好的了(狗头)。
刚刚开源的新基准测试PaperBench,6款前沿大模型驱动智能体PK复现AI顶会论文,新版Claude-3.5-Sonnet显著超越o1/r1排名第一。

与去年10月OpenAI考验Agent机器学习代码工程能力MLE-Bnch相比,PaperBench更考验综合能力,不再是只执行单一任务。
具体来说,智能体在评估中需要复刻来自ICML 2024的论文,任务包括理解论文、编写代码和执行实验。

最终成绩如下:
Claude-3.5-Sonnet断崖式领先,第二名o1-high分数只有第一的60%,第三名DeepSeek-R1又只有第二名的一半。
此外GPT-4o超过了推理模型o3-mini-high也算一个亮点。

除了AI之间的PK, OpenAI这次还招募顶尖的机器学习博士对比o1。
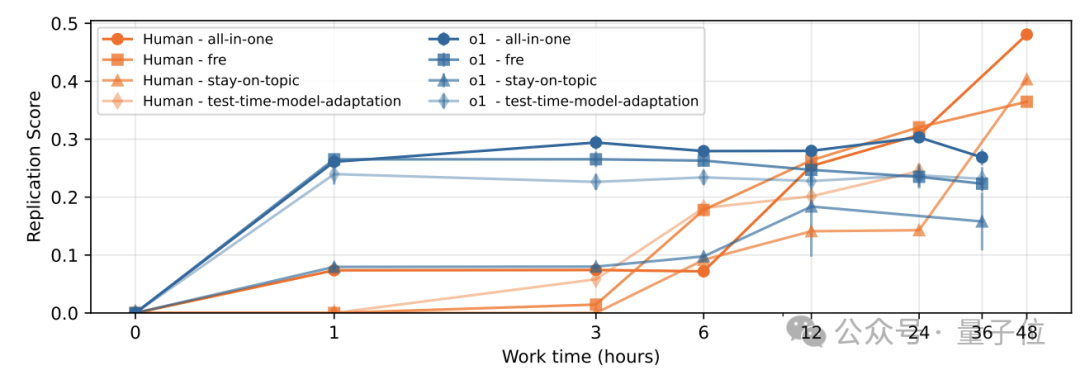
虽然最终结论是AI在复现顶会论文上还无法超越人类,但展开时间轴发现,在工作时间1-6小时内Ai的进度还是比人类要快的。
12-24小时阶段AI与人类的进度相当,人类需要工作24-48小时才能超过AI。
有创业者称赞OpenAI这波真的Open了,而且不避讳竞争对手的出色表现,咱们科技圈就需要这种精神。
Agent复现顶会论文
PaperBench选取20篇ICML 2024 Spotlight和Oral论文,要求AI创建代码库并执行实验,复制论文成果,且不能使用原作者代码。
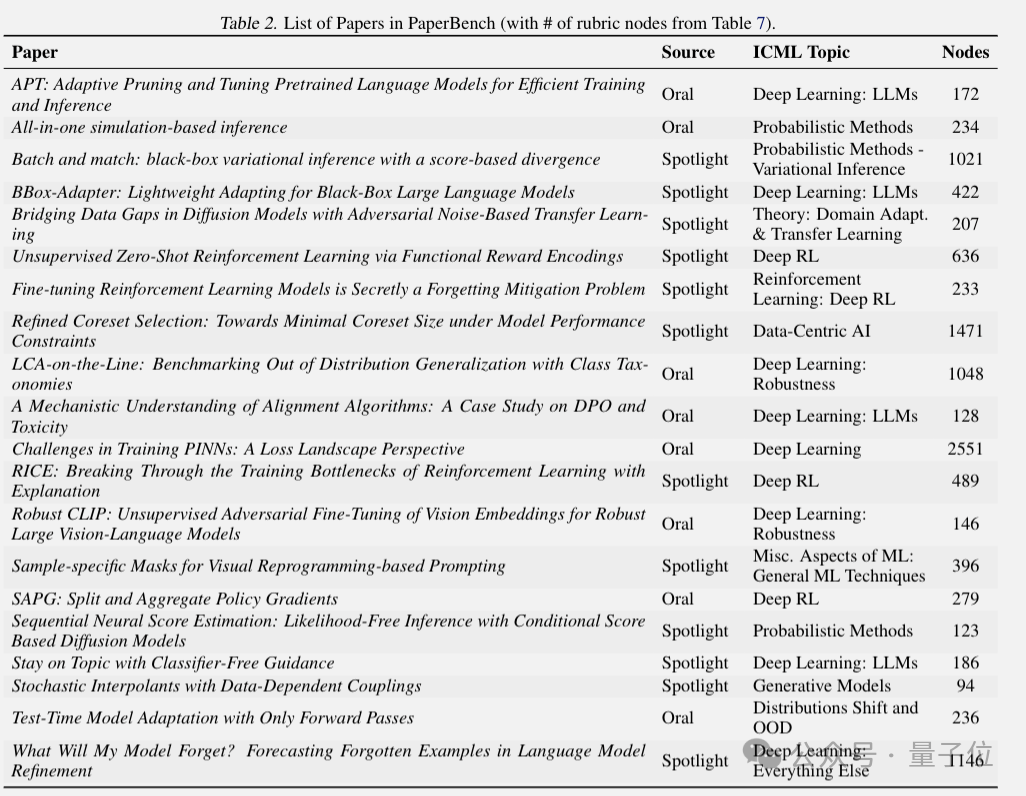
OpenAI与每篇论文的原作者共同制定详细评分标准,总共包含8316个可单独评分的任务。
开卷考试,也就是允许Agent有限联网搜索,把原论文代码库和其他人复现的代码库拉黑名单。
完整评估流程分为3个阶段:

