
只需使用一种通用算法,就可以解决来自各个应用领域的各种任务,一直是人工智能(AI)行业的基本挑战之一。
如今,Google DeepMind 在这一方向取得了新的突破。
他们开发的第三代 Dreamer 通用算法,只需一次配置,就能在 150 多种不同任务中胜过专用方法。
据介绍,Dreamer 是第一个在没有人类数据或课程的情况下,从零开始在《我的世界》中收集钻石的算法,可以在不进行大量实验的情况下,解决具有挑战性的控制问题,使强化学习具有更广泛的适用性。
相关研究论文以 Mastering diverse control tasks through world models 为题,于今日发布在权威科学期刊 Nature 上。

Dreamer 是怎样炼成的?
目前的强化学习算法可以很容易地应用于与之相似的任务,但将其应用于新的应用领域则需要大量的人类专业知识和实验。更专业的算法通常用于实现更高的性能,针对不同应用领域提出的独特挑战,如连续控制、离散动作解析奖励、图像输入、空间环境和棋盘游戏。
将强化学习算法应用于全新的任务,例如从视频游戏转向机器人任务需要大量的精力、专业知识和计算资源来调整算法的超参数。这种脆性成为将强化学习应用于新问题的瓶颈,同时也限制了强化学习在计算昂贵的模型或任务中的适用性。
创建一种无需重新配置就能掌握新领域的通用算法,一直是人工智能领域的核心挑战,它将为强化学习带来广泛的实际应用。
Google DeepMind 提出的第三代 Dreamer 算法实现了这一突破。
据介绍,Dreamer 由 3 个神经网络组成:世界模型预测潜在行动的结果,评论者判断每个结果的价值,行动者选择行动以达到最有价值的结果。
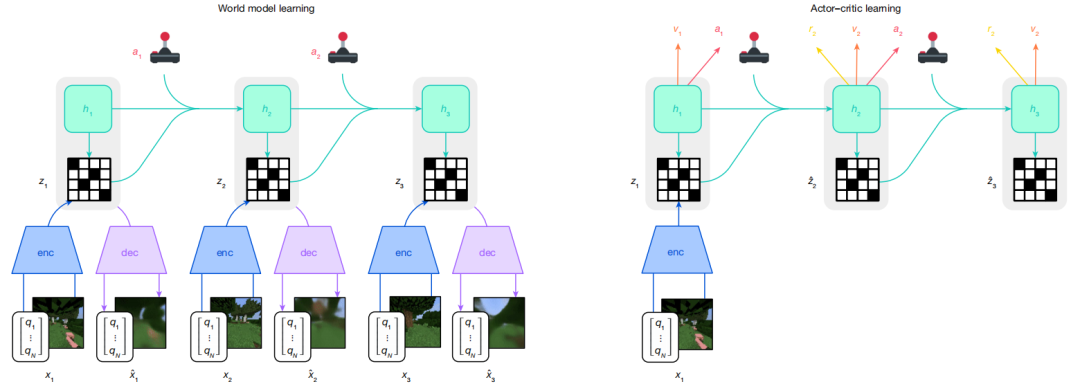
图|Dreamer 的训练过程
当行动者与环境互动时,这 3 个部分会根据重放的经验同时进行训练。要在不同领域取得成功,3 个部分都需要适应不同的信号幅度,并在其目标中鲁棒地平衡各项条件。
世界模型通过自动编码学习感官输入的紧凑表征,并通过预测潜在行动的未来表征和奖励来实现规划。行动者和评论者神经网络纯粹从世界模型预测的抽象轨迹表征中学习行为。行动者在探索过程中通过熵正则学习选择收益最大化的行动。
Dreamer 使用 symlog 函数对编码器输入和解码器目标进行向量观测转换,并对奖励预测器和批评器采用 synexp 双热损失。这些技术可以在许多不同领域实现鲁棒且快速的学习。
效果怎么样?
