
Published on April 3, 2025 10:23 PM GMT
One downside of an English chain-of-thought, is that each token contains only bits of information, creating a tight information bottleneck.
Don't take my word for it, look at this section from a story by Daniel Kokotajlo, Thomas Larsen, elifland, Scott Alexander, Jonas V, romeo:
[...] One such breakthrough is augmenting the AI’s text-based scratchpad (chain of thought) with a higher-bandwidth thought process (neuralese recurrence and memory). [...]
Neuralese recurrence and memory
Neuralese recurrence and memory allows AI models to reason for a longer time without having to write down those thoughts as text.
Imagine being a human with short-term memory loss, such that you need to constantly write down your thoughts on paper so that in a few minutes you know what’s going on. Slowly and painfully you could make progress at solving math problems, writing code, etc., but it would be much easier if you could directly remember your thoughts without having to write them down and then read them. This is what neuralese recurrence and memory bring to AI models.
In more technical terms:
Traditional attention mechanisms allow later forward passes in a model to see intermediate activations of the model for previous tokens. However, the only information that they can pass backwards (from later layers to earlier layers) is through tokens. This means that if a traditional large language model (LLM, e.g. the GPT series of models) wants to do any chain of reasoning that takes more serial operations than the number of layers in the model, the model is forced to put information in tokens which it can then pass back into itself. But this is hugely limiting—the tokens can only store a tiny amount of information. Suppose that an LLM has a vocab size of ~100,000, then each token contains
bits of information, around the size of a single floating point number (assuming training in FP16). Meanwhile, residual streams—used to pass information between layers in an LLM—contain thousands of floating point numbers.
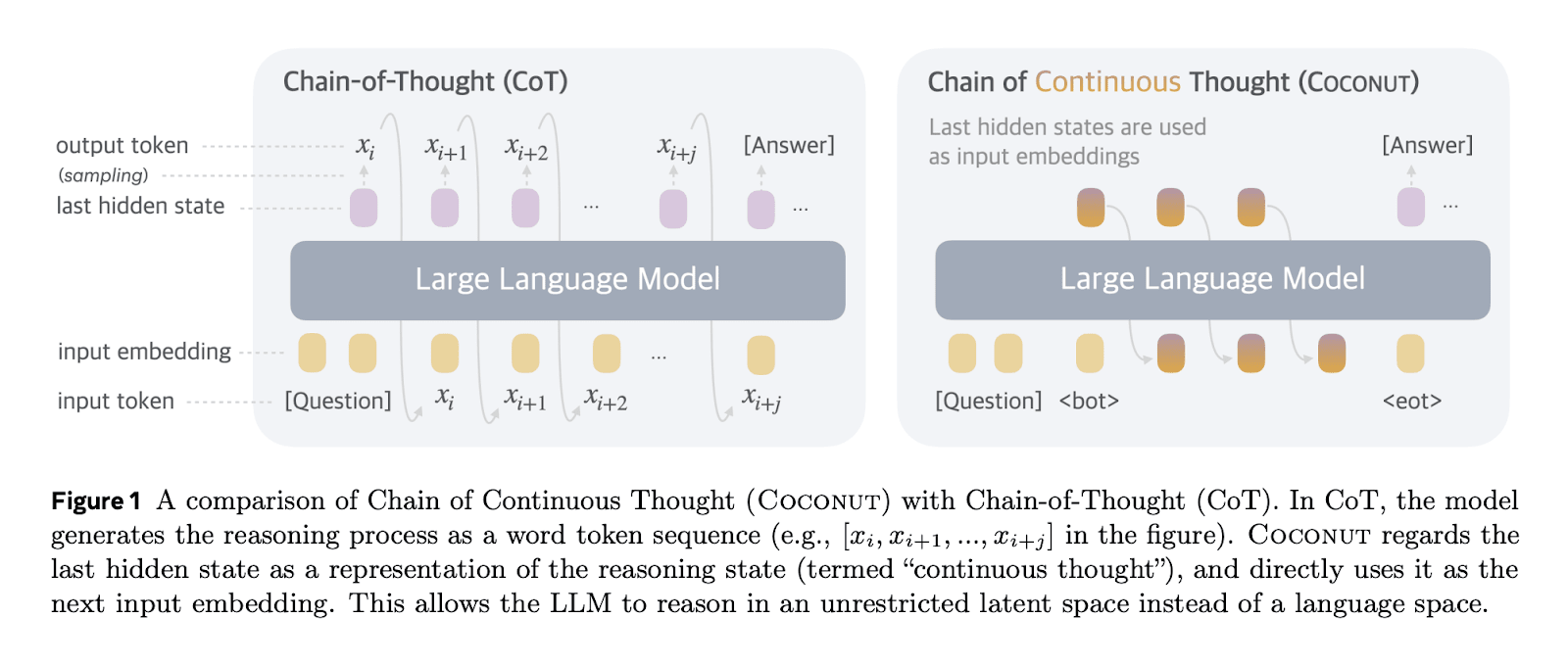
One can avoid this bottleneck by using neuralese: passing an LLM’s residual stream (which consists of several-thousand-dimensional vectors) back to the early layers of the model, giving it a high-dimensional chain of thought, potentially transmitting over 1,000 times more information.