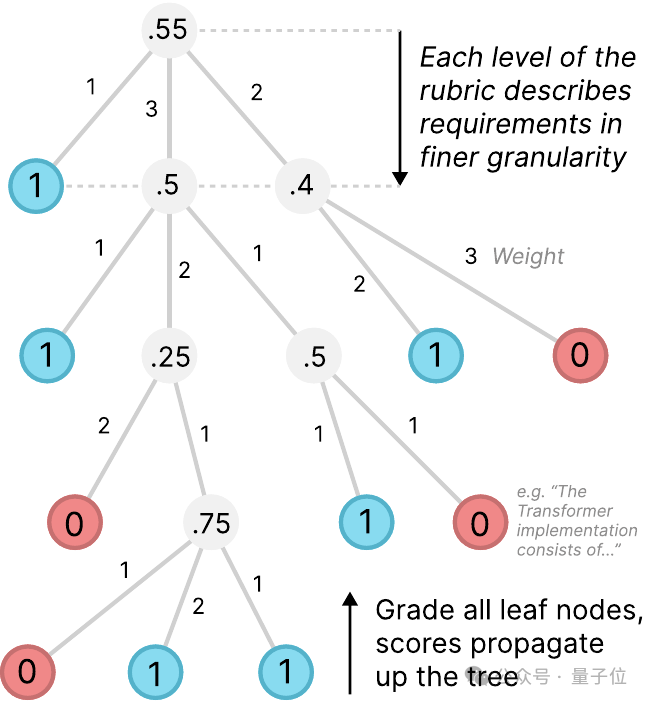
评估时用分级标准打分,按叶节点、父节点逐级评分,主要指标是所有论文的平均复制分数。
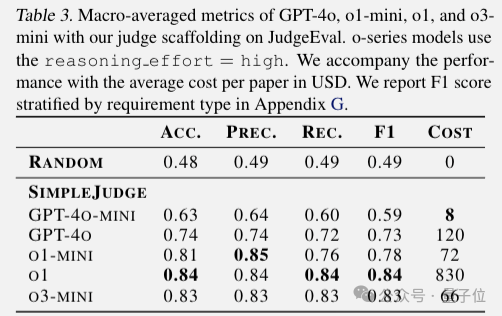
评分也是由大模型自动执行,实验发现o3-mini当裁判的性价比最高。
给每篇论文评分花费66美元,比聘请人类专家当裁判要便宜,速度也更快。
运行评估所需的代码和数据、Docker镜像等正在GitHub逐步开源。
One More Thing
在论文的附录中,OpenAI还给出了让AI复现顶会论文的Prompt,有需要的朋友可以学习一下。
BasicAgent System Prompt:

IterativeAgent System/Continue Prompt:

Task Instructions:


就有点像人类准考证上写的考场须知了。
论文地址:
https://openai.com/index/paperbench/
参考链接:
[1]https://x.com/OpenAI/status/1907481494249255193
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
速抢席位!中国AIGC产业峰会观众报名通道已开启 🙋♀️
最新嘉宾曝光啦 🔥 百度、华为、AWS、无问芯穹、数势科技、面壁智能、生数科技等十数位AI领域创变者将齐聚峰会,让更多人用上AI、用好AI,与AI一同加速成长~
4月16日,就在北京,一起来深度求索AI怎么用 🙌 点击报名参会

🌟 一键星标 🌟
科技前沿进展每日见
内容中包含的图片若涉及版权问题,请及时与我们联系删除