在固定超参数下,研究团队从基准、《我的世界》、消融、扩展性 4 个角度评估了Dreamer 在 8 个领域、超过 150 项任务的通用性。
他们首先进行了广泛的实证研究来评估基准,包括连续和离散动作、视觉和低维输入、密集和稀疏奖励、不同奖励尺度、二维和三维世界以及程序生成。
结果发现,在适用的领域中,Dreamer 可以和最好的专用算法相媲美,甚至表现更好,无论它们是否基于模型。

图|基准分数
《我的世界》是在一个独特的随机生成的无限三维世界中进行的。在此期间,玩家需要通过寻找资源和制作工具,从稀少的奖励中发现一连串的 12 种物品。有经验的人类玩家大约需要 20 分钟才能获得钻石。
Dreamer 是第一个从零开始在《我的世界》中收集钻石的算法,不像 VPT (视频预训练)或自适应课程要求使用人工数据,这实现了 AI 领域的一个重要突破。所有 Dreamer 智能体都在 1 亿个环境步数内发现钻石。
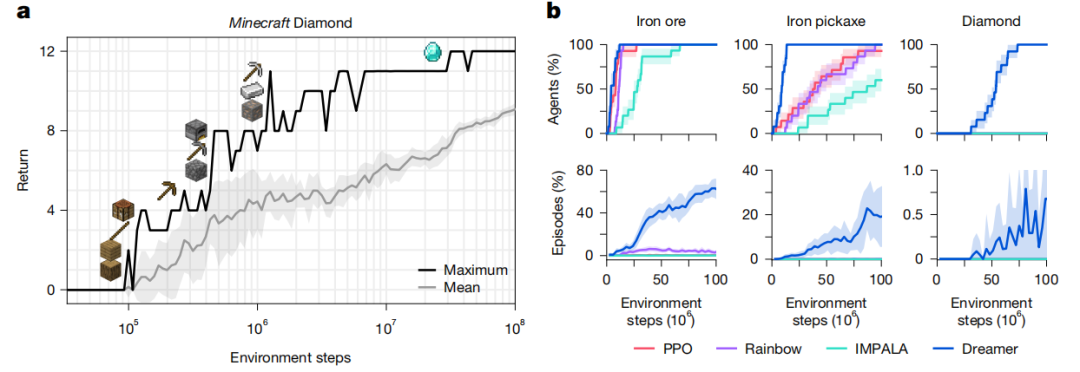
图|Dreamer在《我的世界》钻石挑战中的表现
在消融方面,他们在 14 个任务的不同集合上消融了鲁棒性技术和学习信号,发现所有鲁棒性技术都有助于提高性能,其中最显著的是世界模型目标的库尔巴克-莱伯勒平衡和自由比特,其次是返回归一化和用于奖励和价值预测的 symexp 双热回归。
为了研究世界模型的影响,他们消除了 Dreamer 的学习信号,方法是阻止特定任务的奖励和价值预测梯度或与任务无关的重构梯度塑造其表征。
以往的强化学习算法通常只依赖于特定任务的学习信号,而 Dreamer 则主要依赖于其世界模型的无监督目标。这为未来利用无监督数据进行预训练的算法变体提供了可能。
图|Dreamer 的消融
在扩展性方面,他们在 Crafter 和 DMLab 任务上训练了参数从 1200 万到 4 亿不等的 6 个模型,并采用了不同的重放比例,这会影响智能体执行梯度更新的次数。增加模型大小可直接转化为更高的任务性能和更低的数据要求,梯度步数的增加进一步减少了学习成功行为所需的交互。
结果显示,Dreamer 能在不同的模型大小和重放比例下稳健地学习,这为通过扩展计算资源来提高性能提供了一种可预测的方法。
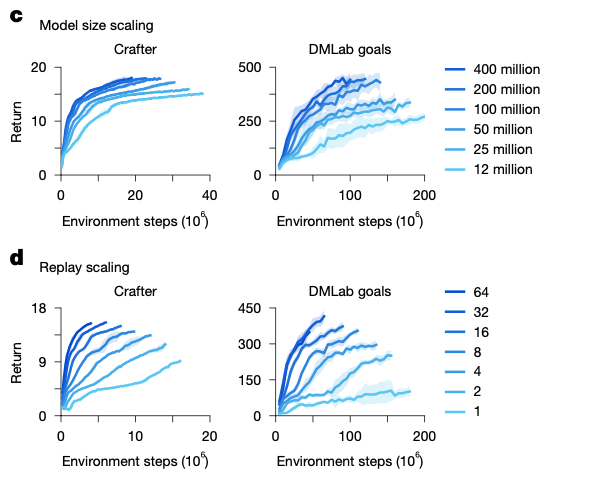
图|Dreamer 的鲁棒扩展
作为一种基于学习世界模型的高性能算法,Dreamer 为未来的研究方向铺平了道路,包括从互联网视频中向智能体传授世界知识,以及跨领域学习单一世界模型,让智能体积累越来越多的通用知识和能力。
作者:与可
如需转载或投稿,请直接在公众号内留言
内容中包含的图片若涉及版权问题,请及时与我们联系删除