Figure from Hao et al., a 2024 paper from Meta implementing this idea.
We call this “neuralese” because unlike English words, these high-dimensional vectors are likely quite difficult for humans to interpret. In the past, researchers could get a good idea what LLMs were thinking simply by reading its chain of thought. Now researchers have to ask the model to translate and summarize its thoughts or puzzle over the neuralese with their limited interpretability tools.
Similarly, older AI chatbots and agents had external text-based memory banks, like a human taking notes on paper. The new AI’s long-term memory is a bundle of vectors instead of text, making its thoughts more compressed and higher-dimensional. There are several types of memory banks; some are used temporarily for single tasks that involve multiple steps, others are shared between all agents used by a person, company, or job type (e.g. programming).
To our knowledge, leading AI companies such as Meta, Google DeepMind, OpenAI, and Anthropic have not yet actually implemented this idea in their frontier models. Our guess is that this is because the performance gain is small relative to training inefficiencies introduced. The training inefficiencies stem from not being able to predict many tokens in parallel, leading to worse GPU utilization. Without the neuralese, the model can predict all of the sentence “This is an example” at the same time, since it already knows that the input for generating the “is” will be “This”, the input for “an” will be “This is”, etc. However, with the neuralese it’s unknown what the neuralese vector will be to pass through to the next token after “This” has been generated. Therefore each token has to be predicted one at a time. The inability to predict all of the tokens in parallel reduces the efficiency of LLM training. However, we are forecasting that by April 2027 research has both decreased the efficiency loss and increased the performance gain from neuralese.
If this doesn’t happen, other things may still have happened that end up functionally similar for our story. For example, perhaps models will be trained to think in artificial languages that are more efficient than natural language but difficult for humans to interpret. Or perhaps it will become standard practice to train the English chains of thought to look nice, such that AIs become adept at subtly communicating with each other in messages that look benign to monitors.
That said, it’s also possible that the AIs that first automate AI R&D will still be thinking in mostly-faithful English chains of thought. If so, that’ll make misalignments much easier to notice, and overall our story would be importantly different and more optimistic.

Each forward pass of the transformer, may compute 1000 times more information than one token. But all of that information is "deleted" from the point of view of the next forward pass (and the forward pass afterwards), the only information kept is a single token, or bits of information.
A lot of information is stored by KV Caching, but that doesn't change the story.[1]
Neuralese recurrence gets around the information bottleneck, by letting the AI access the raw thoughts it had in previous computations, without collapsing each thought into a single token.
If the AI can access all the bits from its previous computations, there may be much fewer wasted computations. This assumes that more than of those bits computed become useful, which is plausible given that reinforcement learning might improve their usefulness over time. This also assumes the AI can keep the faster growing context window organized.
Avoiding neuralese
Letting the AI use all the bits without collapsing them into an English token, may avoid the information bottleneck and improve efficiency, but it is terrifying from the point of view of interpretable chains-of-thought and scalable oversight.
We won't be able to read what the AI is thinking in plain English anymore.

So surely, there has to be some way to at least reduce the bottleneck, without converting the chain-of-thought into an utterly alien language?
Here is one idea:
- Inside the AI's chain-of-thought, each forward pass can generate many English tokens instead of one, allowing more information to pass through the bottleneck.After the chain-of-thought ends, and the AI is giving its final answer, it generates only one English token at a time, to make each token higher quality. The architecture might still generate many tokens in one forward pass, but a simple filter repeatedly deletes everything except its first token from the context window.
- This slower thinking might occur not just for the final answer, but when the AI is cleaning up its chain of thought with concise summaries (e.g. ClaudePlaysPokemon has long chains of thought when simply entering and leaving a room, filling up its context window with useless information. They gave it a separate memory file where it can write and delete more important information).Reinforcement learning will naturally teach the AI to prioritize the first token more during this slower thinking.
Admittedly, even this method would reduce interpretability by making the chain of thought longer. This trade-off is more inevitable. But the trade-off where the AI has to learn some non-English alien language seems unnecessary.
Disclaimer: I have no formal computer science education.
- ^
Transformers aren't allowed to think about information saved in their KV Caches. Transformer have the exact same thoughts they would have had without KV Caches, only faster.
Discuss
